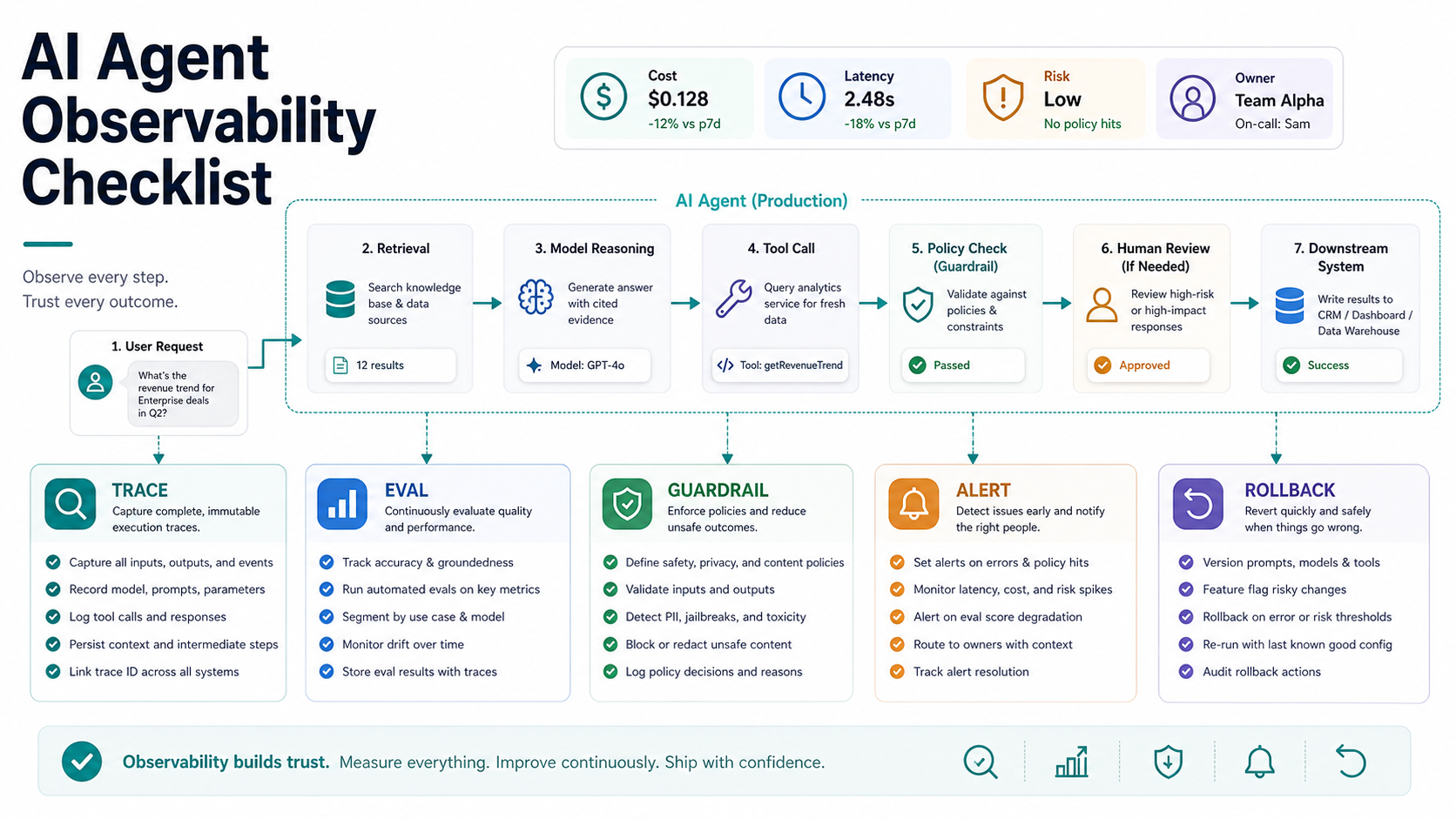

AI agent observability is the evidence system that shows what an agent planned, which data it used, which tools it called, what it changed, what it cost, whether the result passed evaluation, and how the team can stop or roll back the workflow when risk increases. A production agent should not be approved because a demo worked. It should be approved because every important decision and action is visible enough to debug, govern, improve, and reverse.
This checklist is for CTOs, product leaders, AI transformation owners, engineering managers, and operations teams preparing agents for real customers, employees, or revenue workflows. It assumes the agent can use tools, retrieve data, call APIs, draft or update records, and sometimes ask for human review. That is exactly where ordinary logs stop being enough. If your team is still comparing agent types and risk levels, pair this checklist with NextPage's agentic AI business use cases guide before giving an agent production write access.
If your team is still deciding which workflow should become the first production agent, start with the AI Agent Readiness Assessment. If the workflow is already selected, use this guide to define the observability plan before launch, not after the first incident.
The Short Checklist Before An Agent Goes Live
A production AI agent needs observability across three layers: software telemetry, AI behavior, and business controls. Software telemetry tells you whether requests are fast, available, and error-free. AI behavior tells you whether the agent chose the right context, prompt, model, tool, and action. Business controls tell you whether the workflow stayed inside approved limits. This is especially important for AI agent development, where observability has to cover orchestration, permissions, evaluations, and rollback rather than only model latency.
| Checklist Area | What To Capture | Production Question It Answers |
|---|---|---|
| Trace | Request, plan, model call, retrieval, tool call, action, response | Where did this run succeed, fail, or drift? |
| Evaluation | Expected answer, actual answer, rubric score, safety result, regression tag | Is quality stable enough to release? |
| Guardrail | Policy check, permission, blocked action, approval state, override reason | Did the agent stay inside allowed boundaries? |
| Operations | Latency, cost, token use, provider, timeout, retry, queue depth | Can the workflow run reliably at volume? |
| Incident | Owner, alert, sample run, audit packet, rollback version, customer impact | Can the team respond and recover quickly? |
The goal is not to collect every possible field. The goal is to make every high-risk agent decision explainable and every harmful action stoppable. NextPage treats this as part of generative AI development, not an add-on dashboard at the end of the build.
Why AI Agent Observability Is Different From App Monitoring
Traditional application monitoring usually follows a request through services, databases, queues, and external APIs. That still matters, but agents add another layer: probabilistic decision-making. A single request may include a planner step, multiple model calls, retrieval from private knowledge, tool selection, permission checks, retries, and a final action in another system.
When a standard web app fails, engineers often look for an exception, latency spike, failed dependency, or bad deployment. When an agent fails, the root cause may be semantic. The retrieval step may have selected the wrong policy. The prompt may have hidden a required constraint. The model may have called the right tool with the wrong argument. A guardrail may have blocked an action but failed to notify the user. A human reviewer may have approved an action without seeing the risky evidence.
That is why agent observability must combine traces, evaluations, guardrails, and workflow ownership. It should explain both how the software executed and why the agent behaved the way it did.
Design The Trace Around Agent Decisions
A useful trace should read like a replayable story of the run. Start with the user request and correlation ID. Capture the workflow version, prompt version, model, provider, retrieval query, retrieved chunks, tool list, selected tool, tool arguments, permission checks, output, cost, latency, and final action. If a human intervened, record the reviewer, decision, and visible evidence.
Use structured spans instead of one large text log. OpenTelemetry's GenAI semantic conventions are an important reference because they give teams a shared way to represent model and agent activity. Even if your first implementation uses a framework tool such as LangSmith, Langfuse, Arize, Helicone, or an APM vendor's AI observability feature, the data model should remain portable enough to connect with your broader monitoring stack.
For a LLM development project, NextPage usually separates these trace spans: intake, classification, policy lookup, retrieval, model call, tool-call proposal, permission check, tool execution, validation, human review, final response, and writeback. The exact names matter less than the consistency. Every agent run should be searchable by workflow, customer, environment, model, prompt version, tool, risk level, and release version.
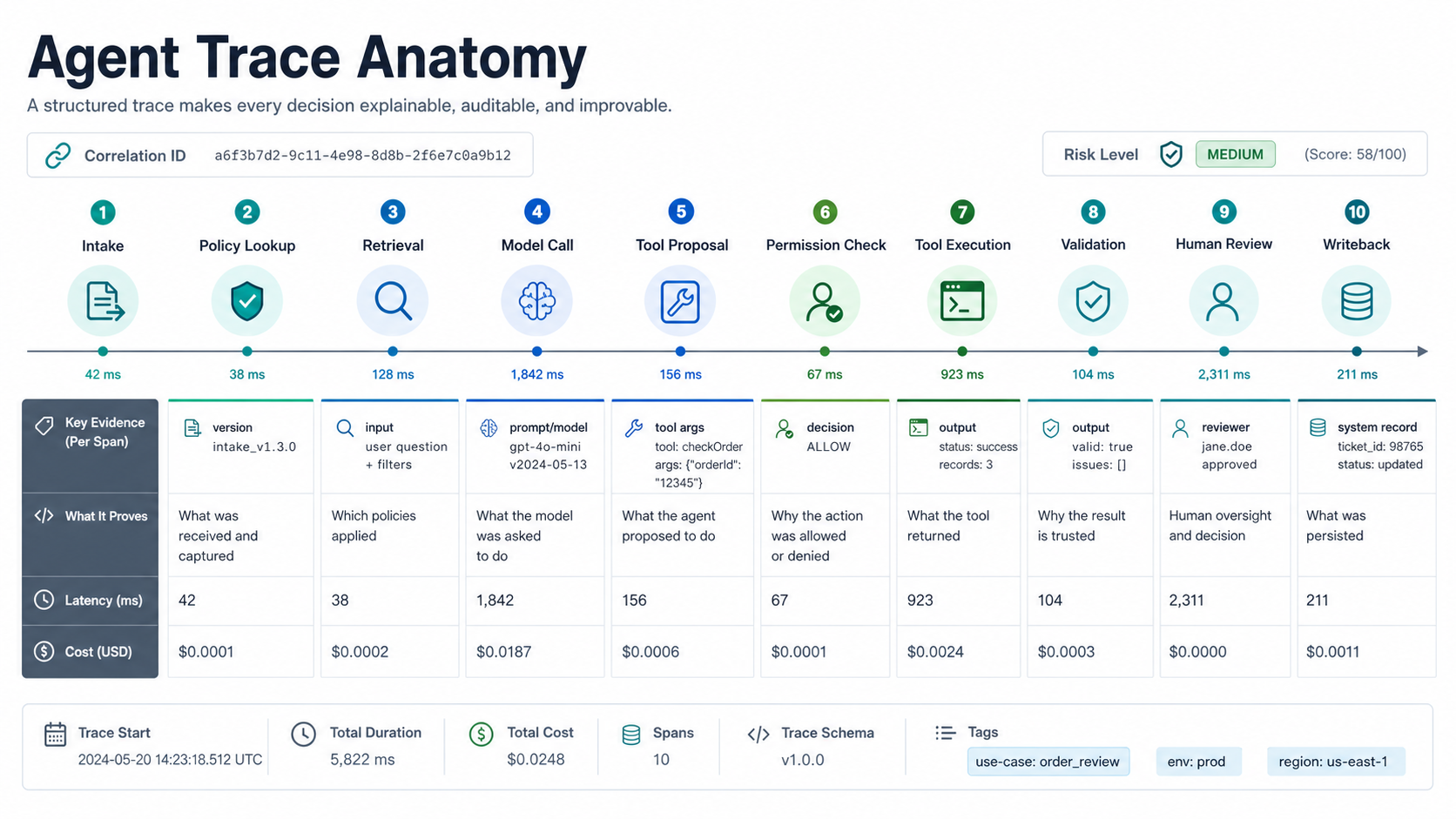
Agent Trace Anatomy: What Each Span Should Prove
A trace should do more than prove that a run happened. It should show what the agent believed, what it was allowed to do, what evidence it used, what it proposed, what was executed, and what changed downstream. That makes the trace useful for debugging, evaluation review, governance, customer support, and incident response.
| Span | Evidence To Keep | Why It Matters |
|---|---|---|
| Intake | Request, user role, workflow, environment, correlation ID. | Connects the agent run to a real business context. |
| Retrieval | Query, source list, selected chunks, freshness, access rules. | Shows whether the agent used the right knowledge. |
| Model call | Prompt version, model, provider, parameters, input/output hashes. | Supports regression analysis after prompt or model changes. |
| Tool proposal | Tool name, sanitized arguments, confidence, risk level. | Separates reasoning from execution before side effects occur. |
| Permission check | Policy decision, allow/deny reason, reviewer requirement. | Proves whether governance rules were applied. |
| Writeback | Target system, record ID, before/after state, rollback path. | Lets teams reverse or remediate unsafe actions. |
For domain-specific LLM development, this trace model also helps decide whether a RAG system, small model, agent, or rules-based workflow is the simplest controlled architecture.
Build Evaluations Before Expanding Traffic
Observability tells you what happened. Evaluations tell you whether what happened was acceptable. A production agent should have a small but serious evaluation suite before launch. Include successful examples, hard edge cases, policy-sensitive requests, ambiguous requests, retrieval failures, tool-call failures, and expected refusal cases.
Use at least four evaluation types. First, task success: did the agent complete the workflow correctly? Second, factual grounding: did it use the approved source or database record? Third, safety and policy: did it avoid prohibited actions, private data leakage, or unsupported claims? Fourth, operational quality: did it stay within latency and cost limits?
Do not hide evaluation inside a spreadsheet that no one checks. Store evaluation results with versioned prompts, models, retrievers, tools, and datasets. A model change, prompt edit, tool schema change, or new knowledge base should trigger regression checks. The post-launch feedback loop should promote real incidents and bad user outcomes into future eval cases.
Use Evaluation Gates Before Autonomy Expands
Autonomy should expand only when evaluation evidence supports it. A staged gate prevents teams from treating one successful demo as production readiness. Start with offline evals, move to shadow mode, require human approval for live traffic, then allow limited autonomy only for low-blast-radius actions with rollback already tested.
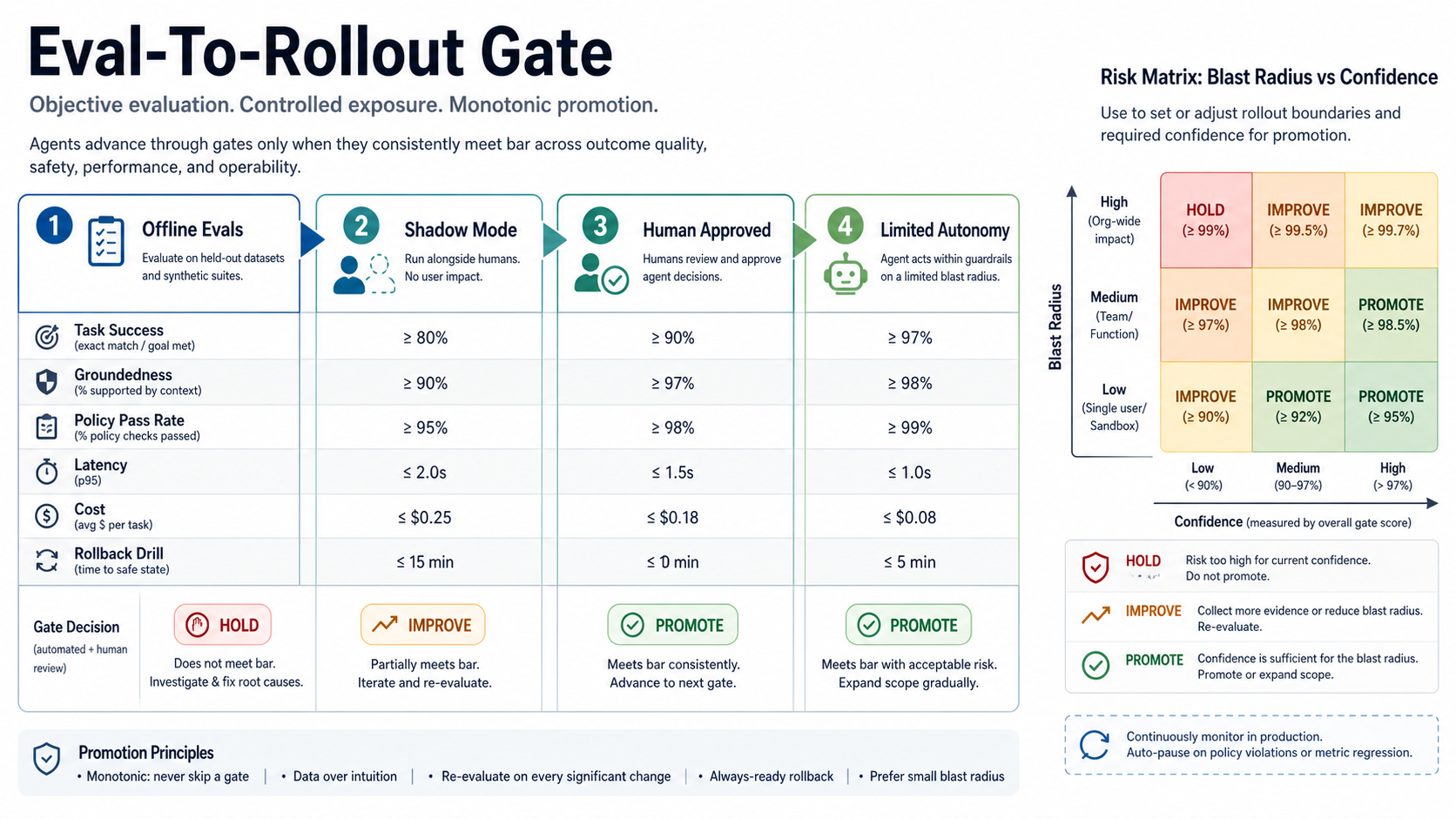
Do not measure quality with one score. Track task success, groundedness, policy pass rate, latency, cost, review load, and rollback drill time. If the agent touches QA, release, or test evidence, compare the same governance pattern with the AI-powered QA automation roadmap so model-assisted test work remains reviewable and auditable.
| Gate | Promotion Evidence | Stop Condition |
|---|---|---|
| Offline evals | Representative cases pass quality, grounding, safety, and cost targets. | Weak coverage, brittle prompts, or unsupported outputs. |
| Shadow mode | Agent proposals match or improve human decisions without user impact. | High disagreement, slow review, or risky false positives. |
| Human approved | Reviewers can approve quickly with enough trace evidence. | Reviewer backlog, unclear evidence, or repeated policy exceptions. |
| Limited autonomy | Low-risk actions remain inside thresholds with rollback proven. | Metric regression, bad writeback, or unclear ownership. |
Instrument Guardrails And Human Review
Guardrails are only useful if the team can see when they fire, why they fire, and what happens next. Log policy checks as first-class events. Record the policy name, input category, allowed action, blocked action, reviewer path, and user-facing explanation. For high-risk workflows, require the agent to produce an evidence packet before a human approves an action.
This is where agent observability overlaps with enterprise AI agent governance. Governance defines who owns the workflow, what permissions the agent has, which actions need review, and what rollback means. Observability proves whether those rules were followed in production. For high-risk AI systems or regulated workflows, connect these events to an AI compliance readiness checklist so evidence retention, oversight, and documentation requirements are designed early.
Human review should not become a vague approval button. The reviewer needs the original request, retrieved evidence, proposed action, policy warnings, affected system, customer or record ID, and rollback option. If the reviewer does not have enough context to make the decision, the agent should not be allowed to treat approval as risk transfer.
Define Alerts Around Business Risk, Not Only Errors
An agent can return HTTP 200 and still fail the business. Alerting should cover software failures and AI-specific failures. Examples include tool-call error rate, repeated retries, policy-block spikes, high-cost runs, low evaluation confidence, empty retrieval, unexpected model fallback, writeback failures, reviewer backlog, and customer-impacting rollback events.
Every alert needs an owner and a runbook. If the agent writes to CRM, finance, support, inventory, or operations systems, the owner may be a product operations team rather than only an SRE. The runbook should include where to find the trace, how to compare the run with nearby failures, how to disable the workflow, and how to notify affected stakeholders.
Use the same discipline you would apply in a cloud performance audit checklist: collect the right evidence, separate symptoms from root causes, and define remediation steps before scale hides the signal.
Create A Rollback Plan Before Launch
Rollback for agents is more complex than redeploying an older build. You may need to roll back a prompt, model, retrieval index, tool schema, policy file, connector permission, evaluation dataset, feature flag, or workflow route. You may also need to reverse a downstream action that the agent already took.
Define rollback levels before production. Level one can disable a risky tool or move the workflow into human-review-only mode. Level two can revert prompt, model, or retrieval changes. Level three can disable the whole agent workflow. Level four can trigger customer remediation, data correction, or incident communication.
Each rollback level needs a measurable trigger. For example, disable autonomous writeback when tool-call validation failures cross a threshold, when policy blocks spike after a release, when evaluation confidence drops below the approved band, or when a sensitive workflow produces a confirmed bad action. The decision should not depend on a late-night debate about whether an agent is "probably fine."
Keep A Rollback Runbook For Agent Incidents
An agent rollback runbook should define the trigger, owner, action, communication path, and evidence packet before an incident. The runbook is not only for catastrophic failure. It should also cover quality drift, reviewer backlog, policy-block spikes, cost surges, repeated tool failures, and bad writebacks.
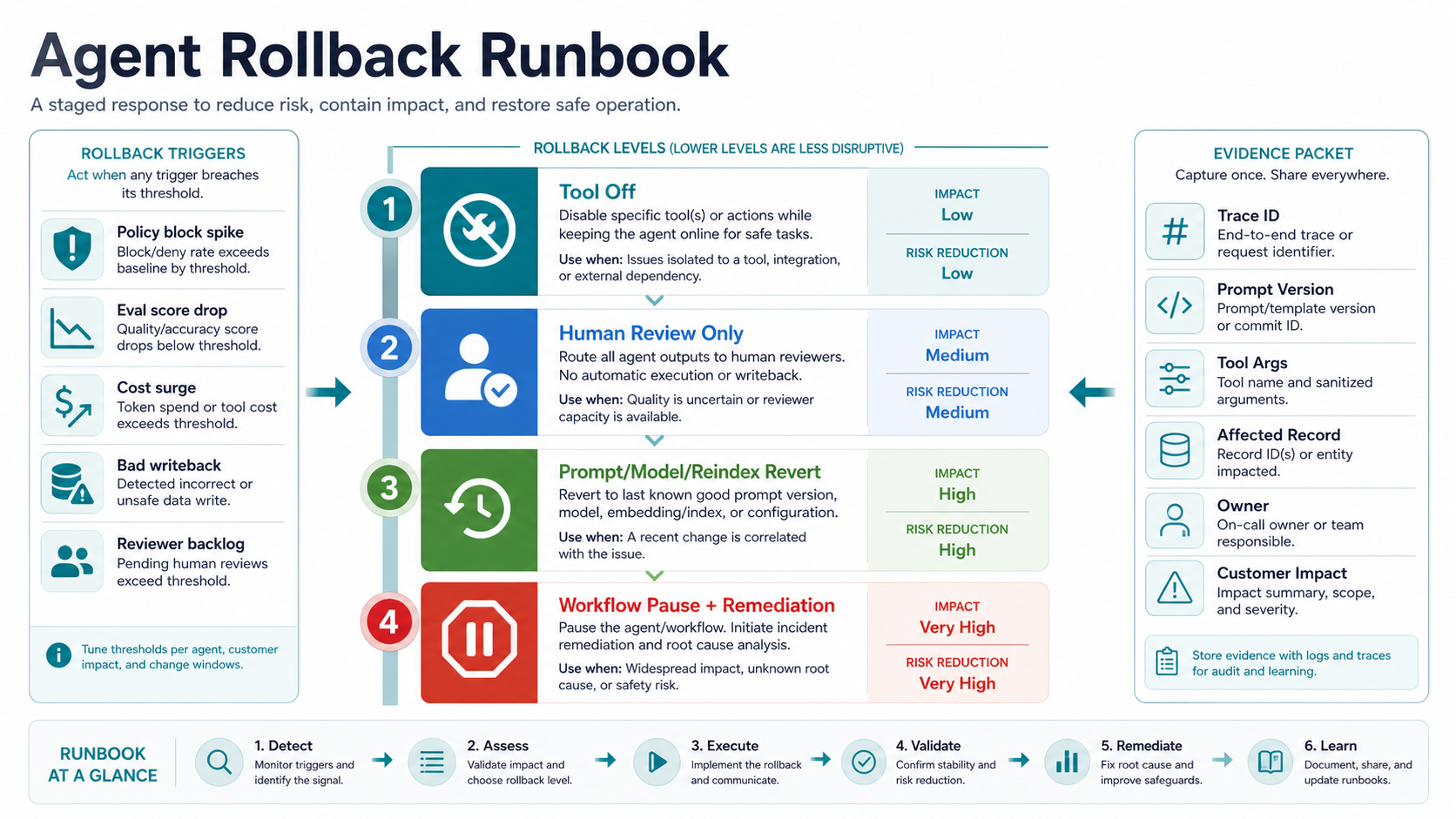
Store the trace ID, prompt version, tool arguments, affected record, owner, customer impact, and remediation decision in one packet. That packet helps engineering debug the run, product decide the customer response, support explain impact, and compliance confirm what was reviewed. The same rollback logic should also appear in generative AI vs AI agents vs agentic AI architecture decisions because the operating model changes as autonomy increases.
Choose Tools That Preserve Evidence
Agent observability tooling can come from framework-native tracing, OpenTelemetry instrumentation, APM vendors, evaluation platforms, guardrail services, or a custom data pipeline. The right choice depends on your stack, risk, compliance needs, and existing operations model.
Ask these questions before selecting tools:
- Can the tool show a full agent run with prompts, retrieval, tool calls, policy checks, outputs, cost, and latency?
- Can it redact or protect sensitive data while still preserving enough evidence to debug?
- Can eval results be tied to prompt, model, retriever, and tool versions?
- Can alerts route to the teams that own the workflow?
- Can data export or OpenTelemetry support prevent vendor lock-in?
- Can incidents produce a shareable evidence packet for engineering, product, support, and compliance?
For many teams, the best first architecture is not a giant observability migration. It is a thin structured trace layer, a small eval suite, clear policy events, and integration with the monitoring and incident tools the team already uses. If the agent is part of broader AI workflow automation, keep the observability schema tied to the business workflow rather than reporting model activity in isolation.
Use A Staged Launch Sequence
Do not launch an agent straight from prototype to broad autonomy. Start with offline evaluation, then shadow mode, then human-approved production, then limited autonomous actions, then broader rollout. Each stage should have promotion criteria.
In shadow mode, the agent observes real requests but does not take final action. Compare its proposed action with human decisions. In human-approved production, measure review load, false positives, false negatives, and time saved. In limited autonomy, allow only low-risk actions with strong rollback. Broader autonomy should wait until traces, evals, alerts, and incident workflow are boring enough to trust.
The Workflow Automation Opportunity Finder is useful when a team has too many candidate workflows. Pick the workflow with clear rules, available data, low blast radius, and measurable value before adding a high-risk agent to a messy process.
How NextPage Builds Agent Observability Into Delivery
NextPage treats observability as part of the agent architecture. In an AI development services engagement, we define the workflow owner, risk level, tool permissions, trace schema, eval dataset, alert map, and rollback plan before production launch. That keeps the team from shipping an agent that works only when the original developer is watching the console.
For new builds, we can design the agent workflow, connect tools, build the trace and eval layer, and prepare the launch runbook. We can also connect agent observability with generative AI development, LLM architecture, QA automation, cloud monitoring, and governance work so the evidence model survives beyond the first pilot. For existing pilots, we can run an observability review: inspect prompts, retrieval, tools, logs, permissions, evaluation coverage, incident readiness, and business metrics. The output is a practical roadmap for what to instrument, what to block, and what to improve before expanding usage.
The best agent systems are not the ones with the most dashboards. They are the ones where the team can answer five questions quickly: what happened, why did it happen, was it allowed, who owns the response, and how do we roll it back?
Final Production Readiness Checklist
- Every agent run has a correlation ID and trace that covers prompt, retrieval, tool calls, policy checks, output, cost, and latency.
- Evaluation datasets cover successful, failed, risky, ambiguous, and regression cases.
- Guardrails log both blocked and allowed sensitive actions.
- Human reviewers see enough evidence to approve or reject the proposed action responsibly.
- Alerts cover quality, policy, cost, latency, retries, tool failures, and reviewer backlog.
- Rollback can disable tools, revert prompts or models, pause the workflow, and remediate downstream actions.
- Incident packets can be shared across engineering, product, support, operations, and compliance.
- Owners know which metrics decide whether the agent advances from pilot to production.
If this checklist feels heavy, the workflow may not be ready for autonomy yet. Narrow the scope, reduce permissions, add human review, and build observability around the first high-value path. That is usually faster than repairing trust after an agent acts without evidence.