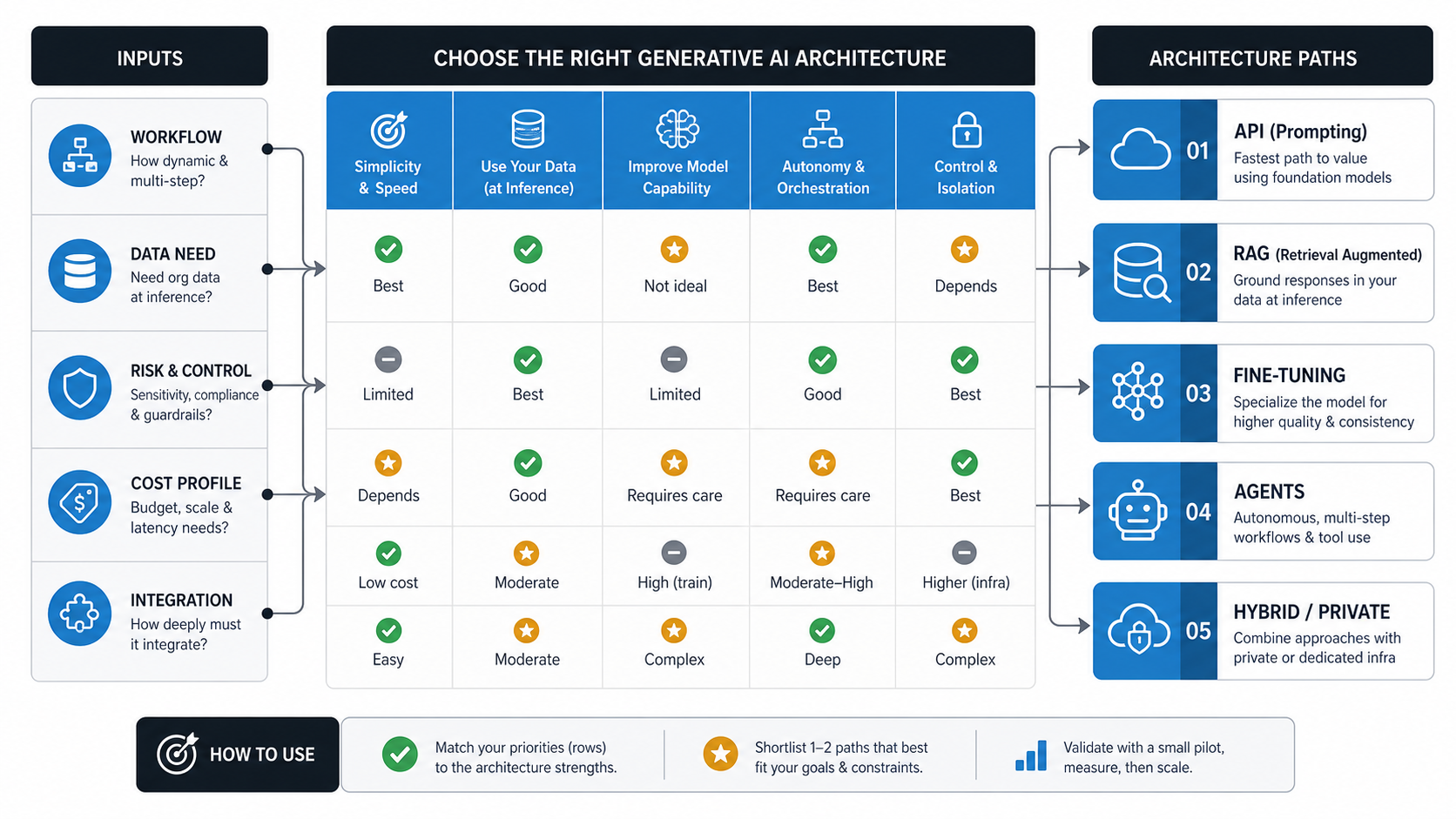

Quick Answer: Which Generative AI Architecture Should You Choose?
The right generative AI architecture is the least complex system that can reliably support the workflow, data, risk, and integration depth you need. Start with a hosted model API when the task is simple generation or summarization. Add RAG when the system must answer from private or frequently changing knowledge. Consider fine-tuning when you need stable domain behavior that prompting and retrieval cannot deliver. Use AI agents when the workflow must plan steps and act across tools. Choose a hybrid or private deployment only when control, data residency, latency, or compliance makes managed APIs insufficient.
This guide is for teams that are past the demo stage. The question is not whether generative AI can produce useful output. The question is which architecture can be evaluated, secured, monitored, integrated, and improved after launch. NextPage's generative AI development and generative AI integration services work starts with that production decision, not with the most advanced pattern by default.
Architecture Options At A Glance
Most buyer conversations collapse several different architectures into one label. Separating them early prevents budget creep and makes vendor estimates easier to compare.
| Architecture | Best Fit | What You Build Around It | Main Risk |
|---|---|---|---|
| Hosted model API | Drafting, summarization, classification, light copilots | Prompt layer, app integration, logging, evaluation set | Generic answers, data leakage, variable quality |
| RAG | Private knowledge, policy Q&A, support knowledge, document workflows | Content ingestion, embeddings, retrieval, citations, freshness controls | Weak retrieval, stale content, poor source governance |
| Fine-tuning | Stable domain style, format, or behavior from repeat examples | Training data, evaluation data, versioning, retraining process | Costly data prep, brittle behavior if the use case shifts |
| AI agent | Multi-step work across APIs, CRMs, ERPs, helpdesks, databases, or files | Tools, permissions, planning limits, human review, audit logs | Unsafe actions, hidden failure paths, poor observability |
| Hybrid or private deployment | High-control environments with sensitive data, latency, residency, or regulatory needs | Model hosting, security boundary, infrastructure, evals, operations | Operational burden and slower iteration |
Architecture Escalation Gate: API, RAG, Fine-Tuning, Agents, Or Private Deployment?
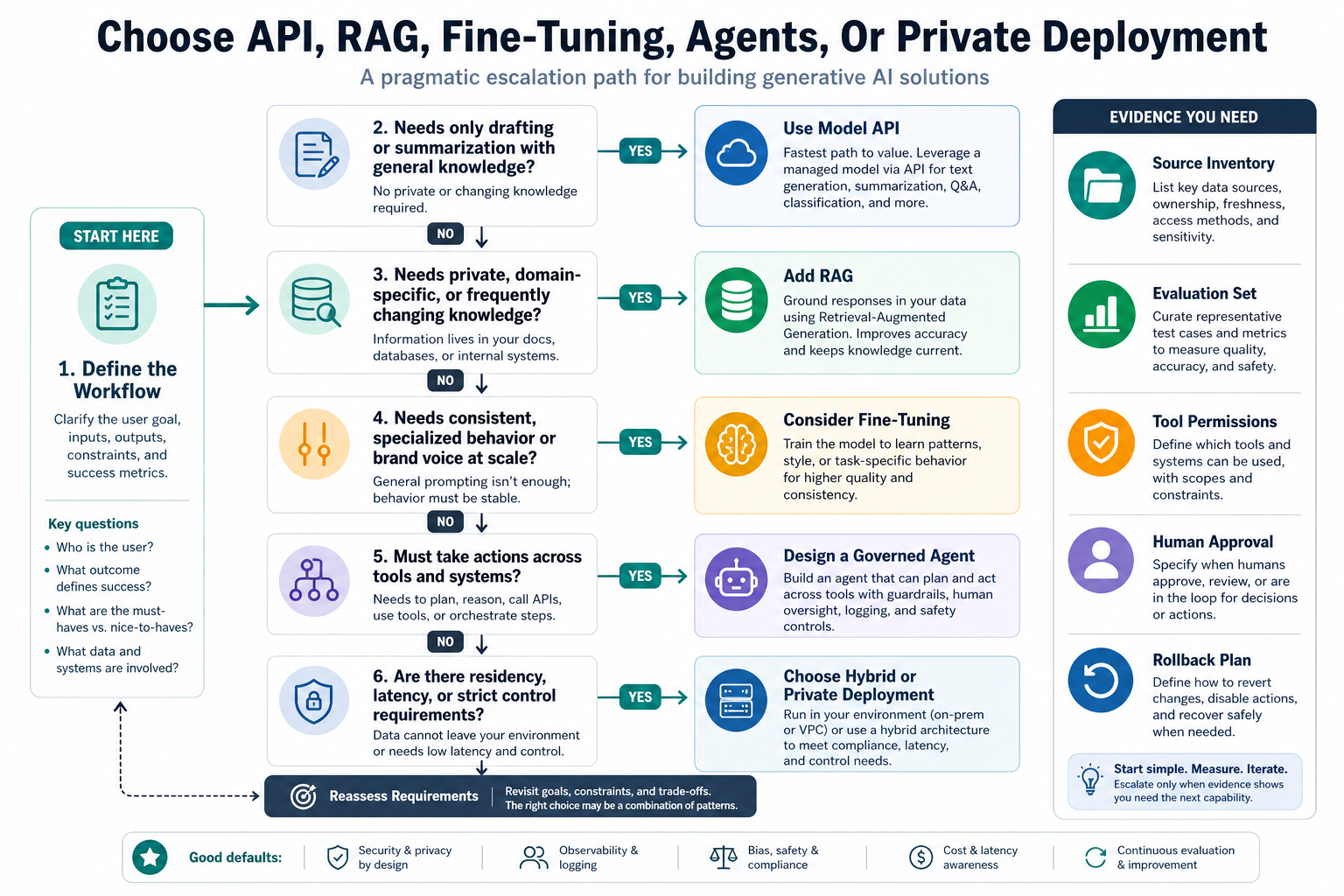
A practical architecture decision should work like a release gate. Start with the workflow and ask what evidence forces a more complex pattern. If the feature only drafts, summarizes, classifies, or extracts for human review, a model API with prompt management and evaluation is usually enough. If the answer must come from private or frequently changing knowledge, add RAG. If the system needs stable learned behavior from repeat examples, evaluate fine-tuning. If the system must choose tools or update records, design a governed agent. If residency, latency, privacy, or cost predictability cannot be met through managed APIs, plan hybrid or private deployment.
This gate also keeps procurement honest. A vendor estimate for an API-first assistant should not be compared with an estimate for a RAG system, a fine-tuned model, or a tool-using agent unless the data, evaluation, integration, security, and operations scope are separated. For a deeper comparison of model APIs, RAG, fine-tuning, custom NLP, and private deployment, pair this guide with NextPage's Custom NLP Vs Generic AI APIs comparison.
| Evidence Found | Architecture Move | What To Validate Before Build |
|---|---|---|
| General task, low risk, limited context | Use a hosted model API | Prompt quality, edit rate, latency, cost, logging, and fallback behavior. |
| Private or changing source knowledge | Add RAG | Source inventory, permissions, chunking, metadata, retrieval quality, citations, freshness, and no-answer behavior. |
| Repeat examples define a stable behavior | Consider fine-tuning | Training examples, held-out eval set, regression checks, versioning, and rollback. |
| System must act across tools | Design a governed agent | Tool scopes, approval rules, audit logs, exception handling, and incident response. |
| Strict residency, latency, privacy, or control | Use hybrid or private deployment | Hosting model, network boundary, security review, monitoring, patching, and operating cost. |
GenAI Architecture Decision Scorecard
Before approving a GenAI build, score the target workflow against five decision dimensions. The goal is not to pick the most sophisticated architecture. It is to expose where API-only, RAG, fine-tuning, agents, or private deployment becomes necessary.
| Decision Dimension | API-First Signal | Escalate Architecture When |
|---|---|---|
| Knowledge freshness | The task uses general knowledge or a small amount of supplied context. | Answers must cite private, regulated, or frequently changing source material, which points toward RAG. |
| Behavior stability | Prompting and examples produce consistent output for the target users. | The team has many reviewed examples and needs repeatable format, tone, extraction, or classification behavior, which may justify fine-tuning. |
| Action depth | The feature drafts, summarizes, classifies, or recommends for a human. | The system must choose tools, update records, route work, or coordinate multiple steps, which requires controlled agent design, AI agent identity governance, and often enterprise AI agent governance. |
| Risk and review | Errors are reversible and a human remains accountable before impact. | The workflow affects money, safety, compliance, customer commitments, or regulated decisions, so approvals, audit logs, and rollback paths must be part of the architecture. |
| Operating control | Managed APIs meet latency, data, security, and cost requirements. | Data residency, strict privacy, latency, or cost predictability requires a hybrid or private model deployment plan. |
Use the scorecard as a gate before vendor comparison. If only one row escalates, stage the architecture around that constraint. If several rows escalate, plan a phased roadmap so the first release proves value before the team commits to a broader platform.
2026 Architecture Decision Notes For Production GenAI
Architecture choices in 2026 should be made against live operating evidence, not demo output alone. Treat each option as a product system with evals, retrieval quality checks, permission boundaries, cost telemetry, and rollback paths. Current platform guidance from OpenAI, Google Cloud, AWS, and NIST all points to the same pattern: teams need measurable quality gates and risk controls before they scale from a pilot to production.
| Decision Area | What To Prove Before Scaling | Architecture Implication |
|---|---|---|
| Evaluation | Golden task set, human review rubric, regression tests, latency and cost thresholds, and production monitoring. | Do not graduate from an API prototype until the eval suite catches quality drift and unacceptable failure modes. |
| Retrieval | Source ownership, chunking strategy, metadata, permissions, freshness, citation quality, and no-answer behavior. | RAG is justified when source governance and retrieval evaluation are part of the build, not when documents are merely embedded. |
| Agents | Tool scopes, identity model, approvals, audit logs, exception handling, and incident response. | Use an agent only when action depth creates enough value to justify governance, which can be checked with an AI Agent Readiness Assessment. |
| Financial Case | Automation volume, human time saved, edit rate, compute/API spend, support burden, and rework cost. | Estimate the business case before selecting a heavier pattern with the AI Automation ROI Calculator. |
| Control Boundary | Data residency, privacy, latency, vendor risk, model change exposure, and operating capacity. | Private or hybrid deployment is a control decision, not a prestige architecture. |
This layer also clarifies the difference between prompt work and architecture work. If the system mainly needs reliable instructions, examples, and output formatting, production prompt engineering may be the right first step. If the system must model business context across policies, knowledge graphs, tools, and operational records, pair this guide with NextPage's knowledge representation in AI business systems playbook.
Start With The Workflow, Not The Model
A good architecture choice begins with one business workflow. Name the user, trigger, input, decision, output, systems touched, acceptable latency, quality threshold, and fallback route. If the workflow only needs a draft, a model API may be enough. If it needs account-specific answers, retrieval probably matters. If it must update records, open tickets, or call tools, you are discussing agent design and governance.
Use the same discovery lens NextPage uses for AI development services: workflow value, data sensitivity, integration depth, model quality, human review, operating cost, and measurement. The architecture should follow those constraints. A complex architecture can impress in a proposal and still fail if the workflow owner cannot explain when the AI should be trusted.
When A Model API Is Enough
A hosted model API is often the best first release when the output is assistive and the business risk is low. Examples include rewriting descriptions, summarizing notes, classifying inbound requests, generating first-draft responses, extracting fields for review, or helping staff create internal documents. You still need prompt management, input validation, logging, quality checks, access controls, and a fallback state, but you avoid building a retrieval or agent platform before the use case proves value.
The test is simple: can the task be solved with the model's general capability plus a small amount of structured context? If yes, keep the first release API-first. Measure output quality, edit rate, time saved, user adoption, and failure cases. Add more architecture only when evidence shows that the API-only pattern is hitting a real ceiling. When the feature must be embedded into an existing SaaS product, CRM, support desk, ERP, or internal workflow, NextPage's Generative AI Integration Services page is the more specific planning path.
When RAG Is The Right Path
RAG is the right architecture when answers must be grounded in private, proprietary, or frequently changing content. It is common for policy assistants, support copilots, product documentation search, legal or compliance knowledge, internal operations knowledge, and customer-account-specific Q&A. The model does not memorize your source material. Instead, the application retrieves relevant chunks and asks the model to answer from that context.
RAG is not just a vector database. You need source ownership, content cleanup, chunking strategy, metadata, freshness rules, retrieval evaluation, citation handling, permissions, and a way to remove outdated material. If the team cannot govern the knowledge base, the model will still sound confident while using weak context. For private knowledge assistants, NextPage's Enterprise RAG Implementation Services page breaks that work into source ingestion, retrieval design, permissions, evaluation, and production rollout. For teams building broader LLM products, NextPage's LLM development work treats retrieval quality and evaluation as first-class engineering tasks.
Knowledge modeling matters as much as embeddings. The Knowledge Representation In AI guide explains how entities, metadata, workflow context, and source ownership make RAG more reliable than dumping documents into a vector store.
When Fine-Tuning Makes Sense
Fine-tuning makes sense when the model needs consistent domain-specific behavior from many examples: a format, tone, classification pattern, extraction pattern, or specialized response style that prompting and retrieval cannot reliably hold. It is usually not the first answer for adding company knowledge. For changing knowledge, RAG is usually better. For stable behavior, fine-tuning can reduce prompt size, improve consistency, and make output easier to evaluate.
Before fine-tuning, confirm that you have enough high-quality examples, a repeatable evaluation set, clear failure categories, and a plan for versioning. Bad examples teach the model bad behavior. A good fine-tuning plan also defines when the model should refuse, escalate, or ask for more information. Fine-tuning without evaluation is just a more expensive guess.
When AI Agents Are The Right Architecture
An AI agent is useful when the system must do more than answer. Agents plan a sequence, choose tools, call APIs, read or write records, route tasks, and hand work to people when confidence or policy requires it. That can be valuable for customer support, sales operations, internal IT, finance operations, logistics exceptions, HR intake, or document workflows.
Agents also raise the risk level. Tool permissions, action limits, identity, approval steps, audit logs, rollback, and monitoring become architecture requirements. If your team is unsure whether a workflow is ready for agentic automation, use the AI Agent Readiness Assessment before investing in a large build. For workflow automation that needs governed tool use, NextPage's Agentic AI Development Services page is the commercial path, while the AI Agent Identity Governance Checklist covers non-human identities, scoped access, audit logs, and incident response. The distinction between a chatbot, an agent, and a broader agentic system is covered in more detail in Generative AI vs AI Agents vs Agentic AI.
When Hybrid Or Private Deployment Is Justified
Hybrid or private GenAI architecture is justified when managed APIs cannot satisfy data residency, security, latency, customization, cost predictability, or regulatory requirements. This might mean private retrieval with a hosted frontier model, a self-hosted open model for sensitive workloads, dedicated cloud deployment, or a split architecture where high-risk tasks stay inside a controlled boundary while lower-risk tasks use external APIs.
The tradeoff is operational responsibility. Private deployment can increase control, but it also adds model hosting, infrastructure tuning, monitoring, patching, security review, model evaluation, and support ownership. Do not choose private deployment for prestige. Choose it because a documented requirement makes the added operating cost worthwhile.
Match The Architecture To Data, Risk, And Workflow Depth
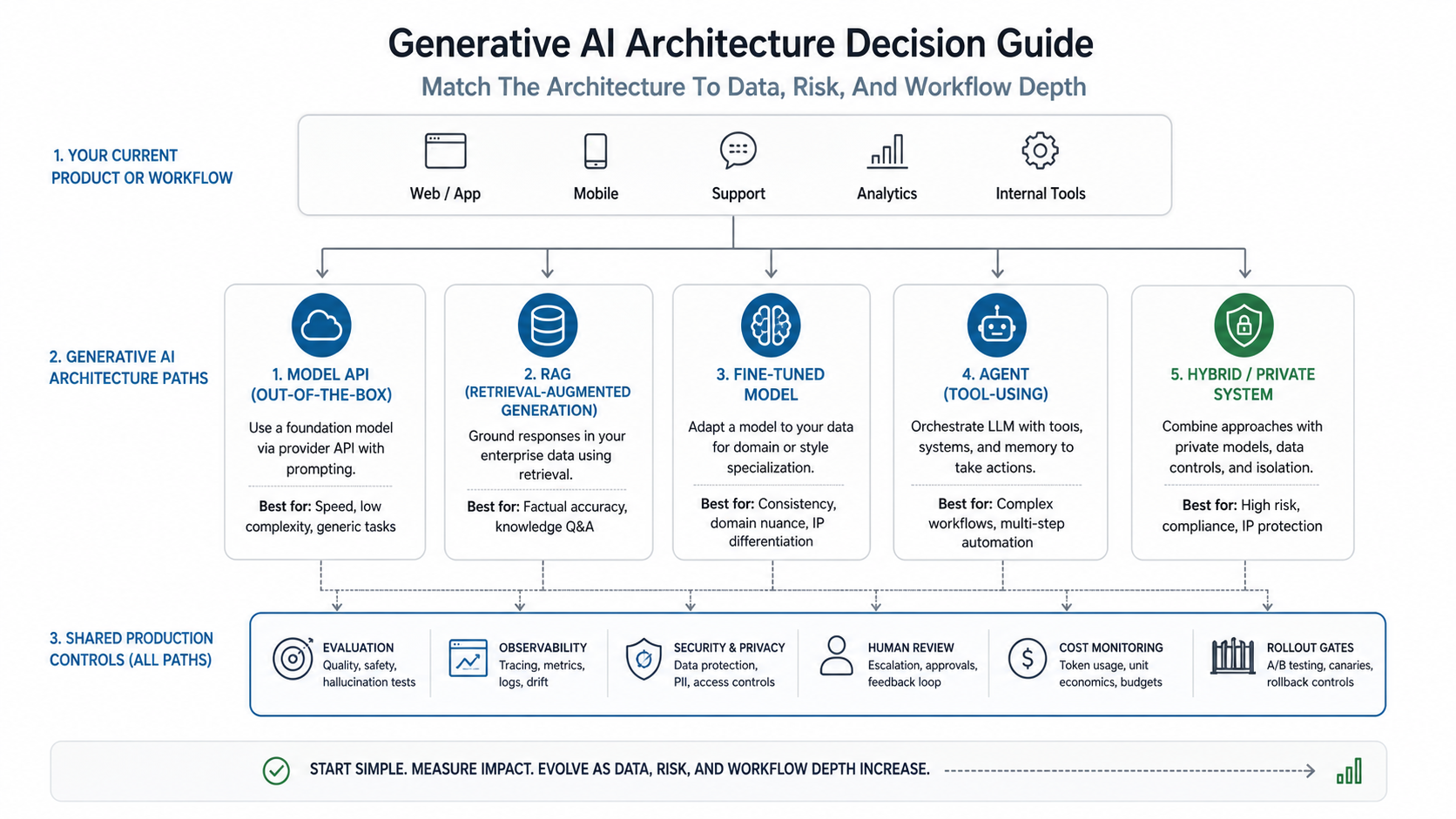
A practical decision matrix should score five dimensions: workflow depth, knowledge freshness, behavior stability, action risk, and operating control. A shallow content task with low data sensitivity points to API-first. A knowledge-heavy support workflow points to RAG. A stable output pattern from repeat examples may justify fine-tuning. A workflow that takes actions across tools points to agents. A high-control environment may require hybrid or private deployment.
Cost should be part of the same decision, not a separate procurement spreadsheet. The Generative AI Development Cost guide explains why the surrounding system often drives budget more than the model itself, while LLM App Development Cost breaks down model, RAG, integration, evaluation, and maintenance drivers.
Evaluation Is The Control Plane
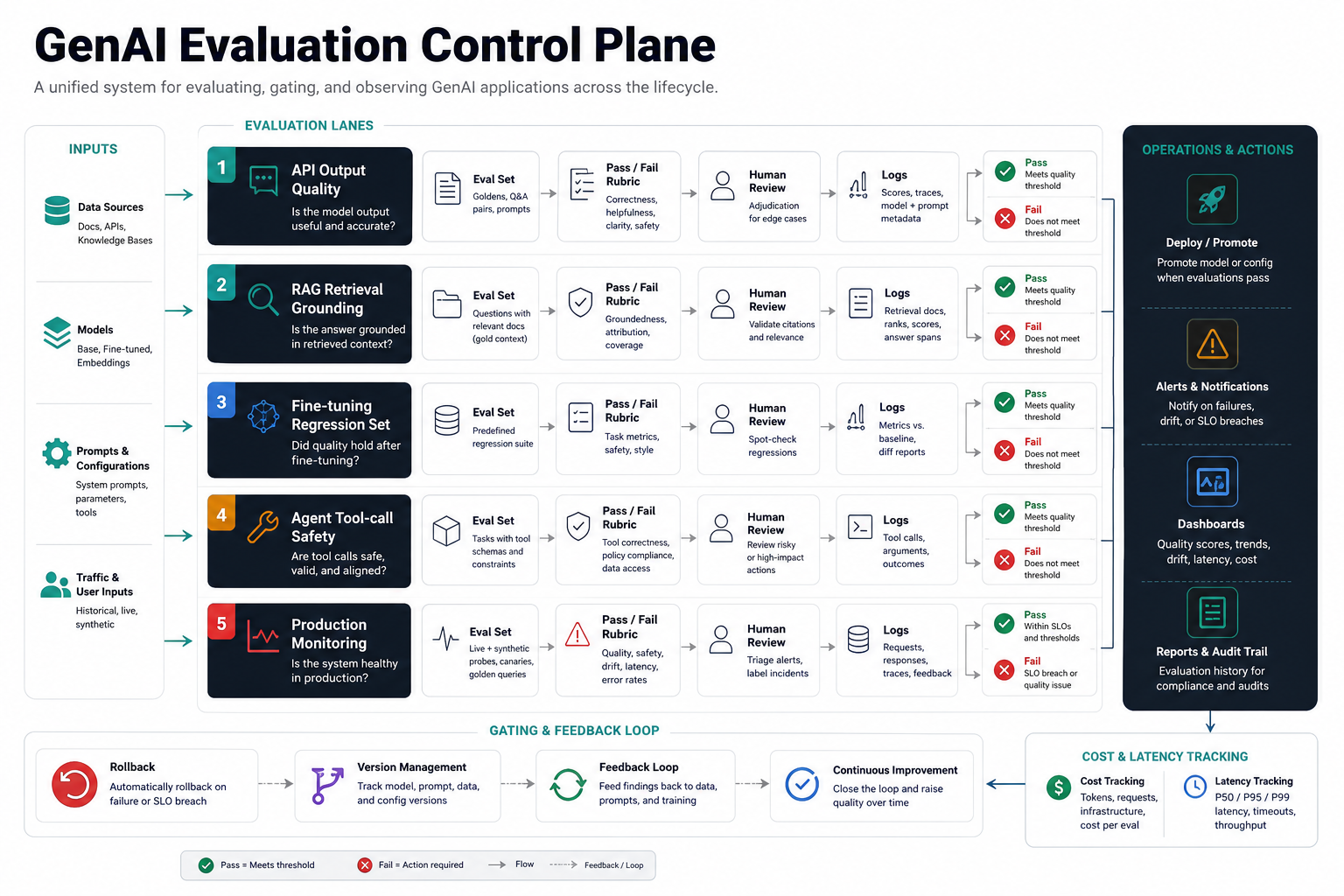
Every architecture needs evaluation. For a model API, test representative prompts and expected outputs. For RAG, test retrieval precision, answer grounding, citation quality, and no-answer behavior. For fine-tuning, compare base and tuned behavior on a held-out set. For agents, test tool-choice accuracy, permission boundaries, exception handling, and recovery when an API fails.
Build evaluation into the project before launch. A practical first evaluation set can include 50 to 200 real examples grouped by business scenario, risk level, and expected outcome. Add pass/fail rubrics, human review notes, and regression tests for known failure modes. The evaluation set should grow after launch from real user feedback, rejected answers, tool failures, latency spikes, high-cost traces, and support escalations.
| Architecture | Minimum Evaluation Gate | Production Signal To Monitor |
|---|---|---|
| Model API | Golden prompts, expected output examples, edit-rate review, safety checks | Quality score, latency, token cost, refusal/escalation rate, user edits |
| RAG | Retrieval precision, grounded answers, citation quality, no-answer behavior | Source freshness, missing-doc rate, unsupported claims, permission mismatches |
| Fine-tuning | Held-out regression set, base-versus-tuned comparison, format and style checks | Drift, retraining need, failure clusters, rollback frequency |
| Agents | Tool-choice accuracy, permission tests, human approval routes, recovery paths | Tool failures, unsafe action attempts, audit completeness, exception queues |
| Hybrid or private | Security, latency, cost, reliability, model quality, and operations readiness | Infrastructure cost, uptime, patch status, latency percentiles, security events |
If your team is still defining readiness, the Enterprise AI Readiness Checklist can help align data, workflow, security, and governance before the build.
Integration And Governance Checklist
Production GenAI lives inside software. Before choosing an architecture, confirm these controls:
- Which user role can access the feature and which data can it see?
- Which system is the source of truth for knowledge, records, and outcomes?
- How are prompts, retrieval settings, model versions, and tool permissions changed?
- What logs are retained for audit, debugging, and quality improvement?
- Which outputs require human approval before a customer, employee, or system sees the result?
- What happens when the model is unavailable, too slow, uncertain, or blocked by missing data?
- Who owns monitoring, incidents, feedback review, and rollout decisions after launch?
For workflow-heavy cases, compare the architecture against AI workflow automation patterns. Sometimes the best first release is a rules-and-integration workflow with AI assistance, not a fully autonomous agent.
A Phased Roadmap For Choosing And Building
Use a phased roadmap to keep the architecture honest:
- Discovery: define the workflow, data, risk, integrations, success metric, and first release boundary.
- Architecture decision: choose API, RAG, fine-tuning, agents, hybrid/private, or a staged combination.
- Prototype: test real examples, integrate one workflow path, and capture user feedback.
- Evaluation: build a repeatable test set and compare failure modes before adding scope.
- Production hardening: add permissions, logging, monitoring, review queues, cost controls, and fallback behavior.
- Rollout: launch to a limited group, measure outcomes, and expand only after evidence supports it.
For ROI planning, use the AI Automation ROI Calculator to estimate whether the workflow value justifies automation depth before you commit to a complex architecture. Budget planning should also include the surrounding product work described in Generative AI Development Cost and LLM App Development Cost.
Common Mistakes That Lead To Overbuilt GenAI Systems
- Choosing agents when the workflow only needs answer generation.
- Using fine-tuning to solve a changing knowledge problem that needs retrieval.
- Building RAG without source ownership, freshness rules, or retrieval evaluation.
- Skipping human review for actions that affect money, compliance, customer experience, or safety.
- Comparing vendor estimates without separating UI, retrieval, integrations, evals, security, and operations.
- Launching a demo without monitoring model quality, cost, latency, and failure modes.
- Choosing private deployment without a requirement that justifies the operational burden.
How NextPage Helps Choose And Build The Right GenAI Architecture
NextPage helps teams turn GenAI ideas into production systems. We map workflows, audit data and knowledge sources, choose the architecture, build LLM and RAG applications, design controlled agents, integrate with existing software, add evaluation and monitoring, and plan phased rollout. The goal is not to maximize architecture complexity. The goal is to build a system your team can trust, measure, and improve.
If you are choosing between API-first GenAI, RAG, fine-tuning, AI agents, or private deployment, start with an architecture review. Bring the target workflow, data sources, integration points, risk level, and desired business outcome. We will help identify the simplest credible first release and the path to production.