
Quick Answer: Domain-Specific LLM Development
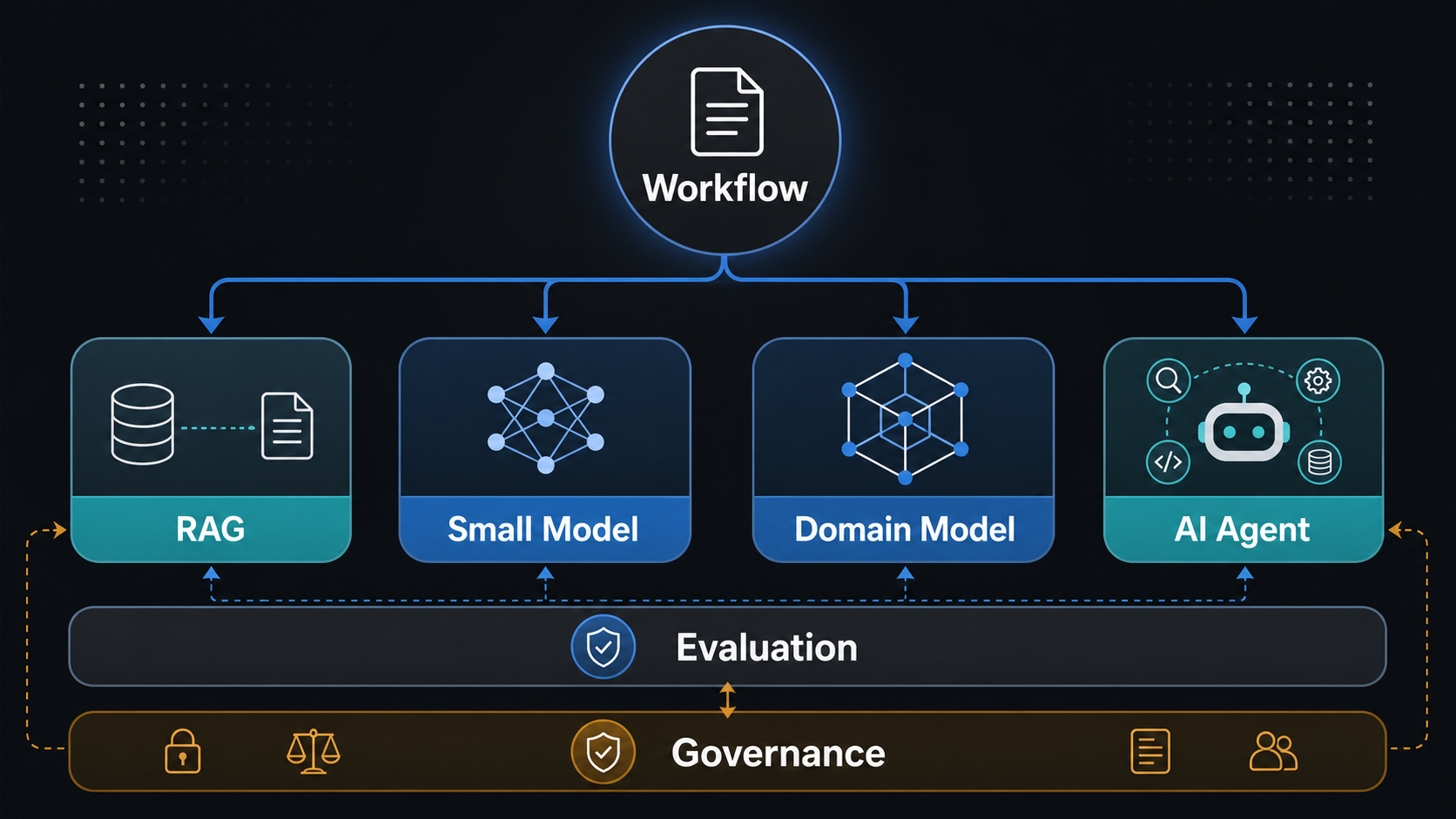
Domain-specific LLM development is the work of adapting generative AI to a narrow business domain, workflow, data environment, risk profile, and operating model. It does not always mean training a new model. In many enterprise cases, the right answer is a retrieval-augmented generation system, a fine-tuned smaller model, an AI agent that uses tools, or a hybrid architecture that combines these patterns.
The practical question is: which build pattern will give the business the best accuracy, traceability, latency, cost, security, and maintainability for one specific job? A legal review assistant, claims triage workflow, maintenance knowledge copilot, clinical documentation helper, or financial operations analyst may all need domain context, but they do not all need the same model strategy. NextPage usually starts this work through LLM development: use-case discovery, data readiness, retrieval design, model selection, evaluation, integration, and production monitoring. If the first release is a private knowledge assistant, the architecture may also fit enterprise RAG implementation services before the team invests in fine-tuning or custom model work.
Why Domain-Specific Models Are Getting Attention in 2026
General-purpose models are useful for broad reasoning and drafting, but enterprise value often depends on narrow context: internal policies, terminology, records, contracts, workflows, product data, compliance rules, and historical decisions. Gartner's March 2026 analysis frames domain-specific language models as a precision tool for business-critical use cases where relevance, compliance, and reliability matter more than generic breadth.
That trend is strongest in domains where mistakes are expensive: healthcare, finance, legal, insurance, manufacturing, cybersecurity, and enterprise operations. The opportunity is not just a smaller model. The opportunity is a system that understands the business context well enough to produce controlled answers, call the right tools, cite the right source, escalate exceptions, and improve over time.
Start With the Workflow, Not the Model
A domain-specific AI project should begin with the workflow it must improve. Define the user, decision, input data, expected output, action taken after the output, human review point, and failure cost. If the task is not clear, model choice becomes a distraction. If the task is clear, the architecture often becomes obvious.
Use an AI readiness pass before committing to a build route. Confirm data access, source quality, permissions, integration points, review controls, evaluation examples, and production ownership. The enterprise AI readiness checklist is a useful starting point when leaders need to compare workflow readiness, governance, security, and data maturity before funding implementation.
RAG vs Fine-Tuning vs AI Agents: The Decision Rule
Use RAG when the system needs current knowledge, source traceability, and fast updates without retraining. Use a fine-tuned or domain-adapted smaller model when the task pattern is stable, the language is specialized, volume is high, latency or cost matters, and you have quality examples for training and evaluation. Use an AI agent when the system must plan multiple steps, call tools, update systems, coordinate approvals, or recover from workflow exceptions.

| Build Pattern | Best Fit | Main Risk | What to Validate First |
|---|---|---|---|
| RAG system | Changing knowledge, policy lookup, product support, internal research, cited answers | Poor retrieval, weak chunking, permission leaks, answer drift | Source quality, retrieval precision, citations, access control |
| Fine-tuned small model | Stable repeated task, domain language, structured extraction, classification, low-latency output | Training data quality, overfitting, stale behavior, hidden evaluation gaps | Labeled examples, holdout tests, cost and latency at expected volume |
| AI agent | Multi-step work that needs tools, state, approvals, and exception handling | Tool misuse, unclear handoff, runaway actions, monitoring gaps | Workflow boundaries, permissions, audit logs, human-in-the-loop controls |
Hybrid Patterns, Long Context, And Agentic RAG
The current enterprise decision is rarely a clean vote for only RAG, only fine-tuning, or only agents. Many production systems combine retrieval for fresh evidence, prompt or context engineering for task framing, lightweight fine-tuning for repeated output behavior, and agent orchestration when the workflow must call tools. Long-context models and prompt caching can reduce pressure to build complex retrieval pipelines for some use cases, but they do not remove the need for permissions, source freshness, evaluation, and cost controls.
A practical hybrid rule is simple: use retrieval for facts that change, model adaptation for behavior that repeats, and agent orchestration for controlled actions. If the domain depends on relationships across products, policies, customers, assets, or procedures, add a knowledge-representation layer before blaming the model. The supporting guide on knowledge representation for RAG systems explains how metadata, taxonomies, source lineage, and access labels improve retrieval quality in complex domains.
When RAG Is the Right First Build
RAG is often the best first domain-specific build because it connects a strong general model to controlled business knowledge. It works well when documents change often, when users need citations, when answers must reflect internal policy, or when the business is not ready to maintain custom model training. A good RAG system is not just vector search. It includes source ingestion, permission-aware retrieval, chunking strategy, reranking, prompt design, response rules, citation display, evaluation tests, and monitoring.
RAG is a strong fit for knowledge assistants, sales enablement, customer support, policy lookup, engineering documentation, and compliance guidance. It is less suitable when the job is a high-volume narrow transformation that does not need source lookup, or when the model must learn a very specific output style from many labeled examples. If the project needs broader production delivery across retrieval, agents, model integration, and monitoring, connect the work to generative AI development instead of treating it as a prompt experiment.
When a Small Domain Model or Fine-Tune Makes Sense
A smaller domain-adapted model can make sense when the task is repeated, narrow, and measurable. Examples include document classification, field extraction, routing, industry-specific summarization, policy tagging, controlled drafting, call categorization, and structured recommendations. The business case improves when the task has high volume, low tolerance for latency, stable requirements, and enough historical examples to train and test against.
The hard part is not choosing a base model. The hard part is preparing data, defining labels, building evaluation sets, preventing leakage, comparing against a RAG baseline, and planning lifecycle maintenance. A fine-tuned model can reduce operating cost and improve consistency, but it can also lock in old behavior if the domain changes quickly. Teams should treat fine-tuning as a product capability with ownership, not a one-time model exercise.
When an AI Agent Is the Right Architecture
An AI agent is the right architecture when the system must do more than answer. Agents are useful when work spans tools: checking records, drafting a response, opening a ticket, updating a CRM, calling an API, summarizing exceptions, and asking for approval. Domain specificity still matters, but the main design problem becomes workflow control, tool permissions, state management, escalation, and auditability.
Agent projects should start with narrow workflows. Use the AI Agent Readiness Assessment when the team needs to test whether a workflow is defined enough for tool-using AI. For conceptual clarity, the comparison in Generative AI vs AI Agents vs Agentic AI can help stakeholders separate content generation from action-oriented workflow systems.
Data Readiness for Domain-Specific LLM Development
Domain-specific AI depends on the data behind it. Useful data is accessible, permissioned, clean enough to retrieve or train on, labeled where needed, representative of real edge cases, and connected to the workflow being improved. Unstructured documents, tickets, transcripts, product records, policies, forms, and knowledge bases can all be valuable, but only when the team understands ownership, sensitivity, update frequency, and retention rules.
For RAG, data readiness means the system can ingest sources, preserve metadata, respect permissions, retrieve the right context, and show citations. For fine-tuning, it means examples are high quality, consistently labeled, and split into training and evaluation sets. For agents, it means tool data is reachable through safe APIs and actions can be logged. If the company is still choosing the first target workflow, the Workflow Automation Opportunity Finder can help rank candidates by repeatability, data availability, and risk.
Evaluation, Governance, and Security Guardrails
Evaluation is the operating system for domain-specific LLM development. Before launch, define golden examples, unacceptable answers, source-grounding checks, latency targets, cost thresholds, human review triggers, and regression tests. After launch, monitor retrieval quality, model behavior, user feedback, escalations, tool calls, and drift. Without evaluation, the team cannot tell whether a domain-specific build is improving or merely feeling impressive in demos.
Security and governance should be designed into the architecture. That includes least-privilege access, data classification, retention rules, prompt and response logging, sensitive-data handling, audit trails, approval flows, rate limits, red-team tests, and incident response. When the system can take action through tools, pair this plan with the secure AI agent development checklist so permissions, approvals, tool calls, logs, and rollback are designed before launch. The broader delivery plan should follow an implementation roadmap like the one described in AI Implementation Roadmap, moving from discovery to prototype, pilot, production, and continuous improvement.
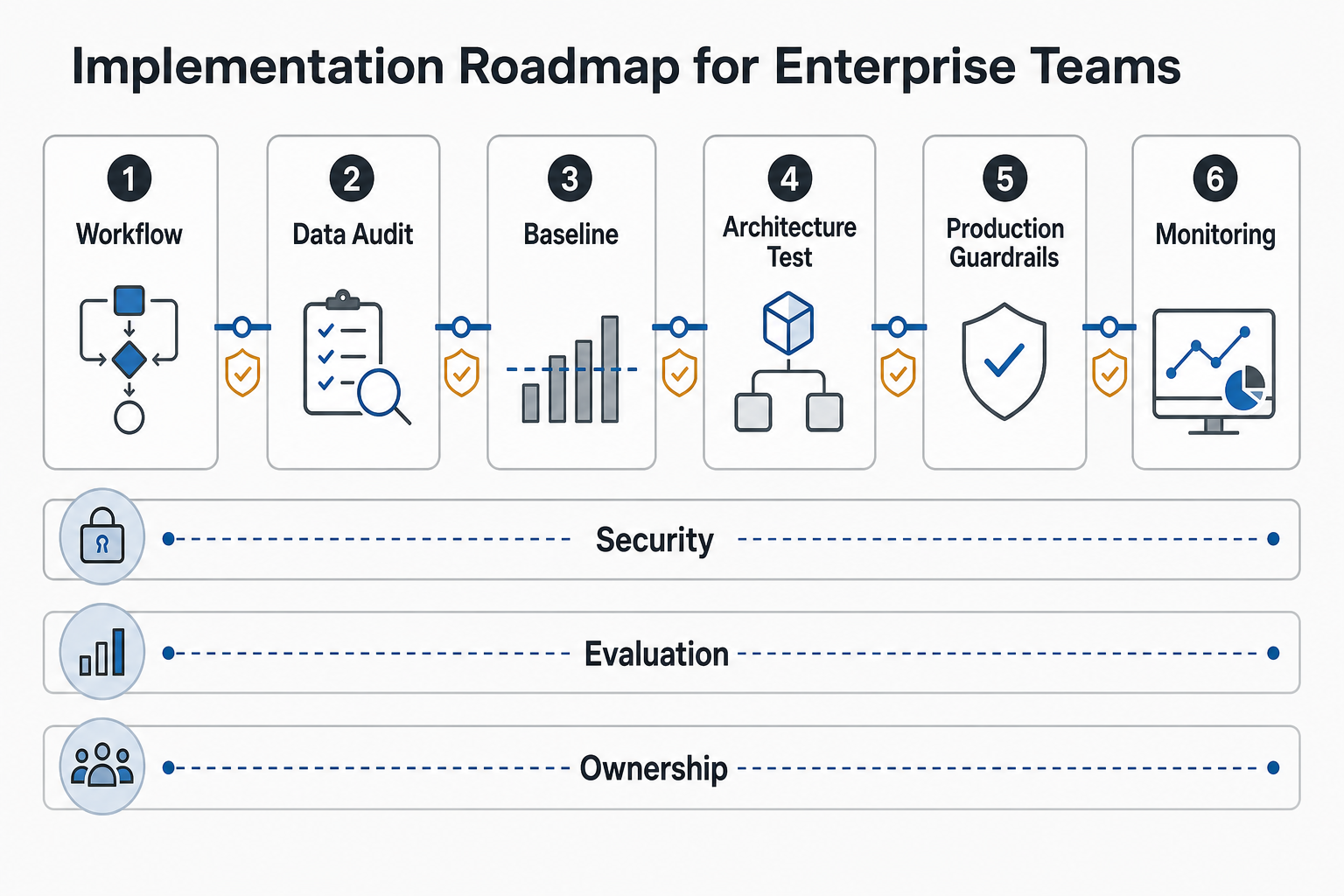
Implementation Roadmap for Enterprise Teams
A practical roadmap usually has six stages. First, select the workflow and define success metrics. Second, audit data, permissions, integration points, and operational risks. Third, build a baseline prototype, usually with RAG or a hosted model, so the team has evidence before investing in model adaptation. Fourth, compare architecture options with evaluation data: RAG quality, fine-tuned model performance, agent reliability, latency, and cost. Fifth, productionize the chosen system with security, monitoring, documentation, and ownership. Sixth, keep the system under active evaluation as content, users, models, and business rules change.
This is where AI development services can be useful. The work crosses product discovery, data engineering, application development, integration, model evaluation, and DevOps. A domain-specific AI system should be shipped like production software: versioned, tested, monitored, and improved through real feedback.
Cost and Team Planning
Cost depends on architecture. RAG costs come from ingestion, storage, retrieval, reranking, model calls, evaluation, and content maintenance. Fine-tuning costs include data preparation, training, evaluation, deployment, inference, and model lifecycle work. Agent costs include orchestration, tool integration, permissions, monitoring, and review workflows. The cheapest path is the one that satisfies the workflow with the least moving parts, not the one with the smallest model in a diagram.
Teams should plan for product, engineering, data, security, and operations roles. A first production release may need a product owner, AI engineer, backend engineer, data engineer, subject-matter expert, QA/evaluation owner, and security reviewer. In regulated environments, legal, compliance, and risk teams should be involved before the pilot touches sensitive data.
How NextPage Helps With Domain-Specific LLM Development
NextPage helps teams turn domain-specific AI ideas into buildable systems. We can assess the workflow, review data readiness, compare RAG, fine-tuning, small-model, and agent options, build an evaluation plan, design the architecture, integrate tools and data sources, and ship production software with monitoring and governance.
If you are deciding whether to build a RAG system, domain-adapted model, or AI agent, start with an LLM/RAG architecture and readiness assessment. The goal is to find the simplest controlled architecture that can deliver useful domain-specific outcomes without adding avoidable model risk.