
Quick Answer: Should You Hire An AI Prompt Engineer?
Hire an AI prompt engineer when the core problem is instruction design, response quality, prompt versioning, evaluation examples, and workflow handoff for an LLM product that already has the right data and engineering foundation. Do not hire a prompt engineer as a shortcut for missing product engineering, weak retrieval, poor integrations, unclear permissions, or absent monitoring. In 2026, prompt work is one layer of a production AI system that also needs backend engineering, RAG design, evals, security, observability, and product judgment.
The right hire depends on what is failing. If a support assistant gives vague answers, you may need prompt and evaluation work. If it cannot answer from private knowledge, you likely need retrieval architecture. If it must update CRM fields, trigger tools, or respect user permissions, you need an LLM product engineer. If AI is becoming a roadmap stream across multiple workflows, a managed AI product pod or dedicated team is usually safer than a single specialist.
NextPage starts with the business workflow, not the job title. A prompt specialist can improve a narrow AI surface, but teams building copilots, RAG apps, AI agents, or support automation often need LLM development and delivery ownership across prompts, retrieval, APIs, evaluation, release controls, and rollout.

What AI Prompt Engineers Actually Do Now
The early version of prompt engineering was often treated like clever wording. That is not enough for production products. A useful AI prompt engineer now defines task instructions, examples, refusal boundaries, structured outputs, prompt variables, test cases, human review rules, and model-change checks. They work with product, engineering, data, domain experts, and QA to make model behavior more consistent and measurable.
Modern prompt work usually includes task framing, prompt versioning, evaluation examples, failure analysis, and guardrail definition. The best specialists can explain when the problem is wording, missing context, poor retrieval, the wrong model, a broken tool call, or an ambiguous workflow. That diagnostic judgment matters more than a library of generic prompt templates.
Current OpenAI platform guidance reinforces this shift: prompts can be tested with evals, connected to tools, constrained with structured outputs, and improved through measurable iteration. A buyer should therefore screen for prompt engineering as product-quality work, not as a private collection of magic phrases.
Prompt Engineer Vs LLM Engineer Vs RAG/Evals Engineer
The most expensive hiring mistake is using one title for three different jobs. A prompt engineer improves instructions and behavior. An LLM engineer builds the system around the model. A RAG/evals engineer makes private knowledge, retrieval quality, test sets, and hallucination controls measurable. An AI product pod connects all of that to user journeys, business rules, QA, DevOps, and release constraints.
| Role | Best fit | What to screen for | Risk if misused |
|---|---|---|---|
| Prompt specialist | Existing LLM workflow needs clearer outputs, reusable prompts, examples, and eval cases | Instruction design, writing clarity, model behavior debugging, domain translation | They cannot fix weak data, missing APIs, or poor architecture alone |
| LLM product engineer | You need AI features inside a web, mobile, SaaS, or internal product | Backend/API work, tool calling, structured outputs, error handling, product UX, logging | A demo ships while reliability, permissions, and operations lag behind |
| RAG/evals engineer | Answers must come from private knowledge, policies, documents, tickets, or internal systems | Chunking, embeddings, retrieval tests, eval datasets, citations, hallucination checks | Teams keep changing prompts when retrieval quality is the real problem |
| AI product pod | AI is a roadmap stream with UX, backend, data, QA, DevOps, and domain workflows | Delivery ownership, product discovery, architecture, release process, QA, cost control | A single hire becomes a bottleneck across too many disciplines |
If your roadmap includes multiple AI surfaces, a managed team is often more practical than a single senior hire. The Dedicated India Team Cost Calculator can help compare a local direct hire, contractor, and managed India-based AI/product pod before you write the job description.
When A Prompt Engineer Is Enough
A prompt engineer can be enough when the architecture already works and the model mostly has the right context. Good examples include improving a support-answer prompt, standardizing sales-call summaries, making an internal assistant follow a stricter tone, creating prompt templates for a content workflow, building test cases for a classification task, or refining agent instructions after the engineering foundation is stable.
In those cases, define a bounded outcome: reduce unsupported answers on a 100-question test set, improve JSON validity, cut review edits by 30 percent, increase correct escalation decisions, or create reusable prompt templates for five workflows. Avoid hiring against vague promises such as "make our AI better." That makes the candidate responsible for product, data, and engineering decisions they may not control.
A strong prompt specialist should also tell you when the issue is not prompt-related. If they never ask about source data, retrieval quality, user permissions, evals, latency, model cost, or product workflow, they may be optimizing text while the system problem remains unsolved.
When You Need An LLM Engineer Instead
You need an LLM engineer when the product must do more than generate a clean answer. This includes connecting to user data, retrieving private knowledge, calling business tools, returning structured outputs, handling errors, managing latency, logging interactions, tracking cost, enforcing permissions, or integrating with a web or mobile app.
For example, a customer-support assistant may need retrieval from help content, customer-plan checks, CRM context, escalation logic, and audit logs. A procurement copilot may need document search, supplier records, approval workflows, and role-based access. A sales assistant may need CRM updates, lead scoring, and human review. Those are software-product problems with LLM behavior inside them.
If that is your scope, look for candidates who can design and ship production paths, not just prompts. NextPage's generative AI development work combines prompt and retrieval design with application engineering, evals, workflow automation, and rollout support.
AI Hiring Scorecard For LLM Product Teams
Use a scorecard before opening a role. It helps separate a narrow prompt-quality problem from a broader delivery problem and keeps hiring conversations focused on evidence instead of title inflation.
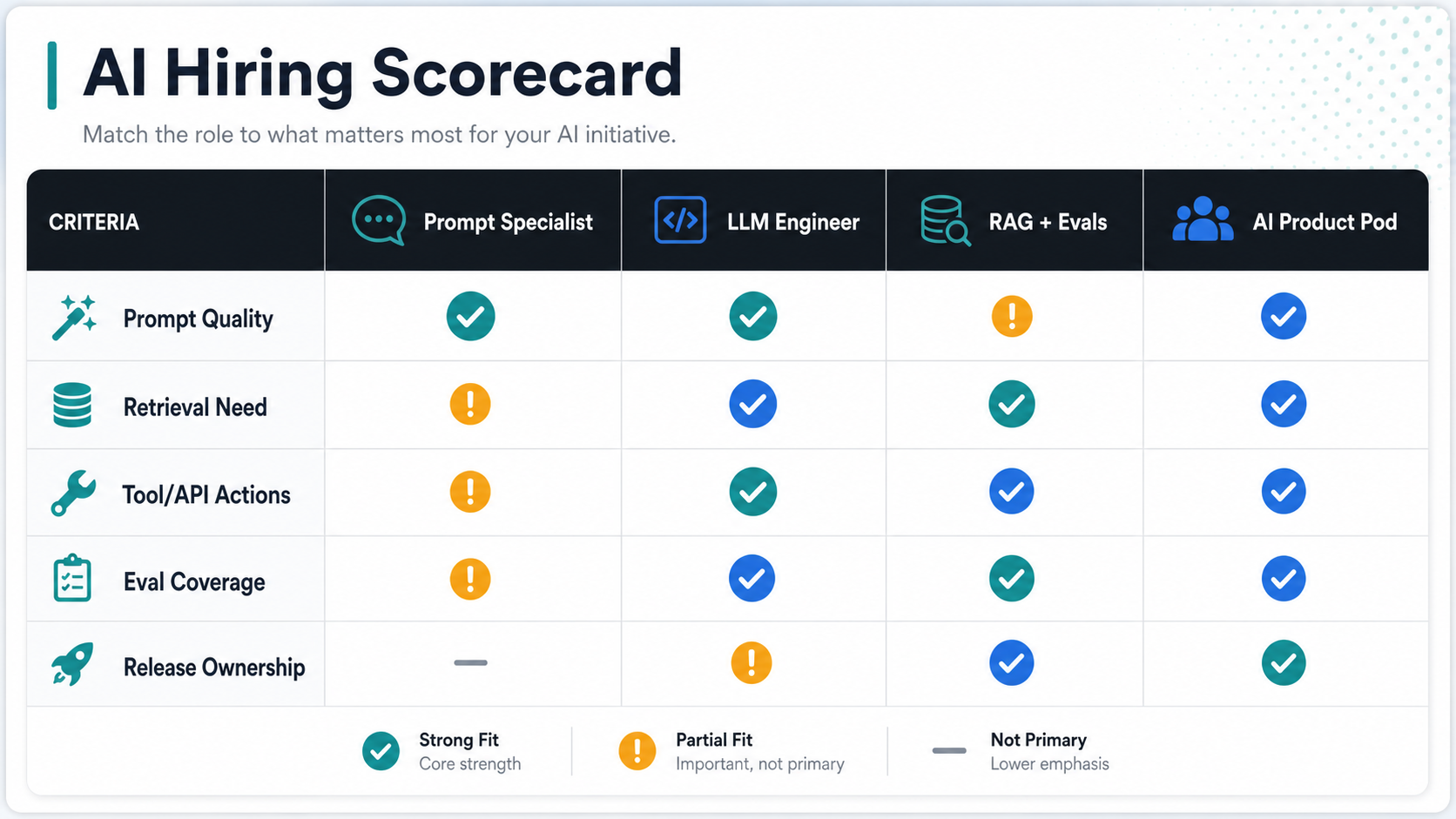
| Your situation | Best first hire or model | Why |
|---|---|---|
| You have a working AI workflow, but outputs are inconsistent | Prompt specialist plus QA/eval support | The system exists; the main work is behavior definition and measurable improvement |
| You need a chatbot, copilot, or assistant inside an app | LLM product engineer | The work includes UX, APIs, data flow, model calls, logging, and errors |
| Answers must be grounded in documents or private knowledge | RAG/evals engineer | Retrieval quality, test sets, citations, and hallucination controls drive success |
| You need AI features across several product areas | Managed AI product pod or dedicated team | One person cannot own product, backend, prompts, QA, DevOps, and analytics at once |
| You are unsure whether the use case is worth building | Short discovery sprint or readiness assessment | It validates data, ROI, risk, and scope before a long hiring cycle |
If the goal is operational savings, validate the business case before hiring. The AI Automation ROI Calculator can estimate whether a repeated workflow has enough volume and value to justify a specialist or team.
Skills To Screen For
Prompt-engineer screening should start with writing and reasoning, but it should not stop there. A strong candidate can explain model behavior, write constraints, design tests, and collaborate with engineers who turn prompts into product behavior.
- Instruction design: Can they turn a vague request into explicit goals, context, constraints, examples, output format, and failure handling?
- Evaluation thinking: Can they define a test set, expected behavior, pass/fail criteria, edge cases, and regression checks?
- RAG awareness: Do they know when retrieval, chunking, metadata, or source cleanup is the blocker?
- Structured outputs and tool use: Can they work with schemas, function calls, validation, retries, and API handoffs?
- Security and privacy: Do they understand prompt injection, data exposure, logging risks, and human review boundaries?
- Product judgment: Can they connect model behavior to user trust, workflow outcomes, cost, and escalation?
For knowledge-heavy products, experience with retrieval and evals matters more than polished prompt examples. NextPage's enterprise RAG implementation work treats retrieval, source governance, permissioning, evaluation, and monitoring as core product requirements.
Interview Tests That Reveal Real Capability
A useful interview test should resemble the work. Give the candidate a short product scenario, flawed model outputs, a few source documents, and business constraints. Ask them to improve the instruction set, define test cases, identify missing context, and explain what engineering changes they would request.
Good panel prompts include: turn this support workflow into system instructions and refusal rules; classify which failures are prompt problems versus retrieval or product-scope problems; design a small eval set; explain how model upgrades would be regression-tested; and identify where human review, logging, or escalation is required.
Avoid trivia questions about prompt acronyms or generic model knowledge. The signal is how the candidate reasons about ambiguous business rules, incomplete context, unsafe actions, inconsistent source material, and measurable release criteria. For chatbot-specific work, compare the candidate's answer with the operating controls used in production AI chatbot development: knowledge retrieval, integrations, handoff, analytics, and continuous improvement.
Red Flags When Hiring Prompt Engineers
Be careful when a candidate presents prompt engineering as a standalone cure for every AI issue. Strong candidates are usually comfortable saying, "This is not a prompt problem." Red flags include:
- They only show before-and-after screenshots, not test sets or measurable acceptance criteria.
- They cannot explain how they would catch regressions after a model or prompt change.
- They ignore retrieval quality, source data, permissions, and workflow design.
- They promise hallucination elimination without scope limits, grounding, evals, and human review.
- They cannot work with engineers on APIs, structured output, logging, or tool use.
- They focus on viral prompting tricks rather than durable product behavior.
For vendor selection, compare the candidate or agency against the same practical criteria you would use for an AI delivery partner. The NextPage guide on how to choose an AI development company covers portfolio review, architecture depth, risk controls, costs, and post-launch support signals.
Freelancer, Direct Hire, Or Dedicated AI Team?
Use a freelancer when the scope is narrow, the system already exists, and the work can be judged by a clear eval set. Use a direct hire when AI is core to the product roadmap and the person will own long-term context inside the business. Use a dedicated AI team when you need product, backend, prompt, retrieval, QA, and DevOps capacity without waiting months to recruit every role.
Many teams start with a scoped sprint. The sprint can audit the workflow, create a small eval set, improve the prompt or retrieval path, and recommend whether to hire a specialist or build a product pod. This reduces the risk of hiring the wrong title before the work is understood.
If you are comparing offshore, dedicated-team, and project-based models, NextPage's guide to software development outsourcing to India explains how cost, control, communication, and delivery ownership change across models.
A Practical First 30 Days After Hiring
The first month should produce clarity, not just more prompts. Ask the hire or team to map current AI surfaces, identify repeated failures, create a baseline test set, document prompt versions, classify risks, and define the first measurable improvement target.
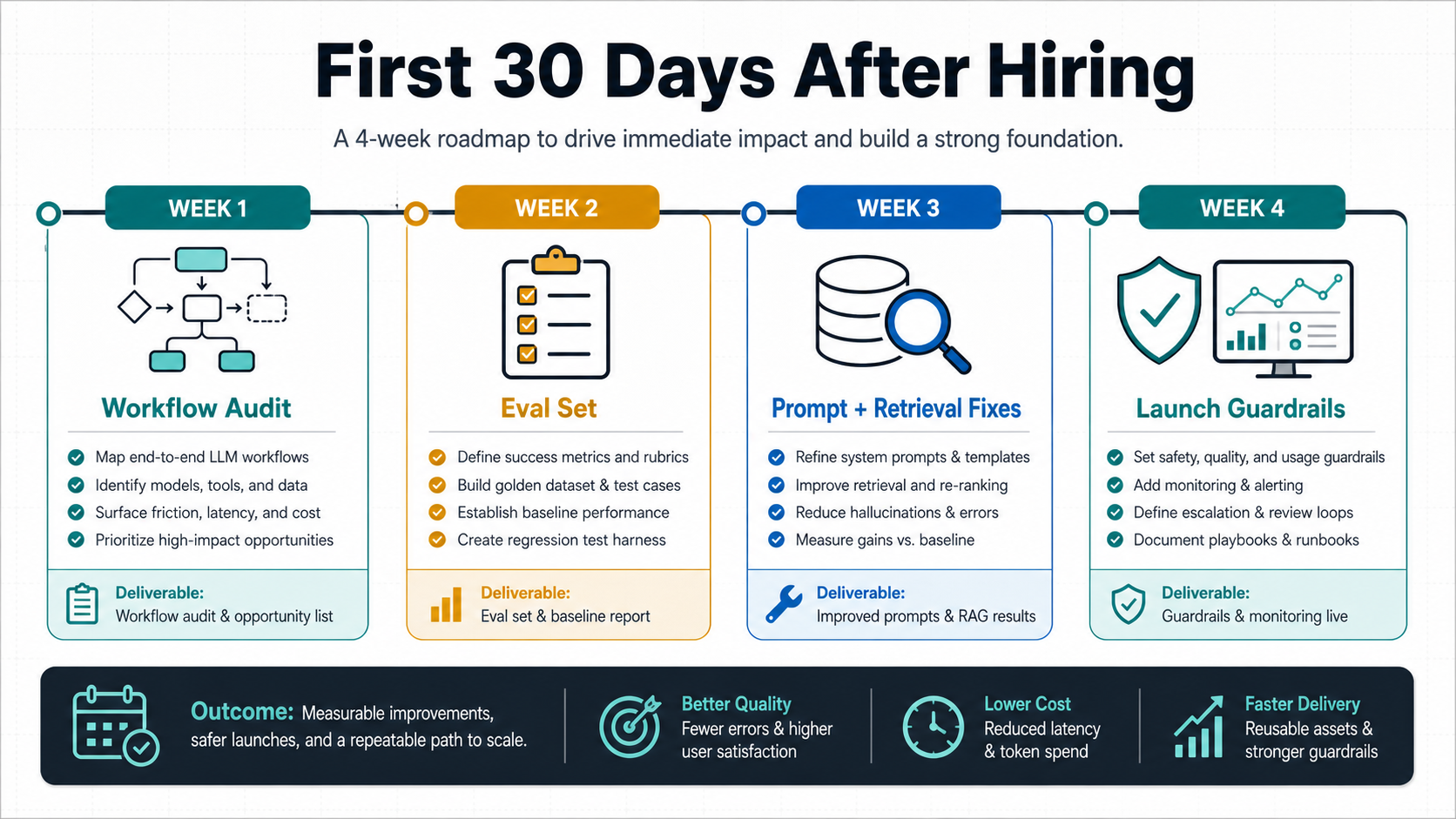
| Week | Focus | Output |
|---|---|---|
| 1 | Workflow and failure audit | Use-case map, source inventory, risk list, sample failures |
| 2 | Eval and acceptance criteria | Test set, pass/fail rubric, escalation rules, baseline score |
| 3 | Prompt, retrieval, and system improvements | Versioned prompt changes, retrieval requests, structured-output fixes |
| 4 | Release and monitoring plan | Regression check, review workflow, launch notes, next backlog |
If the first 30 days reveal deeper product or engineering work, treat that as useful signal. It is better to discover that the product needs a retrieval layer, data cleanup, API integration, or observability early than to keep polishing prompts around a weak system.
When NextPage Can Help
NextPage helps teams decide what AI capability to hire, build, or outsource before they lock into the wrong role. We can review the use case, map the workflow, assess data readiness, design the first eval set, and recommend whether a prompt specialist, LLM engineer, RAG implementation, or managed AI pod is the right next step.
If you need delivery capacity, our AI development services and dedicated-team model can combine product engineering, LLM integration, retrieval, prompt design, QA, and rollout support. That is usually the safer path when the goal is not only better prompts, but a reliable AI feature users can trust.