
Quick Answer: LLM App Development Cost
LLM app development cost depends on what the application must reliably do with language, data, tools, users, and governance. A simple prompt prototype is not the same build as a private knowledge assistant, a RAG-powered customer support copilot, or an AI feature inside a SaaS product that reads account data, calls APIs, stores audit logs, and is monitored after launch.
The biggest budget drivers are usually product scope, data readiness, retrieval design, system integrations, security controls, evaluation, deployment, and maintenance. Model API usage matters, but it is only one part of the operating cost. The implementation effort comes from turning a model into a dependable software workflow.
If you already know you need an LLM product, start with LLM development planning around use case, data, retrieval, model choice, integrations, evaluations, and cost boundaries. If the workflow may become an autonomous or semi-autonomous agent, use the AI Agent Readiness Assessment before estimating a production build.
What Counts as an LLM App?
An LLM app is a software product or workflow that uses a large language model to understand, generate, transform, retrieve, reason over, or act on text and structured context. It may look like a chat interface, but the useful part is often the system around the chat: data connectors, retrieval, permissions, prompts, tools, evaluation, analytics, and handoff paths.
Common examples include internal knowledge assistants, policy copilots, customer support draft tools, sales research assistants, document review workflows, compliance triage, product onboarding assistants, AI search experiences, and SaaS features that summarize, classify, or recommend next actions. The more the system touches private data or business actions, the more it should be estimated like custom software rather than a model demo.
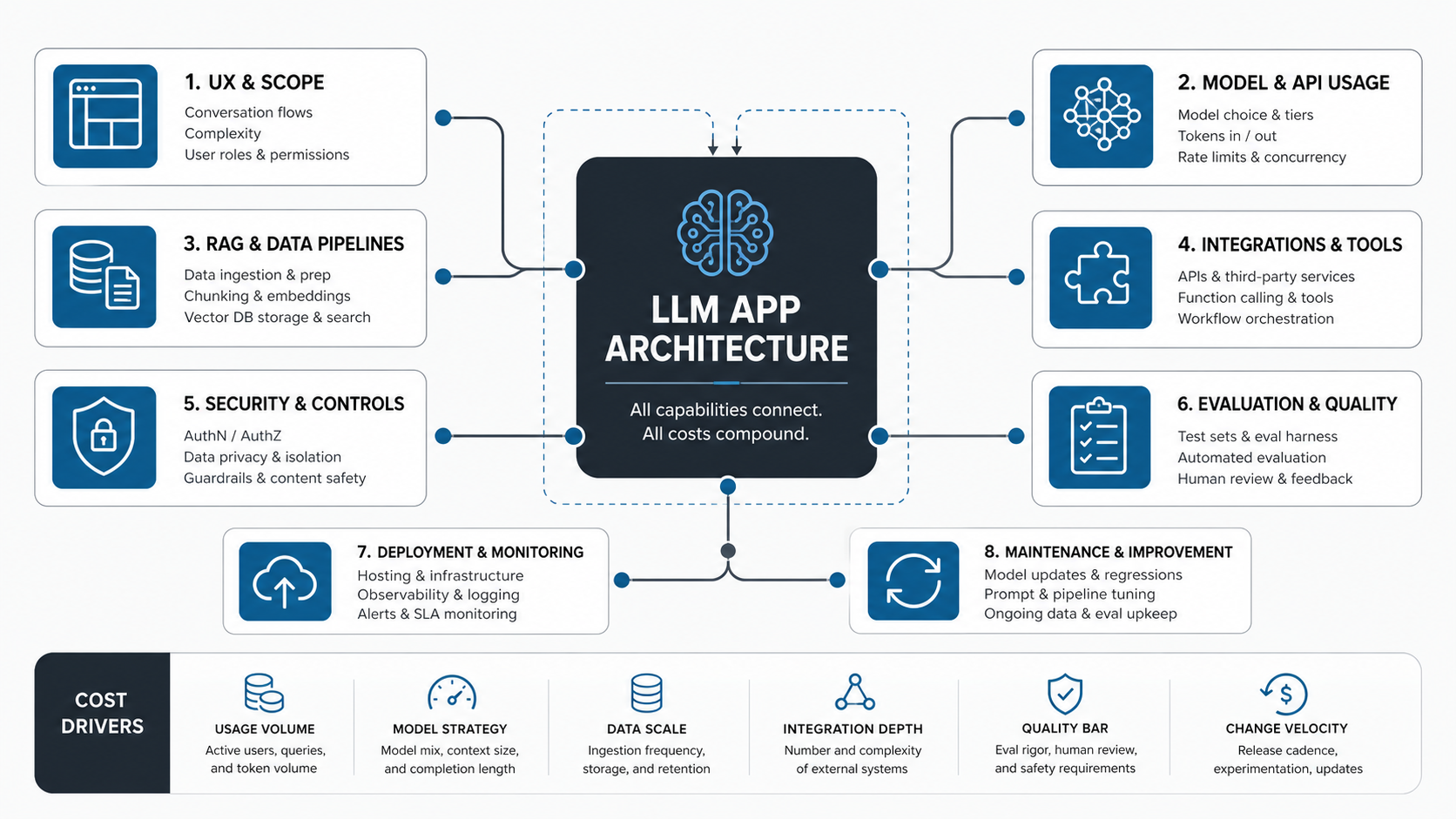
Main Cost Drivers
A useful estimate starts by separating one-time build effort from ongoing operating cost. The build budget covers discovery, UX, architecture, backend work, data pipelines, integrations, evaluation, deployment, and launch. The operating budget covers model/API usage, hosting, monitoring, support, data refreshes, prompt and retrieval improvements, and periodic evaluation.
| Cost driver | What changes the budget | Why it matters |
|---|---|---|
| Use case and UX | Single chat flow, embedded product feature, admin workflow, multi-role app, or customer-facing experience | Defines screens, user states, permissions, acceptance criteria, and support needs |
| Model strategy | One hosted model, multiple models, routing, fallback behavior, context windows, and latency targets | Controls quality, speed, reliability, and recurring token spend |
| RAG and data | Documents, databases, file stores, CRM records, permission filtering, chunking, embeddings, freshness, and citations | Turns a generic model into a business-specific assistant |
| Integrations | Read-only APIs, write actions, CRM, ERP, helpdesk, billing, calendar, data warehouse, or internal admin systems | Requires authentication, mapping, retries, rate limits, logs, and failure handling |
| Security and governance | Role-based access, tenant isolation, secrets, retention, audit trails, human review, and vendor controls | Protects private data and limits unsafe actions |
| Evaluation and QA | Golden datasets, regression tests, retrieval checks, refusal cases, red-team prompts, and human review workflow | Makes quality measurable enough to release and improve |
| Operations | Observability, model cost alerts, support, incident response, model/version changes, and maintenance ownership | Keeps the app dependable after the first launch |
For broader budget planning, the Custom Software Cost Estimator is useful when the LLM app includes a significant product surface, custom backend, admin tooling, or multiple integrations.
Cost Tiers for LLM App Development
LLM app budgets usually climb in tiers as the product moves from prototype to production. The lowest useful tier is the one that proves the business problem with enough quality evidence to justify the next step.

| Tier | Best fit | Typical complexity | Main budget risk |
|---|---|---|---|
| Prompt prototype | Testing a narrow idea with sample prompts and representative inputs | Low | Overreading demo quality as production readiness |
| RAG assistant | Answering or drafting from approved documents, policies, tickets, or product knowledge | Moderate | Retrieval quality, permissions, citations, and content freshness |
| Integrated copilot | Working inside CRM, support, operations, analytics, or SaaS workflows | Moderate to high | API reliability, user roles, state management, and escalation paths |
| Governed platform | Customer-facing or business-critical LLM apps with compliance, audit, monitoring, and version controls | High | Governance, evaluation, observability, support, and change management |
If the application must choose tools, perform multi-step work, or act across systems, compare the scope with AI Agent Development Cost. Many LLM apps are assistants; some become agents once they gain tool use, action permissions, and workflow state.
Model API and Hosting Costs
Model pricing changes frequently, so production estimates should be refreshed from official provider pages before procurement. During this run, the official OpenAI API pricing page, Anthropic Claude pricing documentation, AWS Bedrock pricing page, and AWS Bedrock cost-management guidance were checked for current context. The practical takeaway is stable even when rates change: monthly model cost depends on request volume, prompt length, retrieved context, output length, model choice, caching, batch jobs, evaluation runs, and retry behavior.
Do not estimate model cost from one sample prompt. A production app may add system prompts, user context, retrieved chunks, tool schemas, conversation history, moderation calls, embeddings, reranking, evaluation jobs, and background summaries. A small user-facing response can still require a large internal context window.
Hosting cost may include application servers, databases, queues, vector storage, object storage, logs, tracing, analytics, admin screens, secrets management, and monitoring. If you use a managed model platform, the model provider handles inference infrastructure, but your product still needs reliable software infrastructure around it.
Data, RAG, and Retrieval Costs
RAG is often the difference between a generic chatbot and a useful LLM application. It can also become a major cost driver because it requires source analysis, content cleanup, ingestion, chunking, embeddings, vector search, permission filtering, citation behavior, freshness rules, and evaluation.
The first scoping question is what the app is allowed to know. Public website content is simpler than private documents. Private documents are simpler than live customer records. Live records become more complex when every user needs different access rights. If the app supports multiple tenants, products, languages, or departments, retrieval design should be part of architecture, not a late plugin.
NextPage's AI development services work treats data readiness, workflow fit, latency, security, and cost boundaries as core design inputs. Weak data ownership is not solved by a larger model; it is usually solved by narrowing the corpus, improving the source system, or adding human review.
Integrations, Tools, and Workflow Actions
Integration scope is where LLM apps often become real software projects. Reading from a knowledge base is one level of effort. Reading from Salesforce, HubSpot, Zendesk, Intercom, Stripe, Shopify, Jira, Google Workspace, Slack, an ERP, or a custom database is another. Writing back to those systems raises the bar again.
Every tool action needs authentication, scoped permissions, input validation, idempotency, rate-limit handling, retries, logs, user-visible status, and fallback paths. If an LLM can change customer records, send messages, trigger payments, grant access, or update operational data, human approval and audit trails should be included in the estimate.
For teams still choosing which workflow to automate first, the AI Automation ROI Calculator can help compare time saved and payback potential before committing to deeper integrations.
Security, Governance, and Evaluations
Security and evaluation work should start before the first production pilot. LLM apps need clear data boundaries, prompt and response logging rules, role-based access, tenant isolation where relevant, secret handling, retention rules, abuse prevention, and a plan for sensitive outputs.
Evaluation turns subjective model quality into release criteria. A useful evaluation set includes real examples, expected answers, unacceptable failures, retrieval checks, citation checks, refusal cases, permission-boundary tests, and regression cases after prompt or model changes. Without this, teams are left judging quality from a few happy-path demos.
For generative workflows that affect customers or operations, generative AI development should include prompt design, retrieval design, moderation, evaluations, observability, and human review as first-class build work. Governance is not a PDF attached after launch; it changes what the app is allowed to do.
Maintenance and Ongoing Operations
LLM apps require active maintenance because models, source data, user behavior, integrations, and business policies change. A responsible operating plan should cover data refreshes, prompt updates, model version changes, retrieval tuning, evaluation review, failure triage, spend monitoring, incident handling, and user feedback loops.
Maintenance is also where cost control improves. Teams can reduce spend by trimming context, caching repeated work, choosing smaller models for simpler tasks, batching offline jobs, summarizing long histories, limiting retries, and monitoring token-heavy workflows. These decisions require logs and analytics, so observability should be in scope from the start.
How to Estimate Your LLM App
Use these questions before asking for a quote:
- What workflow should the app improve? Define one primary job before choosing a model.
- Who will use it? List roles, permissions, approval needs, and support expectations.
- What data does it need? Separate public content, private documents, structured records, and live system data.
- What should it produce? Answers, summaries, drafts, classifications, recommendations, or system actions.
- What systems must it connect to? Include read, write, and approval requirements.
- How will quality be measured? Define examples, expected outputs, refusal cases, and review cadence.
- What risks need controls? Include privacy, security, customer impact, operational impact, and rollback paths.
- Who owns it after launch? Assign responsibility for data, prompts, evaluations, cost, and incidents.
These inputs are more useful than asking for a universal price. A narrow RAG assistant and a governed product feature may both be called LLM apps, but they require different architecture, engineering, and operating models.
How NextPage Plans LLM App Builds
NextPage estimates LLM app builds by mapping the workflow, product surface, data boundary, retrieval strategy, model path, integrations, security requirements, evaluation plan, and maintenance owner. The goal is to recommend the smallest reliable version that can prove value while leaving a clean path to production.
Sometimes that means a narrow RAG assistant. Sometimes it means an embedded copilot inside a larger SaaS or internal tool. Sometimes the right first step is a readiness assessment or prototype before deeper integration. If your team is planning a knowledge assistant, customer support copilot, AI-powered product feature, or workflow automation layer, start with the cost drivers above and then scope the version that can be tested with real data and real users.