
Quick Answer: What Agentic AI Infrastructure Readiness Means
Agentic AI infrastructure readiness means your cloud platforms, operational data, APIs, observability, permissions, governance, and cost controls are mature enough for AI agents to act safely inside real workflows. It is not only model access, GPU capacity, or a new orchestration framework. It is the operating foundation that lets an agent read trusted context, call approved tools, leave evidence, control spend, and stop before it creates production risk.
For CTOs, the readiness test is practical: can an agent inspect the right system records, select an allowed action, run it through policy, log every step, stay inside budget, and escalate when judgment is required? If that answer is unclear, broad autonomy should wait. Start with one governed workflow, prove the control model, then reuse the same infrastructure pattern for higher-value workflows.
The best first use cases are high-volume and reviewable: service desk triage, incident investigation, access request support, cloud cost review, environment provisioning, release-change analysis, or runbook recommendations. The wrong starting point is a vague enterprise agent with write access across production systems.
Why Infrastructure Readiness Now Matters
Agentic AI changes the role of infrastructure. Traditional automation usually follows a narrow path. Agentic systems can plan steps, call tools, coordinate with other agents, inspect changing state, and adapt based on results. That creates leverage, but it also increases the blast radius of weak data, unclear permissions, noisy monitoring, and unmanaged cloud spend.
The McKinsey infrastructure analysis published on April 23, 2026 frames agentic AI as an infrastructure and operating-model shift rather than a model-only initiative. The core pressure is familiar to engineering leaders: more throughput, more non-labor technology cost, more outage risk, and more lifecycle complexity as agents coordinate work across systems.
Implementation teams see the same pattern. The blocker is rarely only the model. The blocker is the surrounding estate: fragmented operational records, manual ticket flows, unclear service ownership, APIs that were never designed for safe automation, observability that stops at dashboards, and cost reporting that arrives after the spend has already happened.
The Readiness Gate Before Autonomy
A useful readiness review should decide the maximum autonomy level a workflow can support today. Treat autonomy as a ladder, not a switch.
| Autonomy Level | What The Agent Can Do | Infrastructure Evidence Required |
|---|---|---|
| Recommend | Read context and draft next actions for a human. | Trusted sources, retrieval boundaries, evaluation samples, and review workflow. |
| Prepare | Create tickets, pull requests, scripts, or change plans without execution. | Identity, versioning, diff review, policy checks, and rollback plan. |
| Execute With Approval | Run approved actions after a human confirms the specific change. | Tool permissions, audit logs, approval records, observability, and failure handling. |
| Constrained Autonomy | Execute low-risk actions inside strict policies and budgets. | Runtime isolation, rate limits, budget caps, runbook tests, alerts, and owner sign-off. |
| Broad Autonomy | Coordinate multiple systems with minimal human intervention. | Proven control history, incident response, lifecycle ownership, cost attribution, and executive risk acceptance. |
Most organizations should start at recommend, prepare, or execute-with-approval. Constrained autonomy is reasonable only when the workflow has strong data quality, deterministic tools, narrow permissions, traceable execution, and a clear owner. Broad autonomy belongs after months of evidence, not in the first pilot.
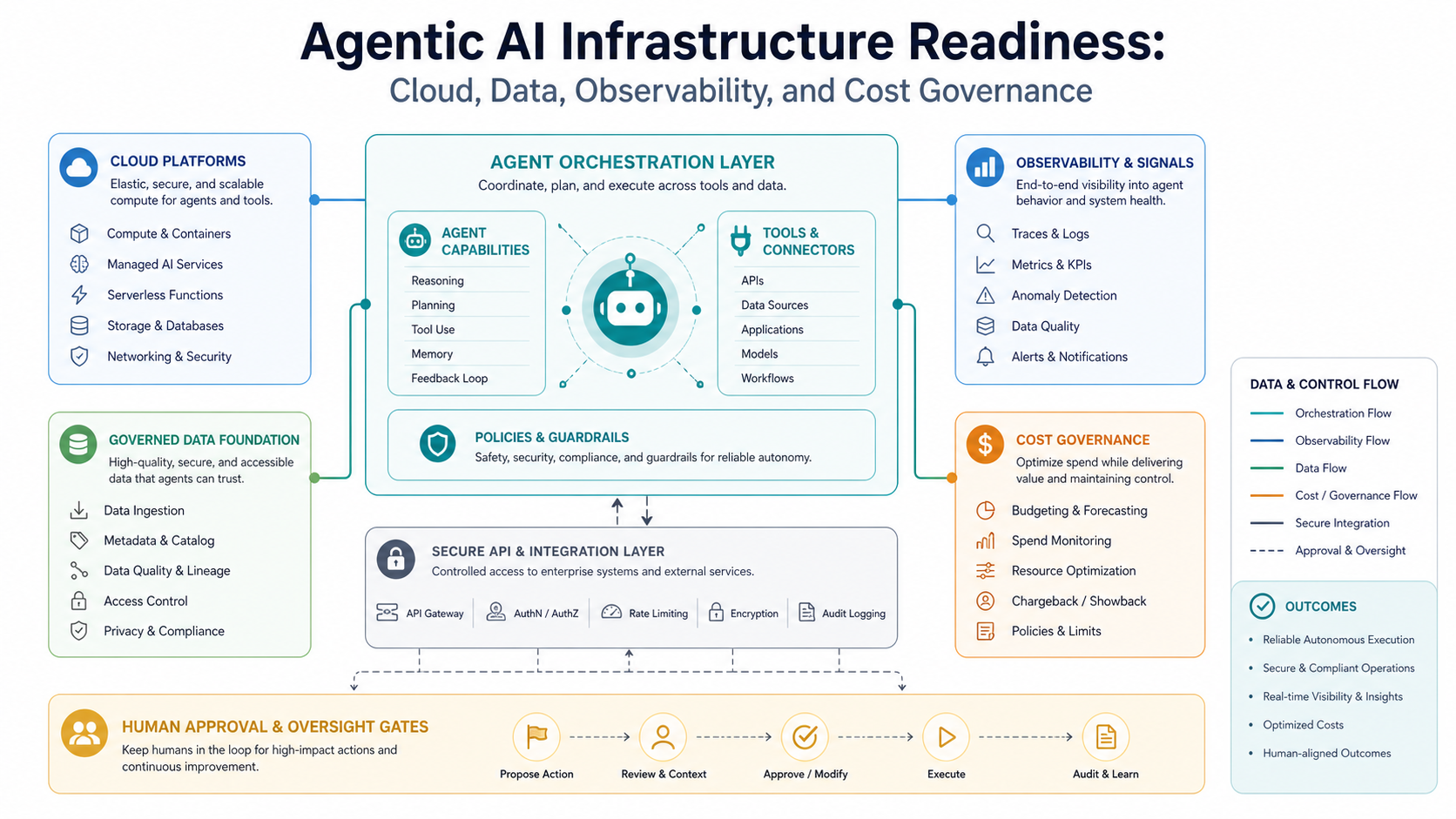
The Seven Readiness Layers For Agentic AI
A full readiness review should cover seven layers. First, cloud and runtime architecture: where agents, models, queues, tools, workers, and state stores run. Second, operational data: the asset, ownership, dependency, change, incident, log, metric, cost, and policy data agents need to reason correctly. Third, secure executable actions: APIs, functions, runbooks, and workflows that agents can call with policy checks.
Fourth, identity and permissions: agent identities, user delegation, scopes, break-glass rules, and approval thresholds. Fifth, observability and evidence: traces that show what the agent saw, decided, retrieved, called, changed, and escalated. Sixth, cost governance: inference tracking, tool-call volume, cloud usage attribution, budget alerts, and vendor controls. Seventh, lifecycle ownership: prompt/version management, evaluation sets, release gates, retirement paths, and incident review.
If any layer is weak, agentic AI can still be piloted, but the use case should be narrower. A support agent that drafts recommended actions is lower risk than an agent that changes access rules, restarts production jobs, or modifies infrastructure. Readiness is about matching autonomy to the maturity of the surrounding controls.
Cloud And Runtime Architecture For Agent-Ready Systems
Agentic workloads need a cloud architecture that is modular, observable, and easy to constrain. That usually means separating orchestration, execution, data access, policy checks, and monitoring instead of letting every agent experiment become a privileged script. Agents should call well-defined tools and APIs, not scrape admin consoles or depend on informal credentials.
A practical cloud migration services plan for agentic AI should answer where agents run, how they access systems, how secrets are managed, how environments are isolated, how approvals are enforced, and how rollback works. For delivery teams, DevOps consulting services also matter because CI/CD, infrastructure as code, environment parity, and deployment gates become part of the agent control plane.
The goal is not to rebuild the entire estate before experimenting. The goal is to create a reliable path for the first agentic workflow, then reuse that path. Shared patterns matter: identity, queueing, retry behavior, policy checks, prompt/version management, deployment gates, and logging should not be reinvented by every team.
Data Foundations Agents Can Trust
Agents are only as useful as the context they can trust. In infrastructure operations, that context often includes configuration management data, service ownership, dependency maps, deployment history, incident records, logs, metrics, runbooks, cloud inventory, cost data, and security policies. If those records conflict, the agent may produce confident but wrong recommendations.
Readiness starts with a narrow source-of-truth review. For the first workflow, identify the exact records the agent needs, who owns them, how fresh they are, which fields are reliable enough for automated decisions, and which fields require human validation. Imperfect data does not prevent progress, but undocumented ambiguity should limit autonomy.
This is where LLM development needs software engineering discipline. Useful agentic systems depend on data contracts, retrieval boundaries, evaluation datasets, failure-mode tests, and audit-friendly records as much as prompt quality.
Secure Tools, Permissions, And Human Gates
Agent-ready infrastructure exposes repeatable actions through secure APIs or controlled tools. That includes creating a ticket, checking service health, restarting a job, provisioning access, resizing capacity, querying logs, opening a pull request, or triggering a deployment. Each action should have a permission model, input schema, output contract, rate limit, and owner.
The important design decision is not whether an agent can act. It is which actions the agent can take without approval, which actions require human review, and which actions are never allowed. Low-risk read operations may be autonomous. Medium-risk changes may require policy validation. High-impact actions, such as production rollback, customer-facing communication, access changes, or infrastructure deletion, should usually require explicit approval.
For teams building agents into operational workflows, AI agent development should include tool permission design, agent identity, action logs, failure handling, and escalation paths from the start. The secure AI agent development checklist is the supporting control list when the pilot moves from prototype to production.
Observability For Agentic Operations
Traditional monitoring tells teams whether systems are healthy. Agentic observability must also explain how an agent behaved. A production-ready setup should record the input context, retrieved sources, selected tool, approval path, executed action, output, latency, cost, errors, and final user-visible result. Without that trace, teams cannot debug bad decisions or prove that controls were followed.
OpenTelemetry's generative AI conventions now include signals for GenAI operations, model spans, agent spans, metrics, exceptions, and events. Microsoft Foundry's agent tracing guidance makes the operational problem clear: complex agents may have many nested steps, changing sequences, long inputs, and tool calls inside tool calls. Trace results help teams inspect the inputs and outputs at each stage rather than guessing where behavior changed.
For incident workflows, observability should connect agent activity with system telemetry. If an incident triage agent analyzes logs, change history, service topology, and recent deployments, the incident record should show those sources and the reason for the recommended response. When a human approves or rejects an action, that decision should become part of the audit trail.
NextPage's AIOps consulting services are relevant when agents need to work across observability tools, runbooks, incident records, ticketing systems, and cloud operations signals. The supporting AI agent observability checklist gives teams a deeper trace and evaluation checklist.
Cost Governance Before Agent Sprawl
Agentic AI can reduce operational toil, but it can also create new cost patterns. Agents may call models repeatedly, retrieve large context, trigger compute-heavy workflows, duplicate work across teams, or run in loops when goals are poorly constrained. Cloud, storage, observability, inference, and vendor costs can become more granular and less predictable.
Cost governance should be designed before agents scale. At minimum, teams should tag agent workloads, track inference usage, set budget alerts, monitor tool-call volume, measure automation success, and compare spend against business outcomes. Agents that recommend or execute infrastructure changes should understand cost policies, not just technical feasibility.
When cloud cost and reliability are already weak, start with cloud performance optimization services before adding autonomous remediation. Use the custom software cost estimator to scope the surrounding platform work, integrations, QA, and governance needed for production.
Agent Autonomy Readiness Scorecard
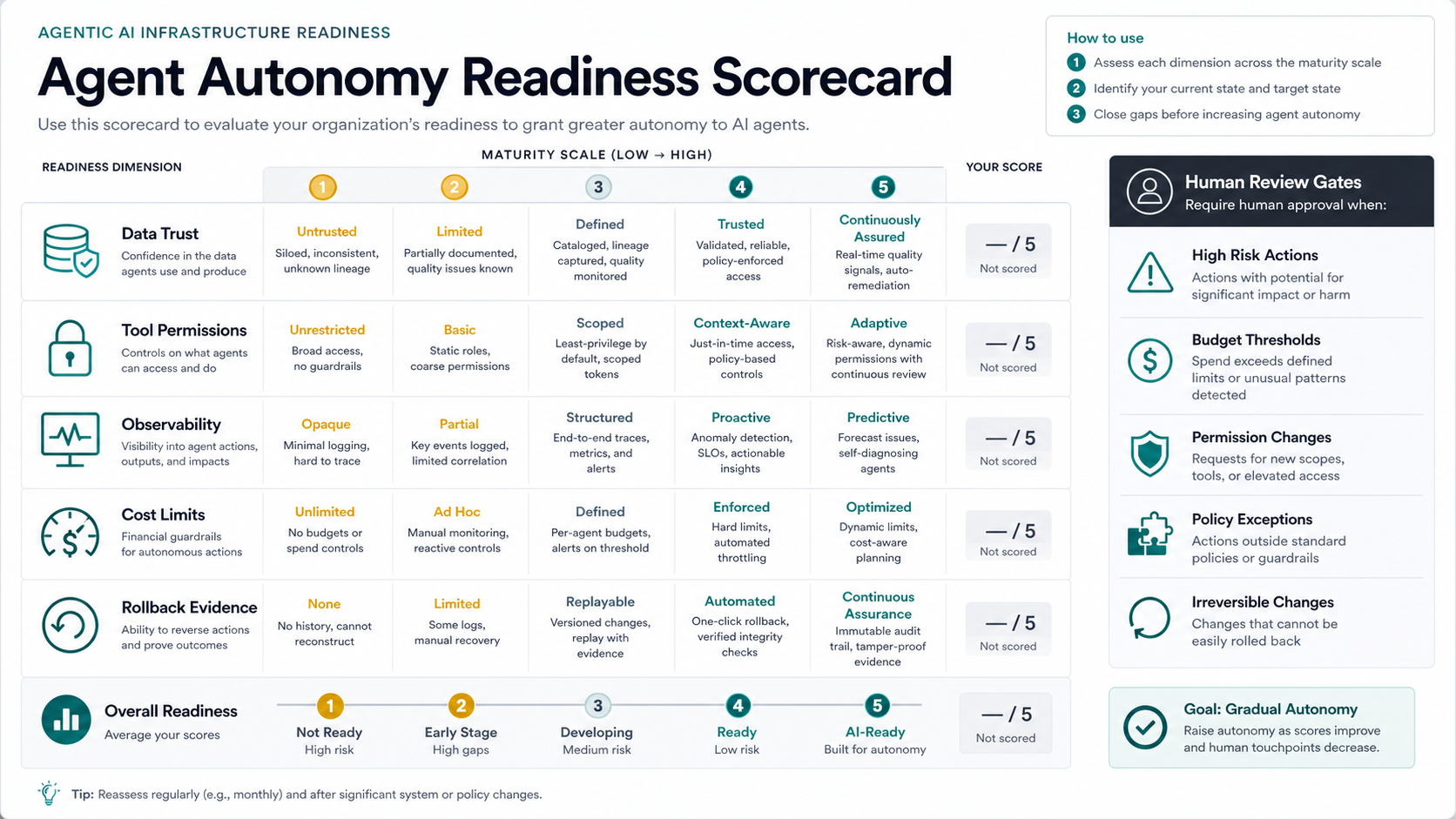
A quick scorecard helps leadership avoid over-automating early. Rate each dimension from one to five: data trust, tool permissions, observability, cost limits, rollback evidence, and human review gates. Then set the allowed autonomy level to the weakest dimension, not the average score.
| Dimension | Low-Readiness Signal | Production-Ready Signal |
|---|---|---|
| Data trust | Owners, freshness, and source priority are unclear. | Sources have owners, freshness checks, schemas, and known limitations. |
| Tool permissions | Agents use broad credentials or informal scripts. | Each tool has scoped identity, schema, policy, and owner. |
| Observability | Teams only see final outputs or dashboard symptoms. | Traces show context, retrieval, tool calls, approvals, errors, and cost. |
| Cost limits | Inference and cloud spend are reviewed after the fact. | Budgets, rate limits, tags, and alerts exist before production usage. |
| Rollback evidence | Failure paths depend on tribal knowledge. | Runbooks, change records, test evidence, and owner approvals are retained. |
The AI agent readiness assessment can help turn these questions into a practical planning session before funding a larger implementation.
The First 90 Days For CTOs
The first 90 days should produce a working, governed path, not a slide deck. Start by choosing one workflow with high volume, clear pain, repeatable steps, and measurable outcomes. Good candidates include service desk triage, incident investigation, cloud cost review, environment provisioning, access request support, or deployment-change analysis.
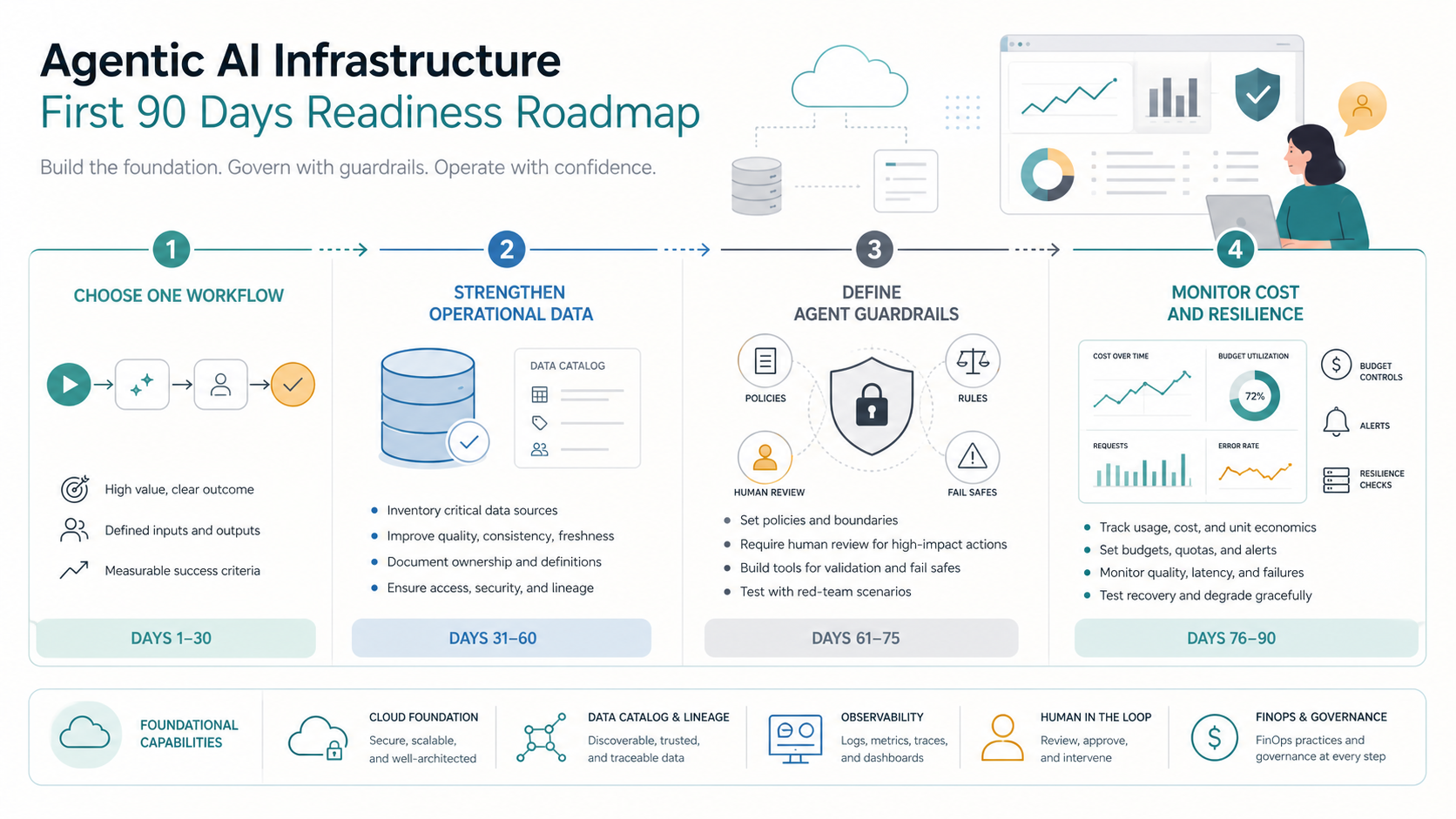
| Readiness Step | What To Decide | Evidence To Keep |
|---|---|---|
| Pick one workflow | Which process has repeatable steps, high volume, and clear ownership? | Workflow map, baseline metrics, target outcome |
| Clean operational data | Which sources are trusted enough for agent reasoning? | Data owner list, freshness checks, known gaps |
| Expose safe actions | Which tools can agents call, and under what permissions? | API list, scopes, approval thresholds |
| Instrument observability | How will teams trace agent decisions, actions, cost, and errors? | Trace schema, dashboards, audit records |
| Govern lifecycle | Who owns each agent, version, prompt, evaluation, and retirement path? | Agent registry, evaluation results, review cadence |
Use this first workflow to create reusable foundations. If service desk triage is the pilot, the same identity, logging, approval, retrieval, and evaluation patterns can later support incident response or cloud cost optimization. The output should be a repeatable delivery model.
Failure-Mode Testing And Rollback Evidence
Agent infrastructure is not ready until it has been tested against realistic failure modes. Test stale data, missing ownership, conflicting policies, API timeout, duplicate action, runaway loop, permission denial, budget exhaustion, bad retrieval, unsafe tool input, human rejection, and partial rollback. A pilot that only succeeds on the happy path does not prove production readiness.
Keep evidence that a future incident reviewer can understand: test cases, trace samples, approval logs, redacted prompts, tool schemas, rollback runbooks, release notes, cost thresholds, and owner sign-off. For regulated or high-impact workflows, pair the infrastructure plan with the governance mindset in the AI governance for critical infrastructure software guide.
Teams that need a focused prototype before platform investment can use an AI agent PoC sprint to rank use cases, check data and integration readiness, define guardrails, and decide whether the workflow deserves production funding.
How NextPage Plans Agent-Ready Infrastructure
NextPage approaches agentic infrastructure as a software and operations problem, not only an AI experiment. We map the target workflow, cloud environment, system integrations, data sources, permissions, observability needs, cost controls, and escalation paths before implementation. Then we scope the smallest agentic workflow that can prove value safely.
That may mean modernizing APIs before an agent can act, improving data quality before retrieval is trusted, strengthening cloud observability before automated remediation is allowed, or starting with a human-in-the-loop agent that drafts actions until evidence supports more autonomy. It may also mean saying no to autonomy where the operational controls are not ready.
The right roadmap depends on your estate, but the principle is consistent: agents should inherit a governed, observable, cost-aware infrastructure foundation. Without that foundation, agentic AI creates fragile automation. With it, agents can become a practical way to improve speed, resilience, and operational focus.