
Quick Answer: Knowledge Representation for RAG
Knowledge representation for RAG systems is the way a team structures business knowledge so retrieval can find the right context, respect permissions, and give a language model enough evidence to answer accurately. In a simple prototype, this may mean clean documents and embeddings. In a production enterprise workflow, it usually means metadata, taxonomies, entity definitions, relationship mapping, permission labels, source lineage, and evaluation data working together.
The goal is not to make RAG more academic. The goal is to make it more dependable. A RAG assistant that only stores document chunks in a vector database can work for narrow use cases, but it often struggles with ambiguous terms, duplicate content, product hierarchies, regulatory policies, customer-specific rules, and questions that require relationships across systems. Strong LLM development treats knowledge representation as part of the product architecture, not as a cleanup task after the model starts producing weak answers.
Why RAG Needs More Than Embeddings
Embeddings are useful because they let a system retrieve content by semantic similarity. That does not mean embeddings understand your business structure. If a user asks about refund rules for a specific product tier, a plain vector search may retrieve a generic policy, an outdated FAQ, a sales deck, or a support transcript that uses similar words but has the wrong authority.
Knowledge representation adds the missing structure. Metadata tells the system which source a chunk came from, when it was updated, who can see it, which product or region it applies to, and whether it is approved for customer-facing answers. Ontologies define the important entities, synonyms, categories, and relationships in the domain. Knowledge graphs can connect customers, products, policies, systems, procedures, and exceptions so retrieval can follow meaning instead of only text similarity.
This matters most when the RAG system supports real decisions: customer support, compliance research, internal operations, sales enablement, product documentation, technical troubleshooting, or regulated workflow assistance. In those settings, a confident answer from the wrong source is worse than a refusal.
Architecture for Represented Knowledge in RAG
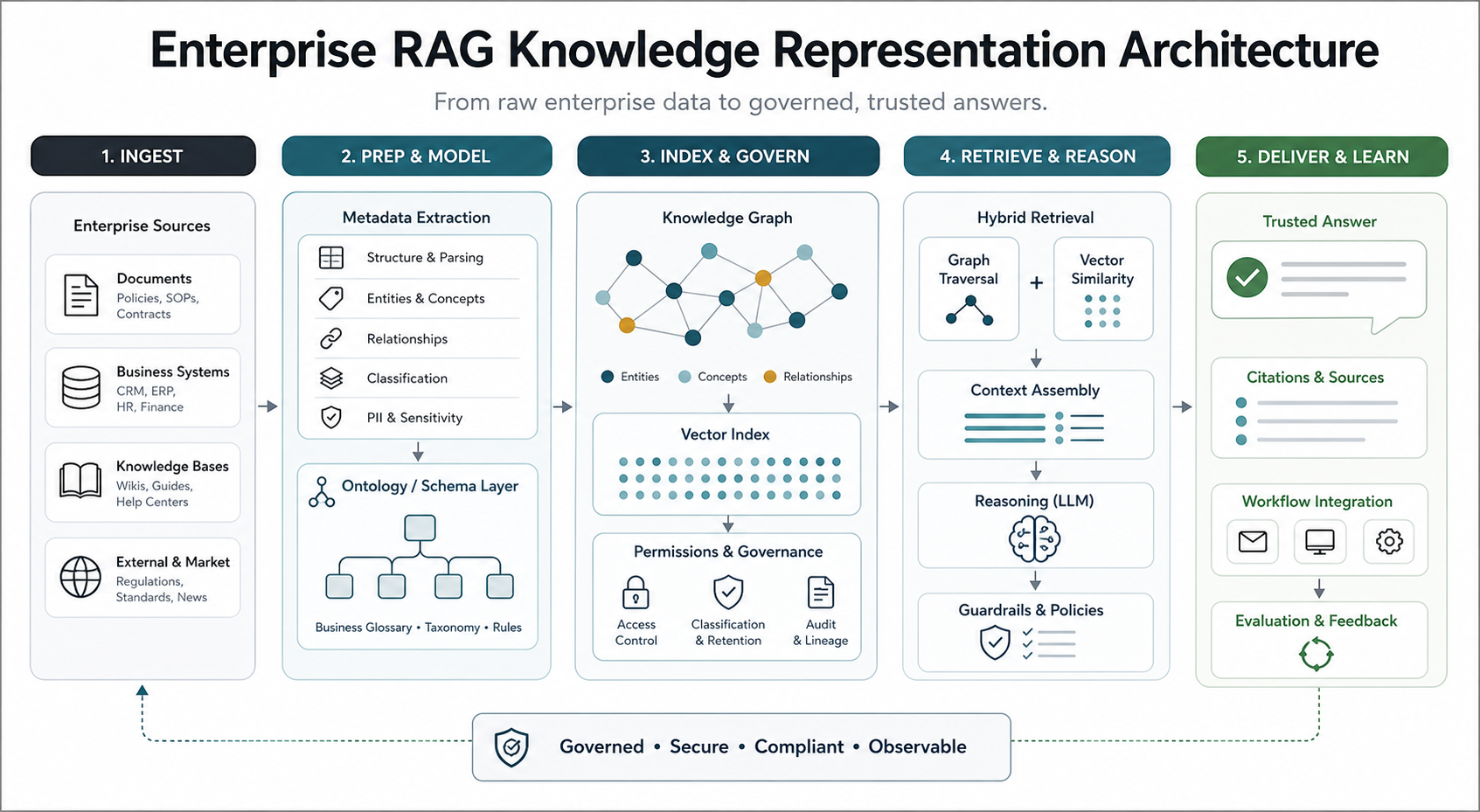
A practical architecture starts with trusted sources. These can include documents, help centers, product data, CRM records, ERP data, tickets, wikis, policies, contracts, research notes, and market references. The ingestion layer extracts text, tables, headings, file metadata, owners, timestamps, identifiers, and access rules. From there, the system can enrich content with domain metadata and map it into an ontology or graph where useful.
The retrieval layer should combine techniques when the workflow justifies it. Vector search helps with natural language similarity. Keyword search helps with exact product names, error codes, policy IDs, customer IDs, and acronyms. Metadata filters keep answers scoped to the right region, role, source, product, or date. Graph traversal can surface related entities or policy dependencies. Reranking can improve precision after the first candidate set is retrieved.
That is why knowledge representation often belongs inside broader generative AI development. The model is only one part of the system. The quality of the answer depends on source quality, retrieval design, access controls, evaluation, and how the final experience handles uncertainty.
Metadata That Makes RAG Retrieval Usable
Metadata is the lowest-friction place to start. Useful RAG metadata usually includes source type, source owner, canonical URL or system ID, created and updated dates, approval status, product or service area, region, language, audience, sensitivity level, access group, retention rule, and known replacement or deprecation status.
Metadata should support decisions the application must make during retrieval. If the assistant answers customer questions, it needs to know which content is approved for external use. If it supports employees, it needs to know department, role, and location rules. If it supports regulated workflows, it needs lineage, retention, review status, and escalation rules. Without this structure, the retrieval layer has to guess.
A useful test is simple: list the reasons a retrieved chunk might be wrong even when it sounds relevant. Then convert those reasons into metadata or filters. Wrong region, stale document, internal-only source, draft policy, wrong customer tier, superseded version, or missing legal review are not model problems; they are representation problems.
Ontology vs Knowledge Graph vs Vector Index
An ontology defines the concepts and relationships that matter in a domain. It can be lightweight: product, plan, feature, policy, exception, customer segment, regulation, workflow, system, and owner. The value is shared vocabulary. When teams agree what entities mean, the RAG system can classify content and interpret queries more consistently.
A knowledge graph stores entities and relationships so the system can reason over connections. For example, a product may belong to a category, depend on an integration, be governed by a policy, be sold in specific regions, and have support exceptions for certain account types. A graph can help retrieval find the relevant policy chain instead of only the nearest text chunk.
A vector index stores embeddings for semantic retrieval. It is still valuable, but it should not carry the whole architecture alone. For many teams, the best first version is hybrid: a vector index for semantic candidates, metadata filters for scope, keyword search for exact references, and a small ontology for classification. A graph becomes more valuable when answers depend on relationships across systems or when the domain has strong entity structure. The article on domain-specific LLM development is a useful companion when deciding whether a workflow needs RAG, fine-tuning, a smaller model, or an agent.
Data Prep Checklist for RAG Knowledge Representation
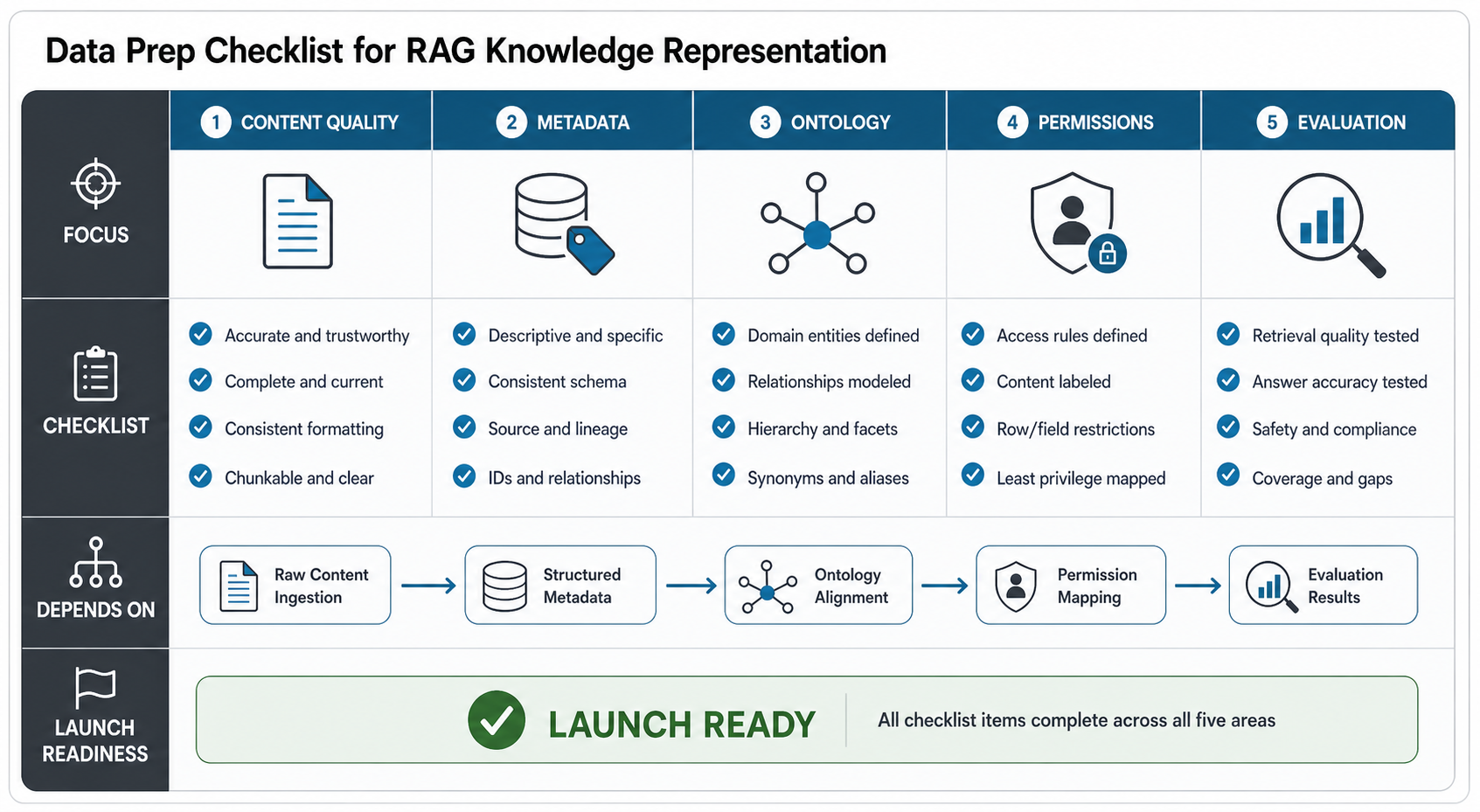
Start with content quality. Remove duplicates, mark outdated pages, identify the canonical source for repeated policies, and split long documents into sections that preserve meaning. Tables, lists, decision trees, and policy exceptions should be extracted carefully because they often carry the facts users need most.
Next, define metadata. Decide which fields are mandatory, which can be inferred, and which must be reviewed by a human. Source owner, update date, approval status, audience, product area, access group, and sensitivity level are common first fields. Keep the schema small enough that teams will maintain it.
Then define the ontology. Create names for important entities, synonyms, hierarchy, and relationships. This does not have to start as a large formal model. A business glossary plus a small taxonomy can be enough for the first release. The key is consistency: the same product, policy, department, or process should not be labeled five different ways.
Permission mapping should happen before production use. The RAG system should never retrieve content the current user is not allowed to see. For multi-tenant software, this may require tenant IDs, account IDs, role filters, row-level restrictions, and audit logs. For internal systems, it may require department, location, seniority, or project membership rules.
Finally, build an evaluation set. Include real questions, expected source documents, accepted answer traits, hard negatives, stale content examples, permission boundaries, and cases where the system should say it does not know. The AI Agent Readiness Assessment is useful before this stage because many RAG and agent projects fail on workflow clarity, data readiness, integration access, or human-review controls.
Retrieval Patterns for Structured Enterprise Knowledge
Different workflows need different retrieval patterns. A policy assistant may use metadata filters first, then hybrid search, then citation checks. A support assistant may combine product metadata, customer tier, ticket history, help-center content, and escalation rules. A sales assistant may retrieve approved security answers, case studies, pricing notes, and implementation constraints while excluding private customer records.
For regulated or sensitive workflows, retrieval should be conservative. It is better to return fewer high-confidence sources than to assemble a broad context window that includes stale or unauthorized material. For exploratory internal research, broader retrieval may be acceptable if the interface shows citations and uncertainty clearly.
The most reliable systems make retrieval observable. Track which sources were considered, which filters were applied, which chunks were used, which citations were shown, and how the user responded. This creates the feedback loop needed to improve metadata, chunking, ontology coverage, and source quality over time.
Governance and Risk Controls
Knowledge representation is also a governance tool. It helps teams explain where an answer came from, why certain sources were excluded, who can access specific knowledge, and which version of a document supported the response. That matters for compliance, customer trust, and internal accountability.
For higher-risk AI products, align the RAG knowledge plan with data governance. Teams should know what data is indexed, how long it is retained, whether embeddings contain sensitive content, who can delete or update sources, and how evaluation logs are reviewed. NextPage's enterprise AI readiness checklist and EU AI Act readiness checklist cover related data, audit, and governance questions for AI software teams.
Do not wait until after launch to define escalation behavior. The assistant needs a safe path when it finds conflicting sources, weak evidence, missing permissions, or incomplete information. In many enterprise workflows, the correct answer is a cited draft plus a human review queue, not full automation.
Implementation Roadmap
Begin with one workflow and one measurable outcome. A broad company-wide knowledge assistant sounds attractive, but a narrow use case is easier to evaluate. Examples include support answers for one product line, onboarding questions for one department, sales security questionnaires, or compliance policy lookup for one region.
Audit the sources next. Identify the canonical knowledge, owners, freshness rules, access boundaries, and known gaps. Build a small metadata schema and classify the first corpus. If the use case has strong entity relationships, define a lightweight ontology and decide whether graph retrieval belongs in the first release or a later phase.
Prototype retrieval before designing the full user experience. Test representative questions, tune chunking, compare vector and hybrid search, apply metadata filters, and measure whether the system finds the expected sources. Then integrate the model and evaluate groundedness, citation quality, answer completeness, latency, and cost.
Before production, add authentication, permission filters, logging, feedback capture, evaluation jobs, monitoring, and escalation rules. If the business case is still unclear, use the AI Automation ROI Calculator to estimate whether the repeated workflow has enough volume and value to justify a full implementation.
How NextPage Helps
NextPage helps teams move from AI interest to working RAG and LLM systems. The work usually starts with workflow discovery, data-readiness review, source mapping, metadata and ontology design, retrieval architecture, prototype evaluation, interface design, and production integration.
For some teams, the right first step is a knowledge assistant. For others, it is a customer-support chatbot, a domain-specific internal copilot, a retrieval layer for an existing product, or a supervised AI workflow that hands work to humans at the right moment. The architecture should follow the decision, risk, data, and integration requirements.
If your team is planning a RAG system, NextPage can review your knowledge sources, identify representation gaps, design the retrieval architecture, and build the first production-ready workflow around measurable quality instead of a demo that works only on easy questions.