
Quick Answer: What RAG Development Means
RAG development is the process of building an AI system that retrieves trusted business knowledge before asking a language model to answer, summarize, classify, or take the next workflow step. Instead of relying only on model memory, the application searches approved documents, databases, tickets, product content, policies, or knowledge bases, then gives the model the most relevant context for the current request. In 2026, the business question is no longer whether a vector database can find similar text; it is whether the whole retrieval, permission, evaluation, and monitoring loop can produce answers people can safely use.
For a business, the value is practical: better grounded answers, fresher knowledge, clearer citations, tighter permissions, and a system that can improve as the company updates its content. RAG is not a magic hallucination cure. It is an architecture pattern that has to be designed, tested, monitored, and connected to real workflows. That is why strong LLM development work treats retrieval, evaluation, data ownership, and user experience as one system, and why teams often pair it with broader AI development services when the assistant must connect to product workflows, internal tools, and production support.
When RAG Is the Right Pattern
RAG fits when the answer depends on knowledge that changes, belongs to your company, or must be constrained by policy. Good examples include an internal assistant for SOPs, a customer support bot that answers from approved help content, a sales enablement assistant that retrieves product and pricing context, a legal or compliance research assistant, or a product search experience that needs structured filters and natural language answers.
RAG is less useful when the task is pure generation with no private knowledge, when the source content is too poor to trust, or when deterministic database queries are the better interface. A payroll calculation, for example, should usually be handled by rules and validated data, not an LLM answer. A support explanation that needs relevant policy, account state, and citations is a stronger RAG candidate.
If you are not sure whether the workflow is mature enough, start with an assessment of data access, integration depth, approval rules, and governance. NextPage's AI Agent Readiness Assessment is useful here because many RAG projects fail for workflow reasons before they fail for model reasons.
| Use RAG when... | Use another pattern when... |
|---|---|
| Answers need fresh private knowledge, citations, policy constraints, or searchable institutional context. | The task is deterministic calculation, simple classification, pure content generation, or a workflow better handled by database queries and rules. |
| The corpus can be curated, permissioned, and evaluated against real questions. | The source content is stale, duplicated, inaccessible, or politically unowned inside the business. |
| Users benefit from a conversational or copilot interface that still shows source evidence. | Users need a fixed report, dashboard, approval form, or repeatable transaction screen more than open-ended answers. |
RAG Architecture From Query to Answer
A production RAG system has more moving parts than a chat box. The user query is interpreted, relevant sources are searched, candidate chunks are filtered and ranked, context is assembled, the model generates an answer, and the system checks whether the answer is useful enough to show or route for review. Each step can improve quality or introduce failure.
- Source connectors pull from documents, CMS content, ticketing systems, databases, wikis, storage buckets, SaaS tools, and public pages.
- Ingestion and indexing extract text, split content into chunks, create embeddings, store metadata, and schedule updates.
- Retrieval finds candidate content using vector search, keyword search, hybrid search, filters, or reranking.
- Generation sends the user request, retrieved context, instructions, and policy constraints to the model.
- Evaluation checks relevance, groundedness, citation support, safety, latency, and cost.
- Operations monitor answer quality, content drift, failed retrievals, user feedback, and model spend.
This is why RAG often belongs inside broader generative AI development, not as an isolated prompt experiment. The retrieval layer, product experience, integrations, and monitoring plan determine whether the assistant is dependable enough for daily work.
RAG Architecture Decisions That Change Cost and Quality
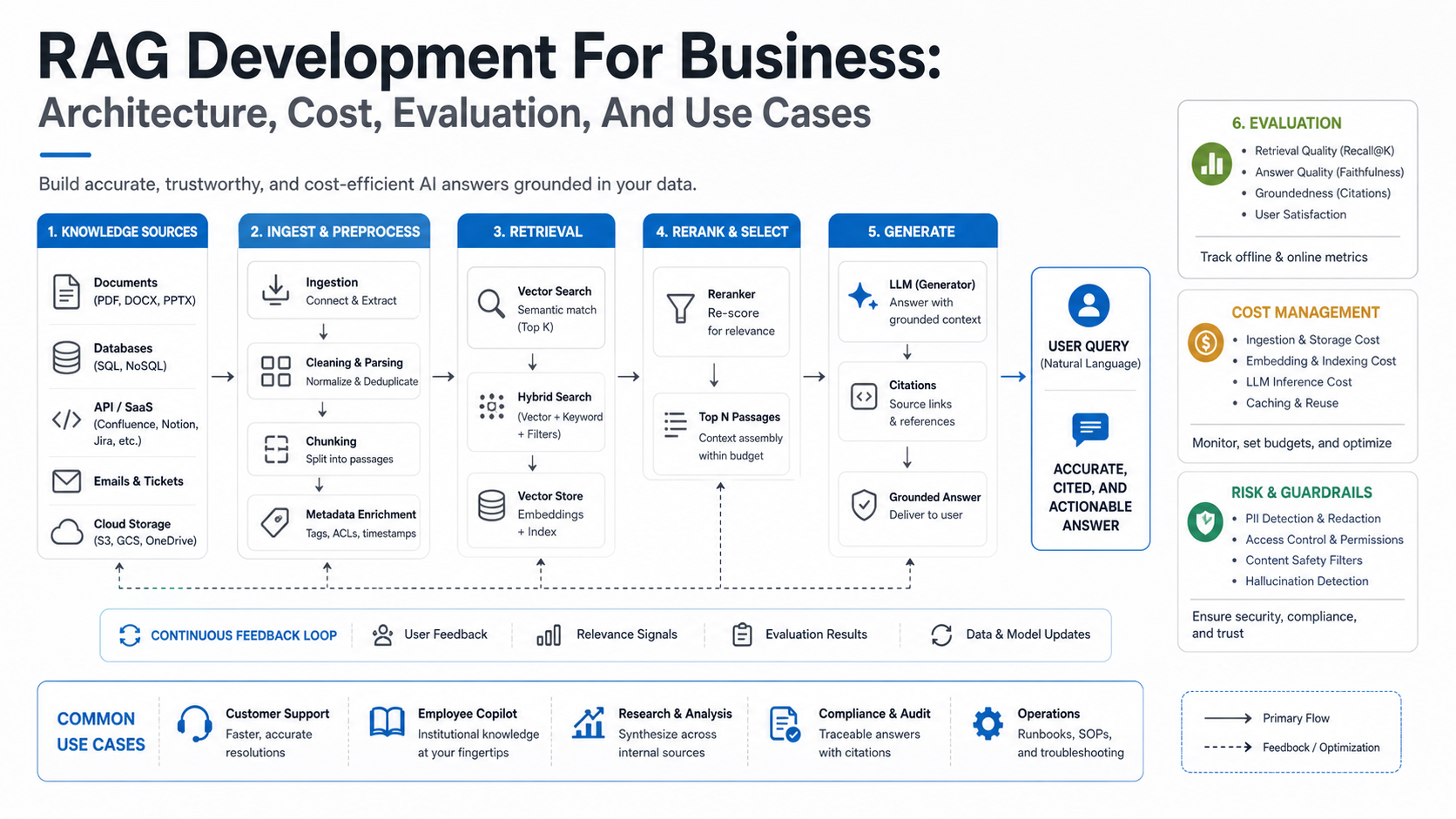
The first major choice is source scope. A broad index gives more coverage but also more noise, higher storage cost, and more permission risk. A narrow index is easier to evaluate but may miss useful answers. Most business systems should start with a curated corpus tied to one workflow, then expand after the team understands answer quality and edge cases.
The second choice is access control. Public documentation can be retrieved with simple filters, but internal systems need row-level, document-level, team-level, or customer-tenant permissions. RAG systems should not retrieve content the user is not allowed to see. This affects connector design, metadata strategy, query filters, audit logging, and test cases.
The third choice is retrieval method. Vector search is good for semantic similarity, keyword search helps with exact product names or codes, hybrid search often performs better in enterprise content, and reranking can improve precision when many candidate chunks are available. The best pattern depends on content type, query style, latency target, and evaluation results.
The fourth choice is evaluation depth. A prototype can use a small hand-reviewed question set. A production system needs a representative evaluation set, recurring quality checks, and examples that cover refusals, missing content, outdated documents, permissions, ambiguous queries, and expected citation behavior. Current RAG guidance from platform docs and evaluation frameworks keeps converging on the same point: reliable systems measure the retriever and the generated answer separately, then use production feedback to improve the corpus, prompts, retrieval configuration, and guardrails.
What Drives RAG Development Cost?
RAG development cost is driven less by the word "RAG" and more by the workflow around it. A narrow assistant that answers from a small set of approved documents is much simpler than a multi-tenant customer support system that reads private account data, updates CRM records, escalates to humans, and needs compliance logs.
| Cost driver | Why it matters | Lower-complexity version | Higher-complexity version |
|---|---|---|---|
| Data sources | Each connector adds extraction, refresh, metadata, and failure handling | One document store or CMS | Multiple SaaS tools, databases, tickets, and files |
| Permissions | Access control must be enforced before retrieval and answer generation | All users can see the same content | Tenant, role, document, and account-level permissions |
| Retrieval quality | Better retrieval needs tuning, metadata, hybrid search, and evaluation | Basic vector search | Hybrid retrieval, filters, reranking, and feedback loops |
| Product workflow | The assistant may need UI, review, approvals, exports, or updates | Read-only Q&A | Actions, handoffs, CRM updates, and human review |
| Operations | Production systems need monitoring, logs, content refresh, and cost control | Manual review after launch | Dashboards, alerts, evals, trace review, and rollback paths |
For early planning, estimate the repeated work first. A RAG assistant that saves a few minutes on rare tasks may not justify the same build as one that supports hundreds of tickets, onboarding questions, sales requests, or analyst lookups every week. The AI Automation ROI Calculator can help frame the volume and savings question, while the Custom Software Cost Estimator is better when RAG is part of a larger app, portal, or internal tool.
RAG Evaluation: What to Measure Before Launch
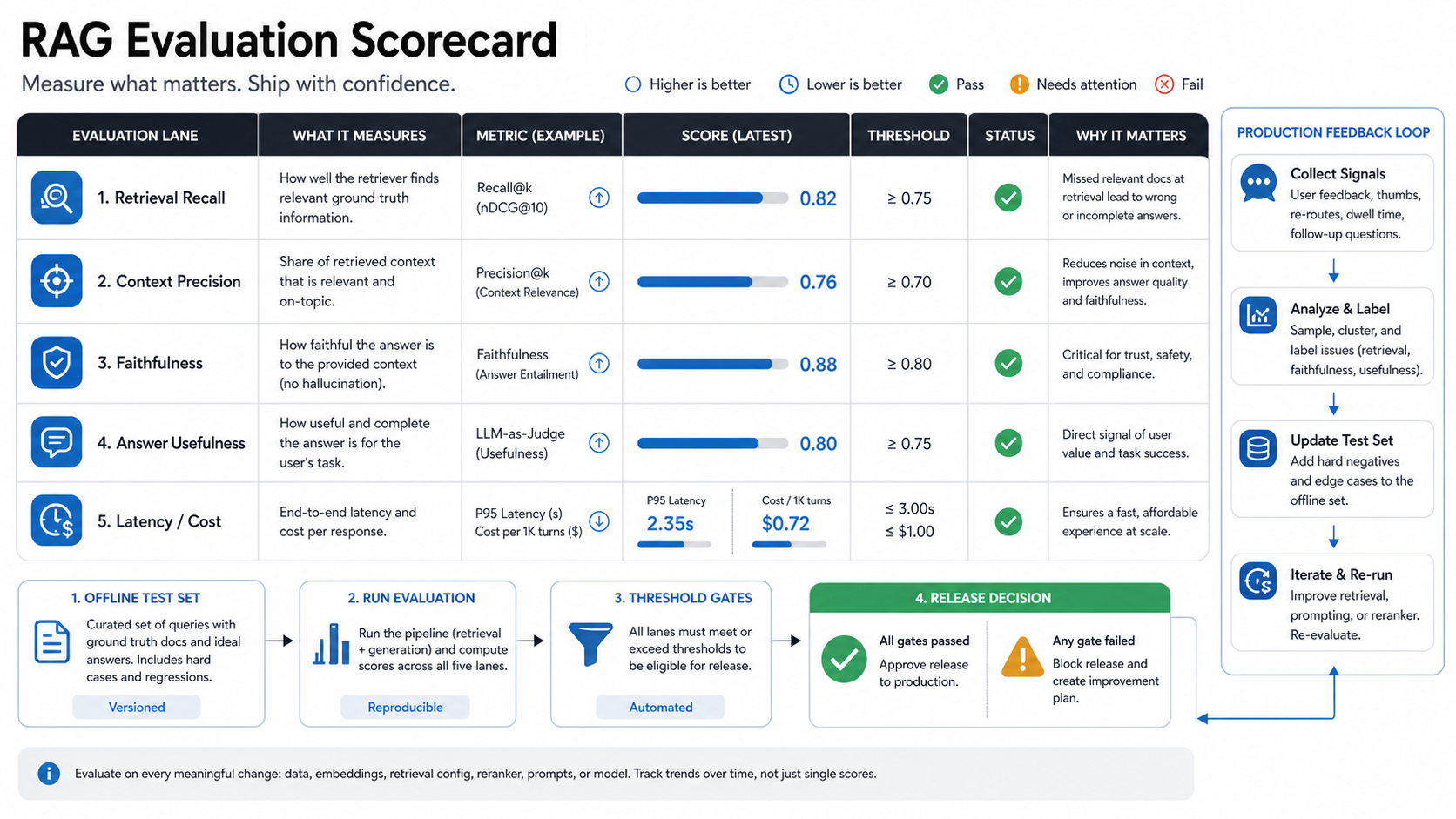
A RAG system should be evaluated before users treat it as reliable. The first question is retrieval quality: did the system find the right source content? If retrieval fails, the model may answer from weak context or refuse a question it should have handled. The second question is groundedness: is the answer supported by retrieved sources? The third question is usefulness: did the response solve the user's task in a clear, complete, and safe way?
A practical evaluation set should include real user questions, expected source documents, accepted answer traits, known hard cases, and examples that should not be answered. It should test stale content, conflicting documents, missing documents, acronyms, permissions, multilingual inputs if relevant, and follow-up questions. For customer-facing workflows, evaluation should also include tone, escalation, and citation clarity. Useful metric families include retrieval recall, context precision, context sufficiency, answer faithfulness, answer relevance, and latency or cost per successful answer.
Evaluation should continue after launch. Track no-result queries, low-rated answers, citation clicks, repeated reformulations, support escalations, latency, token usage, and source freshness. For higher-risk workflows, keep human review in the loop until the system has enough production evidence. If the RAG system is part of a larger LLM product, compare these numbers with the planning assumptions in your LLM app development cost model so retrieval quality, infrastructure spend, and support ownership are reviewed together.
Common Business Use Cases for RAG
Customer support knowledge assistants retrieve help-center content, product documentation, ticket history, and policies to draft answers or resolve common questions. This is a strong fit for AI chatbot development when the bot must answer from approved knowledge instead of generic model memory.
Internal operations copilots help employees search SOPs, HR policies, project documentation, vendor agreements, and training material. These projects often work best when connected to internal tools instead of living as a standalone chat window. If the workflow is highly specific, the same reasoning used in internal tool development applies: build around the repeated business process, not around the novelty of chat.
Sales and account enablement assistants retrieve product facts, implementation notes, past proposals, security answers, and pricing context so teams can respond faster without inventing details. Permissions and freshness matter because old pricing or private customer notes can create risk.
Compliance and policy research can use RAG to surface relevant clauses, policy sections, and evidence for review. These systems should be framed as decision support, not automated legal or compliance authority, unless the organization has a full approval and audit process.
Product and ecommerce search can combine natural language queries with structured filters, product attributes, inventory, and ranking rules. In this case, RAG may sit alongside traditional search, recommendation, and analytics systems.
Knowledge-heavy workflow automation uses RAG to gather evidence before drafting an email, preparing a case summary, routing a request, or suggesting the next operational step. This overlaps with AI workflow automation when the answer must trigger a process instead of stopping at a chat response.
Implementation Roadmap for a Business RAG System
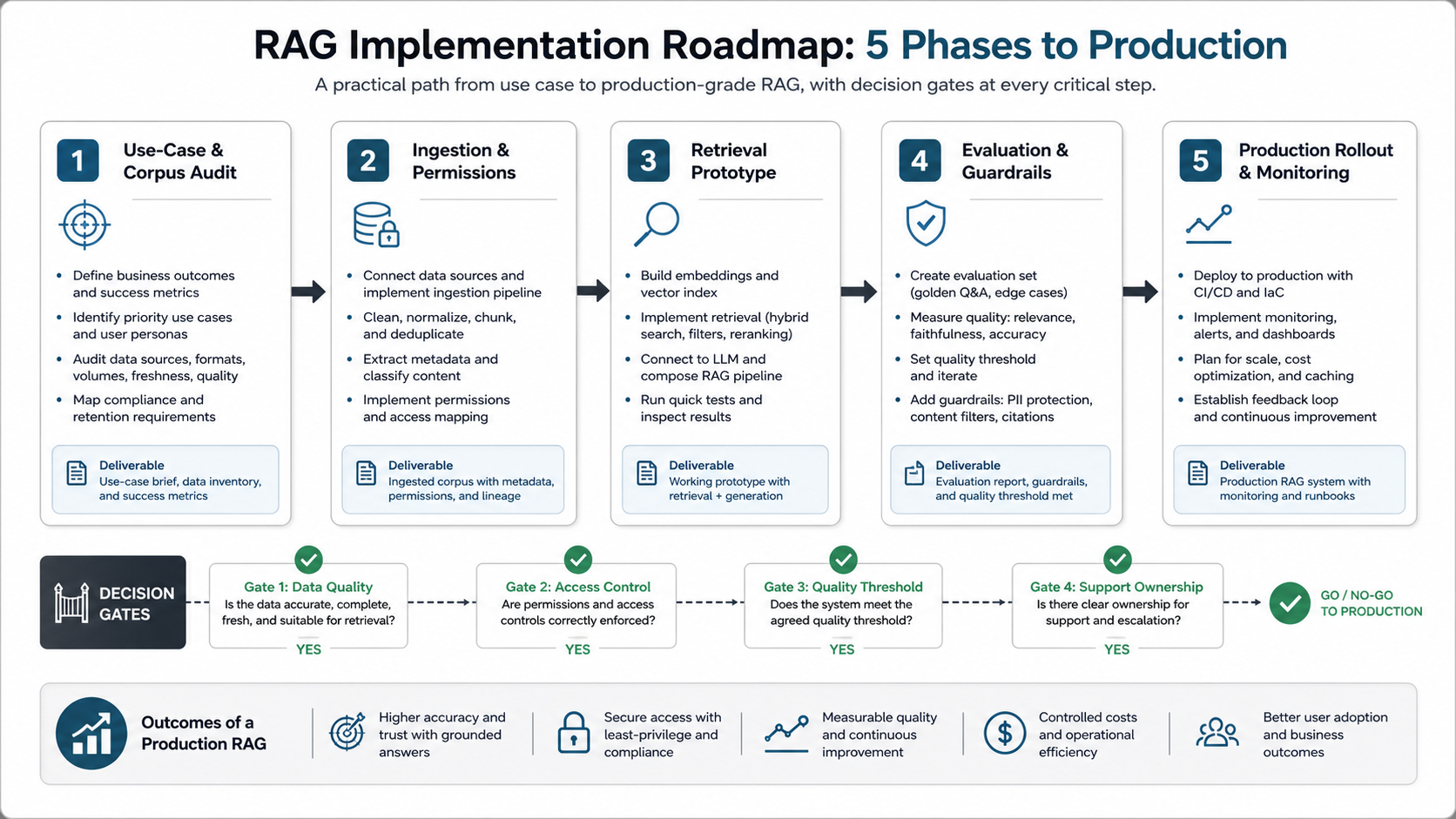
Start with a workflow and a measurable outcome. Define who asks questions, what they need to accomplish, which sources are trusted, what the assistant is allowed to answer, and what must be escalated. A RAG system without a workflow owner becomes a demo; a RAG system tied to a business process can be measured and improved.
Next, audit the content. Identify approved sources, stale documents, duplicates, access boundaries, file formats, ownership, and update frequency. Retrieval quality improves when the source corpus is curated, structured, and tagged. Poor content hygiene cannot be solved only with embeddings.
Then build a prototype with a small but representative question set. Test chunking, metadata filters, hybrid retrieval, citations, and response format. Use the prototype to discover failure modes before integrating too deeply into production systems.
After that, add production controls: authentication, permissions, logging, feedback capture, evaluation jobs, cost monitoring, fallback behavior, and human review. For teams planning broader AI development services, these controls should be part of the first architecture discussion, not an afterthought. If the project will later support planning, action-taking, or multi-step workflows, document the boundary between RAG and agentic AI development services so the first release does not accidentally grant tools, permissions, or autonomy before the evaluation loop is ready.
Questions to Ask Before Hiring a RAG Development Team
- Which data sources will be included first, and who owns their quality?
- How will permissions be enforced before retrieval and generation?
- Will the system use vector search, keyword search, hybrid search, reranking, or a staged retrieval pipeline?
- How will answer quality, groundedness, citation support, latency, and cost be measured?
- What happens when the system does not find enough context?
- How will content updates, deleted documents, and stale answers be handled?
- Which actions require human approval?
- How will logs, feedback, evaluation examples, and model changes be reviewed after launch?
How NextPage Approaches RAG Development
NextPage treats RAG as a product and systems problem, not just a model integration. The work usually starts with workflow discovery, source mapping, data and permission design, prototype evaluation, interface design, production integration, monitoring, and continuous improvement.
The safest first version is usually narrow: one workflow, approved sources, clear user roles, measurable questions, and limited actions. Once the system reliably retrieves useful context and handles failures honestly, it can expand into more sources, richer workflows, agentic actions, or customer-facing automation.
If your team is planning a knowledge assistant, customer support RAG bot, internal search assistant, or LLM-powered workflow, NextPage can help turn the idea into an implementation plan: what to connect first, how to evaluate quality, where human review belongs, and what architecture gives the clearest path to business value. Teams comparing build scope can also review the generative AI development cost guide before estimating the first release.