
Quick Answer: A Realistic GenAI Implementation Timeline
A realistic generative AI implementation timeline usually runs in phases: discovery, prototype, MVP, production hardening, launch, and scale. In 2026, the best timelines also reserve time for evaluation datasets, LLM security controls, observability, cost monitoring, and governance evidence before a pilot becomes a production workflow. A narrow AI feature can move in a few weeks when the workflow is clear and the data is ready. A production RAG system, internal copilot, or AI agent connected to business tools often needs two to four months before a controlled rollout. Enterprise programs with several teams, strict compliance, private deployment, and reusable AI platforms should be planned as a multi-quarter roadmap.
The timeline is not only an engineering estimate. It depends on buyer inputs: who owns the workflow, which data sources are trusted, which systems need integration, what humans must approve, what risks are unacceptable, and how success will be measured after launch. NextPage plans generative AI development around those operating realities before choosing prompts, models, RAG, fine-tuning, or agentic automation.

Timeline By Phase: What Happens And When
Use the ranges below as planning bands, not a vendor guarantee. Market references often frame expectations around discovery sprints, RAG/chatbot production, fine-tuning, autonomous agents, and enterprise platforms. The useful takeaway is that architecture, data, integrations, evaluation coverage, and governance change the timeline more than the chat interface does.
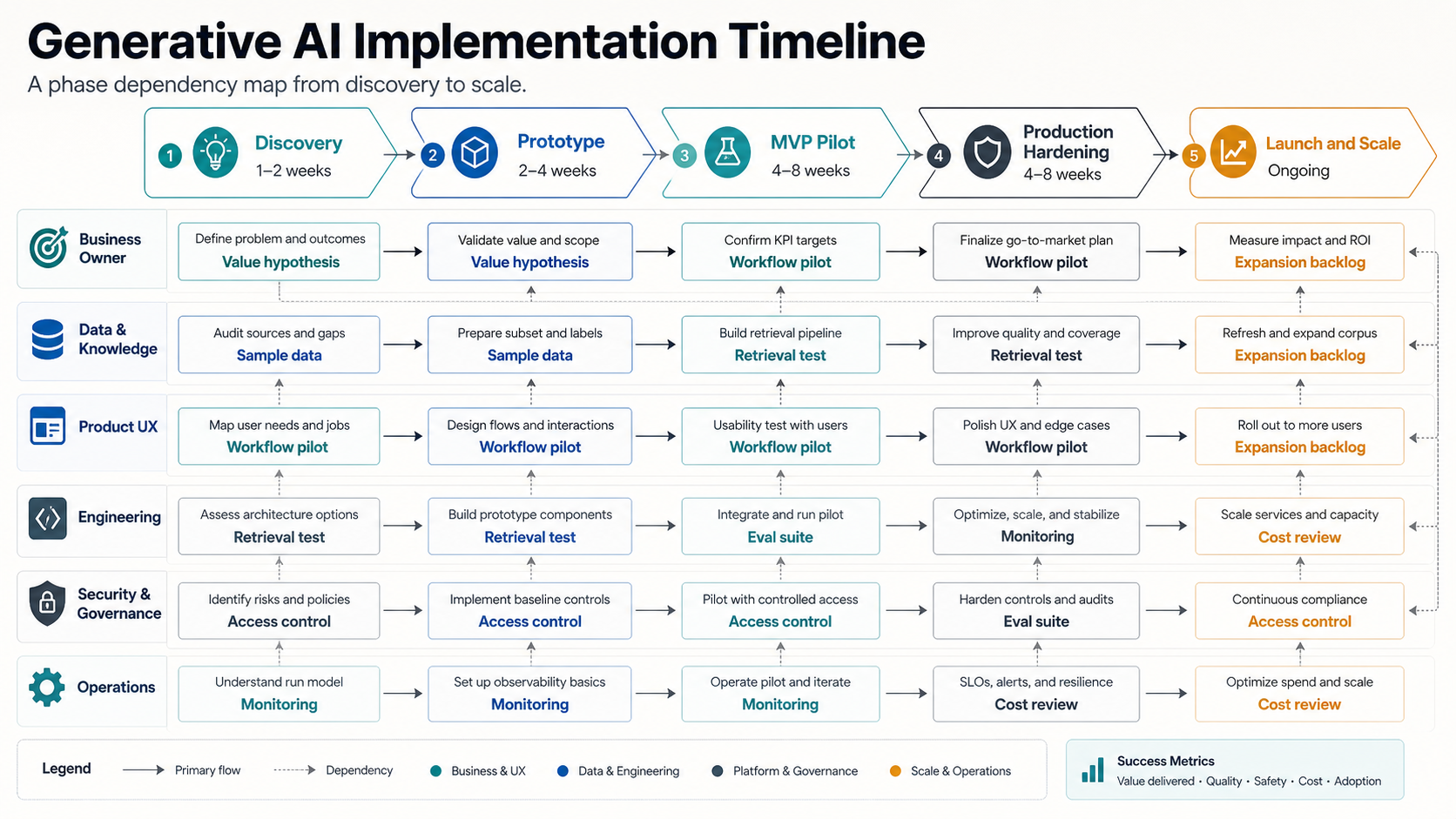
| Phase | Typical Duration | Main Output | Buyer Inputs Needed |
|---|---|---|---|
| Discovery and readiness | 1-3 weeks for a narrow workflow; 4-6 weeks for broader discovery | Use-case brief, ROI hypothesis, data audit, risk map, architecture recommendation | Workflow owner, sample data, system access map, success metric, constraints |
| Prototype | 1-3 weeks | Clickable or functional proof using real examples and a small evaluation set | Representative prompts, documents, edge cases, reviewers, decision criteria |
| MVP and pilot | 4-10 weeks depending on integrations | Authenticated workflow, curated data pipeline, basic admin controls, feedback loop | Pilot users, role rules, integration access, acceptance criteria, support owner |
| Production hardening | 2-6 weeks after MVP scope stabilizes | Security controls, evaluation suite, audit logs, monitoring, rollback and escalation paths | Security review, compliance requirements, data retention policy, launch gate owners |
| Launch and scale | Ongoing; first expansion often starts 4-8 weeks after pilot | Adoption plan, cost monitoring, quality reviews, new workflow backlog, governance cadence | Usage targets, KPI dashboard, training plan, roadmap priority, operating budget |
If you need a broader delivery frame, compare this phased timeline with NextPage's AI implementation roadmap. The roadmap question is what to build first. The timeline question is what evidence must exist before moving to the next gate.
2026 Governance And Evaluation Context
Recent GenAI implementation planning should treat evaluation and governance as delivery work, not post-launch documentation. NIST AI 600-1, the Generative AI Profile for the AI Risk Management Framework, gives teams a structured way to identify and manage risks such as confabulation, data privacy, information security, human-AI configuration, and value-chain dependencies. OWASP's 2025 LLM application risks reinforce the need to plan for prompt injection, sensitive information disclosure, supply-chain issues, data/model poisoning, improper output handling, excessive agency, and system prompt leakage before launch.
Production guidance from major cloud AI platforms points in the same direction: run evaluations against test data before deployment, monitor quality and safety after deployment, track token consumption, latency, error rates, and quality scores, and alert owners when outputs fail thresholds. That is why a serious GenAI timeline needs an evaluation set, human-review model, observability plan, rollback path, and operating owner before the rollout expands.
Phase 1: Discovery And Readiness
Discovery decides whether the GenAI idea is worth building and what the first release should prove. The team maps the workflow, users, data sources, current tools, failure modes, expected ROI, and approval boundaries. This phase should produce a build/no-build recommendation or a narrowed MVP scope.
Useful discovery outputs include a workflow map, data-source inventory, integration list, risk register, quality bar, sample prompts, expected answer examples, initial architecture decision, and delivery estimate. Teams should also estimate value with a practical tool such as the AI Automation ROI Calculator before funding a larger build.
Many delays start here because teams discover that data ownership is unclear, documents are stale, APIs are not available, or nobody can define what a good answer looks like. The enterprise AI readiness checklist is useful before discovery because it forces early clarity on data, workflow, security, governance, and operating ownership.
Phase 2: Prototype And Feasibility
A prototype is not a production app. It is a fast way to prove whether the model, retrieval approach, prompts, data, and user experience can solve the selected workflow. The prototype should use realistic examples, not only happy-path demo content.
For a document assistant, this may mean testing retrieval quality against a small corpus with known answers. For a sales copilot, it may mean generating account briefs from CRM notes and approved messaging. For a support assistant, it may mean classifying tickets, drafting responses, and showing when escalation is required. If the project could become an AI agent rather than a content assistant, compare the scope with generative AI vs AI agents vs agentic AI before estimating the pilot. For an agentic workflow, it may mean a sandboxed tool-use demo with human approval before any system is updated.
The prototype ends with evidence: sample outputs, failure categories, latency and cost notes, reviewer feedback, and a clear decision on whether to continue, narrow, or stop. A prototype that disproves a weak idea is successful because it prevents a larger implementation mistake.
Phase 3: MVP Build And Controlled Pilot
The MVP turns the prototype into a usable workflow for a limited audience. This is where the real product work begins: authentication, role-aware access, data ingestion, prompt and retrieval management, UI states, feedback capture, logging, and integration with the systems where work actually happens.
For many GenAI projects, the MVP is a RAG system, internal copilot, document workflow, customer-support assist, sales or operations assistant, or a constrained AI agent. The goal is not to automate everything. It is to prove that a defined user group can get measurable value while the system remains reviewable and recoverable.
When the workflow crosses systems, treat it as AI workflow automation, not a chatbot skin. The MVP should make handoffs, approvals, integration failures, and exception queues visible. If the system changes records or drafts actions, humans need clear review controls before the build moves beyond pilot.
Phase 4: Production Hardening
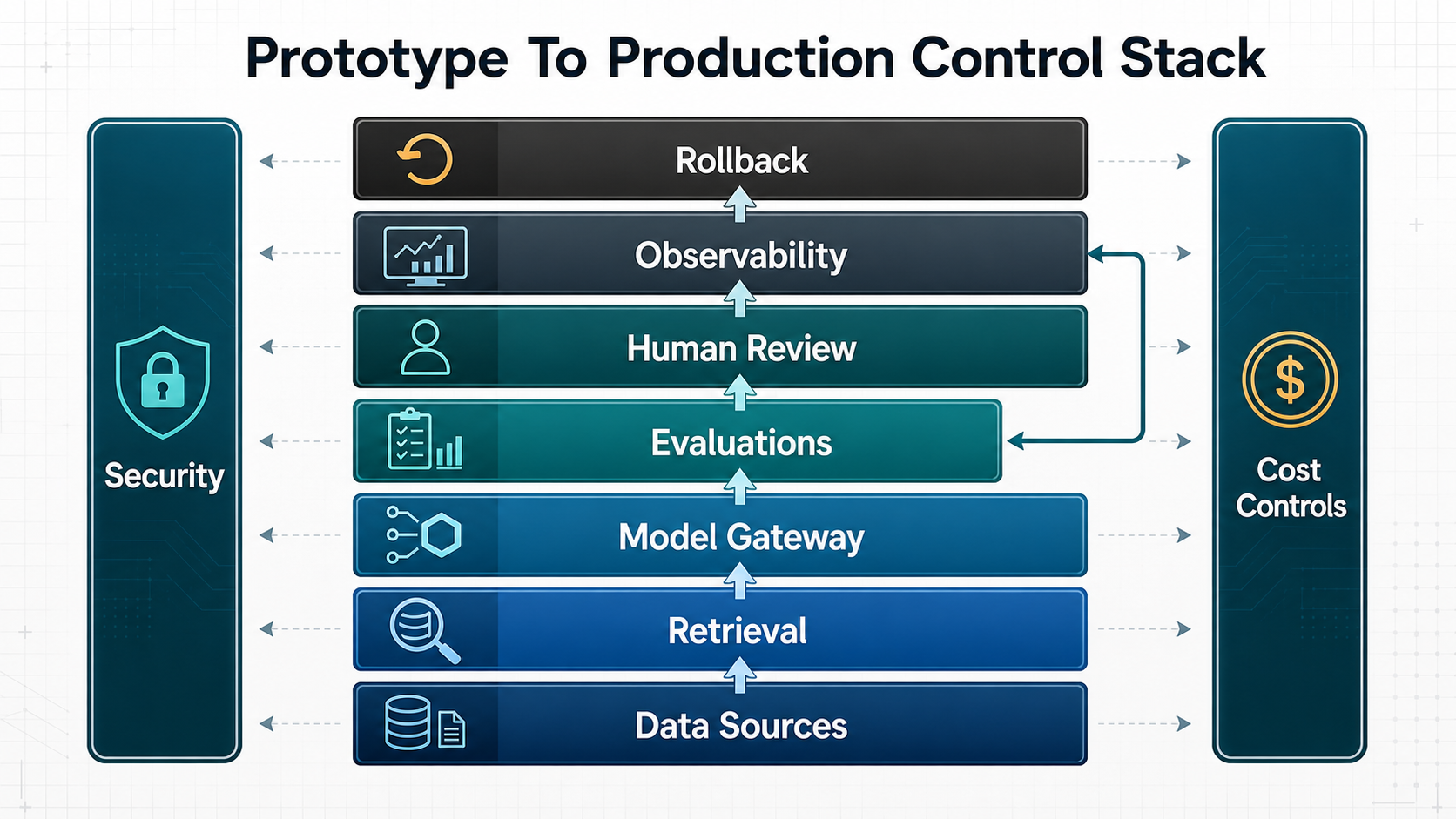
Production hardening makes the MVP safer to operate. This phase adds evaluation coverage, regression checks, prompt and retrieval versioning, cost controls, security review, audit logs, monitoring, support diagnostics, fallback paths, and release procedures. For workflows where AI takes actions through APIs or internal tools, use enterprise AI agent governance controls before expanding beyond a supervised pilot.
Hardening is where many GenAI timelines expand. A demo can look impressive with one user and a curated document set. Production requires permission-aware retrieval, stale-data handling, error recovery, PII controls, rate limits, model fallback, traceability, red-team or misuse-case review, and operational ownership. For serious RAG, copilot, and model-integration work, NextPage treats this as part of LLM development, not an optional cleanup step.
| Hardening Area | What To Verify | Why It Affects Timeline |
|---|---|---|
| Evaluation | Known questions, expected answers, refusal cases, source quality, regression checks | Teams need evidence that answer quality holds after changes |
| Security | Access control, secrets, PII handling, retention, audit logging, vendor review | Security sign-off can block launch if left late |
| Integrations | API errors, retries, permissions, sandbox and production credentials, support logs | Real systems fail in ways prototypes hide |
| Operations | Monitoring, cost alerts, owner escalation, incident handling, model-change process | Unowned AI systems decay quickly after launch |
Phase 5: Launch, Monitoring, And Scale
Launch should begin with a controlled rollout, not a broad announcement. Start with trained users, defined workflows, feedback channels, and a dashboard that tracks usage, quality, cost, time saved, escalation rate, and business outcomes. The first weeks after launch often teach more than the prototype because real users expose ambiguous queries, missing content, and edge cases.
Scaling comes after the system proves value and stability. That may mean adding more data sources, connecting another department, expanding language support, creating admin controls, adding new agents, or converting a one-off solution into a reusable platform. Each expansion should go back through a lighter version of discovery, prototype, MVP, and hardening.
Budget and timeline planning should also revisit operating cost. NextPage's generative AI development cost guide explains why architecture, context size, model choice, evaluation, compliance, and integrations shape both the build and the monthly run cost.
Budget And Timeline Planning
The fastest useful timeline is usually the one that protects the first workflow from uncontrolled scope. Before approving a build, separate must-have launch controls from later expansion ideas. A discovery sprint can estimate the cost of data cleanup, retrieval, integrations, evaluation, human review, monitoring, and support ownership before the team commits to a broad roadmap.
For buyers comparing delivery partners, review both the proposed architecture and examples of shipped product work. NextPage's software and AI portfolio shows how we structure production systems around usable workflows, operational controls, and maintainable releases instead of one-off demos.
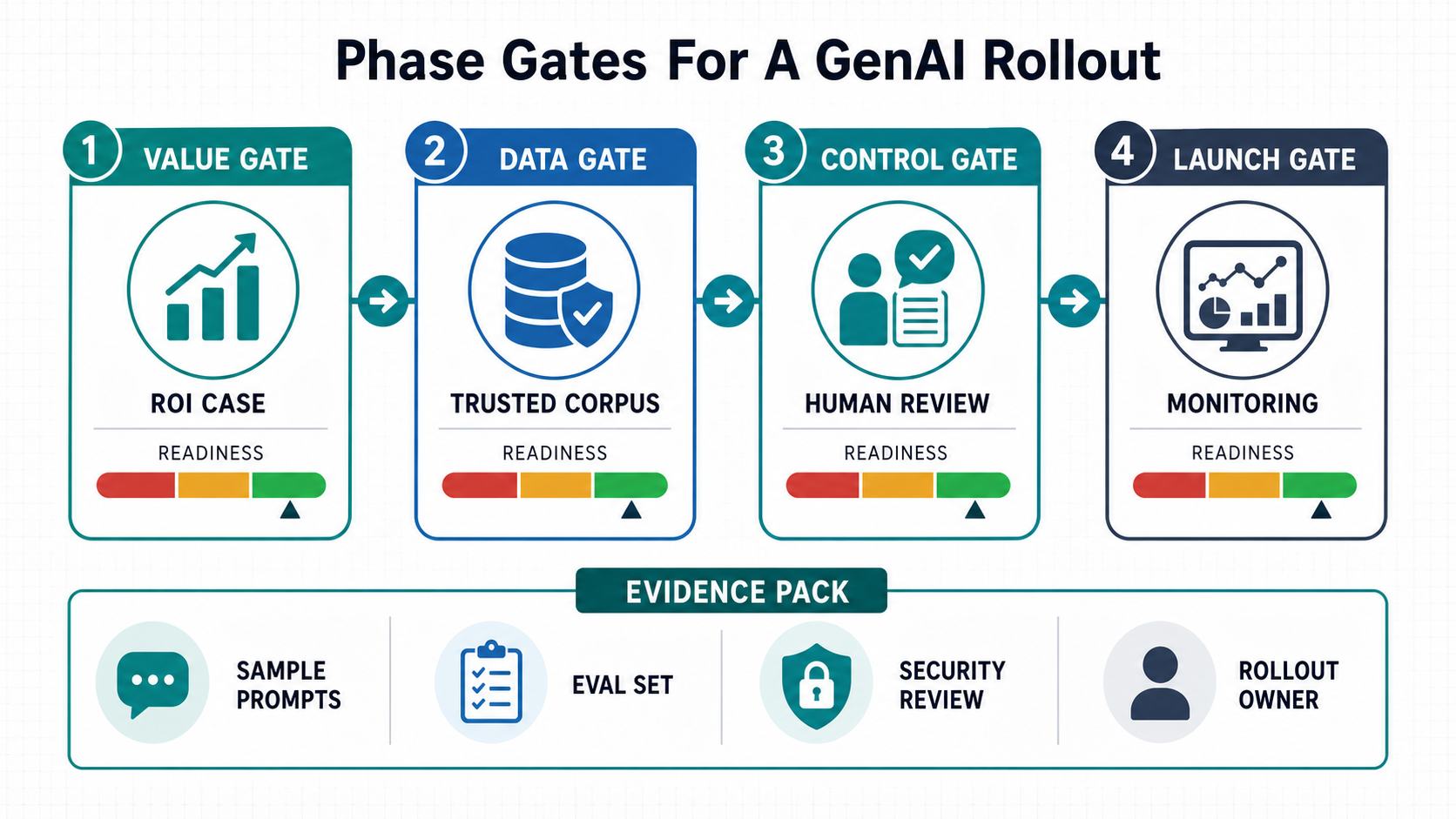
Readiness Gates That Keep The Timeline Honest
Every phase needs a gate. Without gates, the timeline becomes a wish list and the team carries unresolved risks into production. A simple gate model asks whether business value, data readiness, integration access, governance, evaluation evidence, and operating ownership are strong enough to continue.
Use the AI Agent Readiness Assessment before agentic workflows because tool access, human review, and governance controls become more important when AI can take actions. For lower-risk assistants, the same logic still applies: do not expand until reviewers trust output quality, monitoring can detect regressions, and the support owner knows what to do when the system fails.
Common Timeline Blockers
The most common GenAI blockers are not model limitations. They are operational gaps that the project finally makes visible.
- Unclear workflow ownership: nobody can decide what the AI should and should not do.
- Messy or inaccessible data: documents are duplicated, stale, permissionless, or trapped in systems without reliable APIs.
- No evaluation set: reviewers disagree on what counts as a good answer, making launch quality subjective.
- Late security review: privacy, retention, access control, or vendor questions arrive after the MVP is already built.
- Integration surprises: CRM, ERP, ticketing, data warehouse, or document systems behave differently in production than in a demo.
- Over-broad scope: the team tries to serve several departments before one workflow proves value.
- No post-launch owner: nobody owns prompt updates, retrieval freshness, cost monitoring, or failure triage.
A strong timeline makes these risks explicit early. If a blocker appears, the right move is usually to narrow the first release rather than force the original date.
How NextPage Helps Plan GenAI Delivery
NextPage helps teams turn GenAI ideas into buildable delivery plans. We define the first workflow, audit data readiness, choose the simplest architecture that can meet the quality bar, design evaluation and human-review controls, and plan the MVP around measurable business value.
Our AI development services cover practical enterprise automation, model integration, RAG systems, AI agents, dashboards, and production software delivery. If you are preparing a GenAI MVP or production rollout, bring the target workflow, sample data, current systems, security constraints, and desired outcome. We will help you decide what can ship quickly, what needs hardening, and what should wait until the foundation is ready. If the first automation sprint is still unclear, use the Workflow Automation Opportunity Finder to rank repeatable workflows before turning one into a GenAI pilot.