
Quick Answer: ADAS Validation And Automotive AI Quality Control
ADAS validation and automotive AI quality control should prove that a model-assisted system can make safe, traceable, and useful decisions inside its real operating domain. The work is broader than model accuracy. A credible validation program covers sensor quality, dataset coverage, labels, scenario slices, simulation and replay, hardware-in-the-loop checks, latency, human review, release gates, monitoring, rollback, and corrective-action loops.
The practical question for automotive leaders is: can this workflow make a safer, more auditable decision under the exact conditions where a vehicle, plant, camera station, or connected platform will operate? NextPage treats that as production automotive software development services plus computer vision development services, QA automation, cloud integration, dashboarding, and post-launch monitoring.
The best first release is usually not broad autonomy. It is a supervised validation loop for one ADAS feature, one inspection station, one defect taxonomy, or one connected-vehicle feedback workflow with clear evidence, ownership, and expansion criteria.
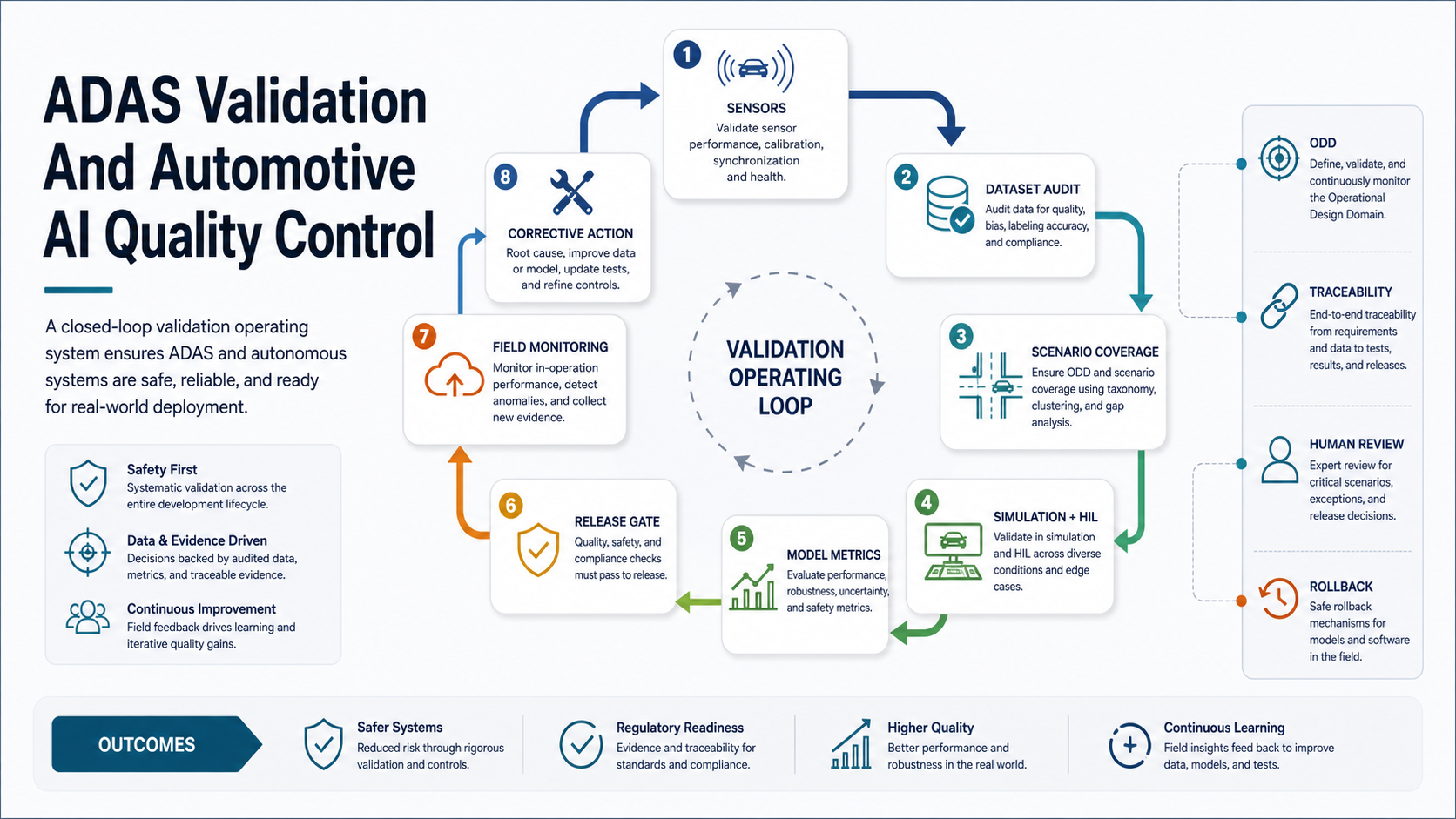
Why Automotive AI Needs A Safety Evidence Model
Normal software QA verifies permissions, workflows, APIs, screens, integrations, and regressions. Automotive AI adds a harder layer because the system interprets uncertain physical-world signals. A camera may face glare, rain, occlusion, lens dirt, vibration, unusual lane markings, worn parts, reflective surfaces, or rare defect patterns. A model can look strong in aggregate while failing the specific slice that matters most.
That is why automotive AI quality control should be evidence-led. Teams need to know whether the dataset represents target conditions, whether labels are consistent, whether model behavior is stable by scenario, whether latency is acceptable on target hardware, whether uncertainty routes to the right human review path, and whether post-launch monitoring catches drift.
The same principle applies in factories. The NextPage guide to AI in manufacturing use cases explains why visual inspection, predictive maintenance, and production analytics depend on data quality, ERP/MES context, and workflow integration rather than model output alone.
Standards And Guidance To Translate Into Evidence
Validation teams should not turn standards into paperwork after the system is built. Use them as a source of evidence requirements. NHTSA ADS guidance and the Voluntary Safety Self-Assessment pattern push teams to describe how safety is addressed. SAE J3016 helps teams clarify the role of the driver, driving automation system, and fallback responsibility by automation level. ISO 21448 SOTIF highlights hazards caused by performance limitations or insufficient specification of intended functionality. NIST AI RMF gives a useful operating vocabulary: govern, map, measure, and manage AI risk across the lifecycle.
| Reference | How To Use It In Validation | Evidence Output |
|---|---|---|
| NHTSA ADS and VSSA guidance | Map how the program addresses safety, data, testing, fallback, cybersecurity, human-machine interface, and post-launch learning. | Safety case summary, evidence index, and public or internal assessment structure |
| SAE J3016 | Clarify automation level, dynamic driving task, fallback expectation, and human responsibility. | ODD definition, role model, driver handoff assumptions, and feature boundary |
| ISO 21448 SOTIF | Identify risk caused by intended-function limitations, sensor perception limits, and foreseeable misuse. | Known hazardous scenarios, unknown scenario discovery plan, validation coverage, and monitoring triggers |
| NIST AI RMF | Organize governance, risk mapping, measurement, and mitigation into an operating cadence. | Risk register, KPI set, release-gate criteria, ownership map, and improvement backlog |
For regulated or safety-sensitive AI programs, the NextPage AI governance for critical infrastructure software checklist is a useful companion because it translates AI risk management into delivery controls, audit trails, and release decisions.
The Automotive AI Validation Evidence Map
Start by defining which evidence must exist before a model, workflow, or release can be trusted. Evidence should connect engineering metrics to operational decisions: promote, hold, rollback, retrain, route to manual review, narrow the operating domain, or redesign the workflow.
| Validation Layer | Evidence To Collect | Release Question |
|---|---|---|
| Operating domain | Road type, speed range, weather, lighting, camera station, part variant, plant context, geographic or fleet scope | Do we know where the system is intended to work and where it should not be used? |
| Data quality | Source coverage, label consistency, class balance, missing cases, sensor metadata, defect taxonomy | Does the validation set represent the real operating domain? |
| Model behavior | Precision, recall, false positives, false negatives, confidence bands, scenario performance, robustness checks | Does the model fail in known, bounded, and acceptable ways? |
| System integration | Latency, throughput, hardware limits, API reliability, failover behavior, audit logs, role-based review | Can the model operate inside the production workflow? |
| Human review | Escalation rules, override reasons, reviewer agreement, traceability, sampling plans | Can uncertain or high-risk decisions be reviewed consistently? |
| Monitoring | Data drift, model drift, device health, field incidents, defect escape rate, retraining triggers | Will the team detect degradation after launch? |
For computer vision programs, evidence planning also protects budget. Dataset creation, edge-case discovery, labeling, evaluation, workflow integration, monitoring, and iteration often cost more than the first model. The NextPage computer vision development cost roadmap is useful when scoping the validation effort.
ADAS Scenario Validation Workflow
ADAS perception validation should be organized around the operating design domain. Define the conditions where the feature is intended to work: road type, speed range, weather, lighting, geography, lane markings, traffic density, sensor set, and driver interaction model. Then create scenario families that test expected, stressful, and rare conditions.

- Scenario inventory: convert safety, product, and engineering assumptions into scenario families such as cut-ins, pedestrians, poor lane markings, construction zones, glare, occlusion, sensor degradation, and driver handoff.
- Dataset and label audit: check coverage, label guidelines, annotator agreement, class imbalance, timestamp alignment, and sensor calibration metadata.
- Offline evaluation: test model behavior across scenario slices instead of relying only on global metrics.
- Simulation and replay: replay difficult events and synthetic scenarios before road or fleet exposure.
- Hardware-in-the-loop checks: validate latency, compute headroom, failover behavior, and sensor input handling on target hardware.
- Field pilot: run limited deployments with safety limits, telemetry capture, human review, and rollback criteria.
ADAS validation also intersects with connected-vehicle platforms. If the vehicle sends telemetry, diagnostic events, model confidence, or operational status to cloud services, architecture must support traceability. The NextPage connected vehicle platform architecture guide covers telemetry, OTA, cloud, and dashboard patterns that support validation feedback loops.
Automotive Visual Inspection Quality Control
Manufacturing visual inspection has different stakes from road-facing ADAS, but the validation discipline is similar. The model must distinguish acceptable variation from defects, keep false rejects under control, detect critical defects early, and give quality teams evidence they can audit.
Start with a defect taxonomy. Define defect names, severity levels, acceptable thresholds, image-capture standards, lighting requirements, camera positions, part variants, and review rules. Without this taxonomy, labels drift and model metrics become hard to trust. The supporting NextPage AI visual inspection data labeling guide goes deeper on taxonomy ownership, image sampling, reviewer agreement, and monitoring datasets.
| Inspection Area | Validation Focus | Typical Failure Mode |
|---|---|---|
| Image capture | Lighting, focus, angle, resolution, fixture repeatability | Model misses defects because capture conditions changed |
| Labels | Defect taxonomy, annotator agreement, severity rules | Training data mixes cosmetic variation with actual defects |
| Thresholds | Precision/recall by defect type and severity | Too many false rejects slow the line, or false accepts escape QA |
| Workflow | Human review, sampling, override reasons, traceability | Quality teams cannot explain why a part was accepted or rejected |
| Monitoring | Camera health, drift, retraining triggers, defect escape rate | Model performance degrades after a supplier, material, or line change |
Manufacturing teams should decide early whether inference belongs near the line or in the cloud. For latency-sensitive inspection, the tradeoffs in edge AI vs cloud computer vision are directly relevant: bandwidth, latency, privacy, device management, model updates, and monitoring all affect validation design. Teams that need a production inspection workflow can also review NextPage computer vision quality inspection for manufacturing.
Edge, Cloud, And Vehicle Integration Checks
Automotive AI often runs across multiple environments: training infrastructure, validation workbenches, edge gateways, vehicle ECUs, plant devices, cloud dashboards, and data warehouses. A model can pass offline evaluation but fail in production because latency, device health, camera configuration, network reliability, update policy, or integration contracts were not tested.

- Latency budgets: end-to-end timing from sensor or image capture to decision, alert, or workflow action.
- Throughput and backpressure: how the system behaves when image volume, telemetry, or queue depth spikes.
- Fallback behavior: safe states, manual review, retry logic, and degraded-mode operation.
- Version traceability: model version, dataset version, rules version, device firmware, and deployment history.
- Security and access controls: who can view images, override decisions, deploy models, change thresholds, or export evidence.
- OTA and update controls: staged rollout, rollback, compatibility checks, and field diagnostics.
When AI components are updated remotely, validation should align with the operational model for OTA updates and remote diagnostics. Release gates should include not only model metrics but deployment safety, rollback speed, and support readiness.
Release Gates, KPIs, And Decision Rights
A release gate turns validation evidence into a decision. The gate should be explicit enough that engineering, QA, product, safety, manufacturing, security, and support teams understand what must be true before expanding a pilot or rollout.
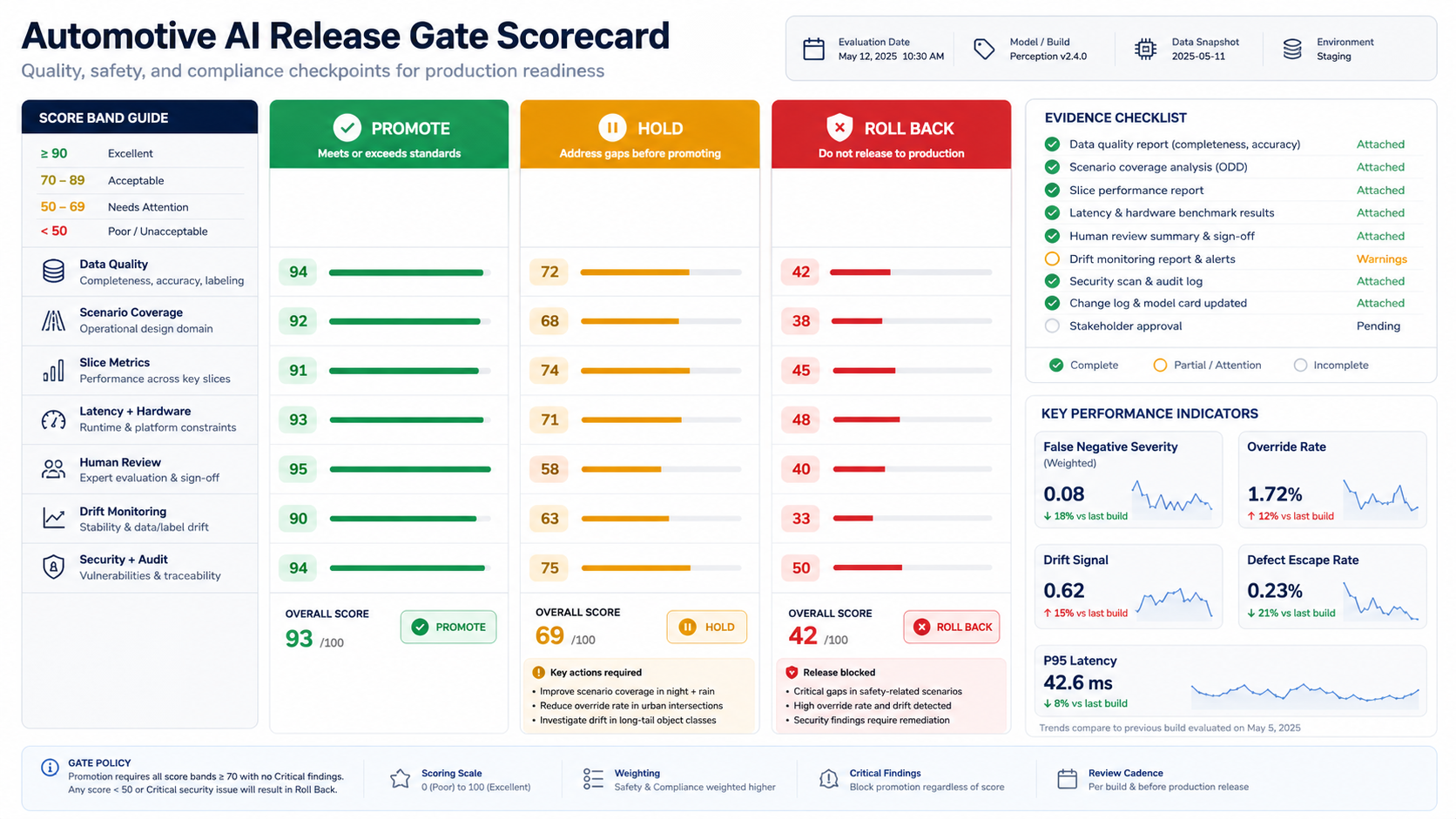
| KPI | What It Shows | How To Use It |
|---|---|---|
| Scenario coverage | Whether expected and risky operating conditions are represented | Block release when critical scenario families are missing |
| Precision and recall by slice | Whether performance holds across defect types, weather, lighting, part variants, or road scenarios | Set different thresholds for safety-critical and low-risk decisions |
| False negative severity | Whether missed detections create unacceptable operational risk | Route high-severity uncertainty to human review |
| Latency and compute headroom | Whether the system meets timing requirements on target hardware | Prevent rollout when inference blocks operational timing |
| Override and review rate | Whether humans trust the workflow and when they disagree | Find label gaps, threshold issues, or workflow confusion |
| Drift and field incidents | Whether production data is moving away from validation assumptions | Trigger retraining, threshold review, or pilot narrowing |
For model operations, borrow from the MLOps implementation checklist: data contracts, model registry, deployment controls, monitoring, governance, and improvement cadence become mandatory once AI influences production workflows. The release gate should also sit beside normal product QA. NextPage QA automation testing services can help teams keep APIs, dashboards, review queues, permissions, and regression paths stable while the model evolves.
A Practical 90-Day Pilot Roadmap
Do not start with a broad validate-all-automotive-AI program. Start with one bounded workflow: one ADAS perception feature, one manufacturing defect class, one camera station, one telemetry-assisted diagnostic workflow, or one model-assisted quality review queue.
| Phase | Focus | Deliverable |
|---|---|---|
| Weeks 1-2 | Scope and evidence plan | Operating domain, scenario list, defect taxonomy, baseline KPIs, source-system map |
| Weeks 3-5 | Dataset and evaluation setup | Label audit, validation set, slice metrics, review workflow, initial dashboard |
| Weeks 6-8 | Integration and supervised pilot | Edge/cloud deployment checks, latency report, human review queue, rollback criteria |
| Weeks 9-12 | Release decision and monitoring | Gate review, monitoring plan, retraining triggers, support handoff, expansion backlog |
Use a normal software quality layer around the AI workflow. Regression coverage still matters for dashboards, APIs, permissions, data exports, review queues, and deployment workflows. The NextPage regression testing checklist is useful for keeping the non-model parts of the product stable while model validation evolves.
Monitoring, Drift, And Continuous Improvement
Automotive AI validation does not end at release. Field data, plant changes, supplier changes, camera changes, road conditions, and user behavior can move away from the validation assumptions. Define monitoring before launch so the team knows what signal requires a threshold review, retraining, rollback, or narrower operating domain.
- Data drift: changes in input images, sensors, routes, lighting, weather, part mix, materials, or camera configuration.
- Model drift: performance degradation by scenario, defect type, hardware version, or deployment region.
- Operational drift: rising override rate, reviewer disagreement, device health issues, alert fatigue, or support escalations.
- Governance drift: release gates skipped, evidence not updated, ownership unclear, or audit trails incomplete.
When teams want to evaluate automation value, tools can help frame the first business case. Use the AI Automation ROI Calculator to estimate repeated review or inspection work, and use the AI Agent Readiness Assessment when a workflow may eventually route decisions through supervised agents or copilots.
Common Risks And Controls
Most automotive AI validation problems are not caused by a single bad metric. They come from weak assumptions that were not made visible early enough.
- Aggregate accuracy hides risk: report performance by scenario, defect type, part family, lighting, weather, route, and device.
- Labels drift over time: maintain labeling guidelines, reviewer agreement checks, and taxonomy ownership.
- Edge hardware changes behavior: test on target hardware with real latency, thermal, bandwidth, and failure conditions.
- Humans cannot audit decisions: store input evidence, model version, rule version, reviewer action, and override reason.
- Monitoring starts too late: define drift, field incident, and device-health signals before launch.
- Release pressure overrides evidence: use written gates and rollback criteria that product, QA, and engineering sign off on.
The control is not to slow every AI release indefinitely. The control is to make assumptions measurable, route uncertainty to the right human workflow, and keep the validation loop alive after deployment.
How NextPage Helps Automotive AI Teams
NextPage helps automotive and manufacturing teams scope, build, validate, and operate AI-assisted quality workflows. We can help define the validation evidence plan, design defect taxonomies, set up data and labeling workflows, build review dashboards, integrate edge or cloud inference, create release gates, and monitor production behavior.
Our custom software development work covers the platform around the model: data pipelines, QA dashboards, human review queues, role-based access, audit trails, APIs, deployment workflows, reporting, and support tooling. Review the NextPage software and AI portfolio to see how we structure production-ready workflow platforms, dashboards, automation, and internal tools. If your team is preparing an ADAS, computer vision, or automotive quality automation pilot, start with a validation roadmap before expanding the model.
Book an automotive AI validation consultation with NextPage.