
Quick Answer: NLP Implementation Roadmap
An NLP implementation roadmap takes a language-processing idea from business use case to production workflow. The practical sequence is: choose one high-value text task, audit the source data and permissions, choose the right NLP or LLM pattern, build a narrow proof of concept, design human review, integrate with business systems, monitor quality in production, and improve the workflow from real feedback.
The mistake is treating NLP as a model-selection exercise. A useful roadmap starts with the decision the software must support: routing tickets, extracting fields from documents, classifying complaints, summarizing calls, finding policy answers, detecting sentiment, or triggering a workflow from unstructured text. Model choice matters, but workflow clarity, data quality, evaluation design, integration access, human review, and operating ownership decide whether the project reaches production.
For a broader template, compare this NLP-specific plan with NextPage's AI implementation roadmap. The NLP version puts extra weight on messy text, language coverage, privacy, retrieval quality, hallucination controls, label drift, and reviewer feedback loops. Teams that need delivery help can pair the roadmap with NextPage natural language processing development services.
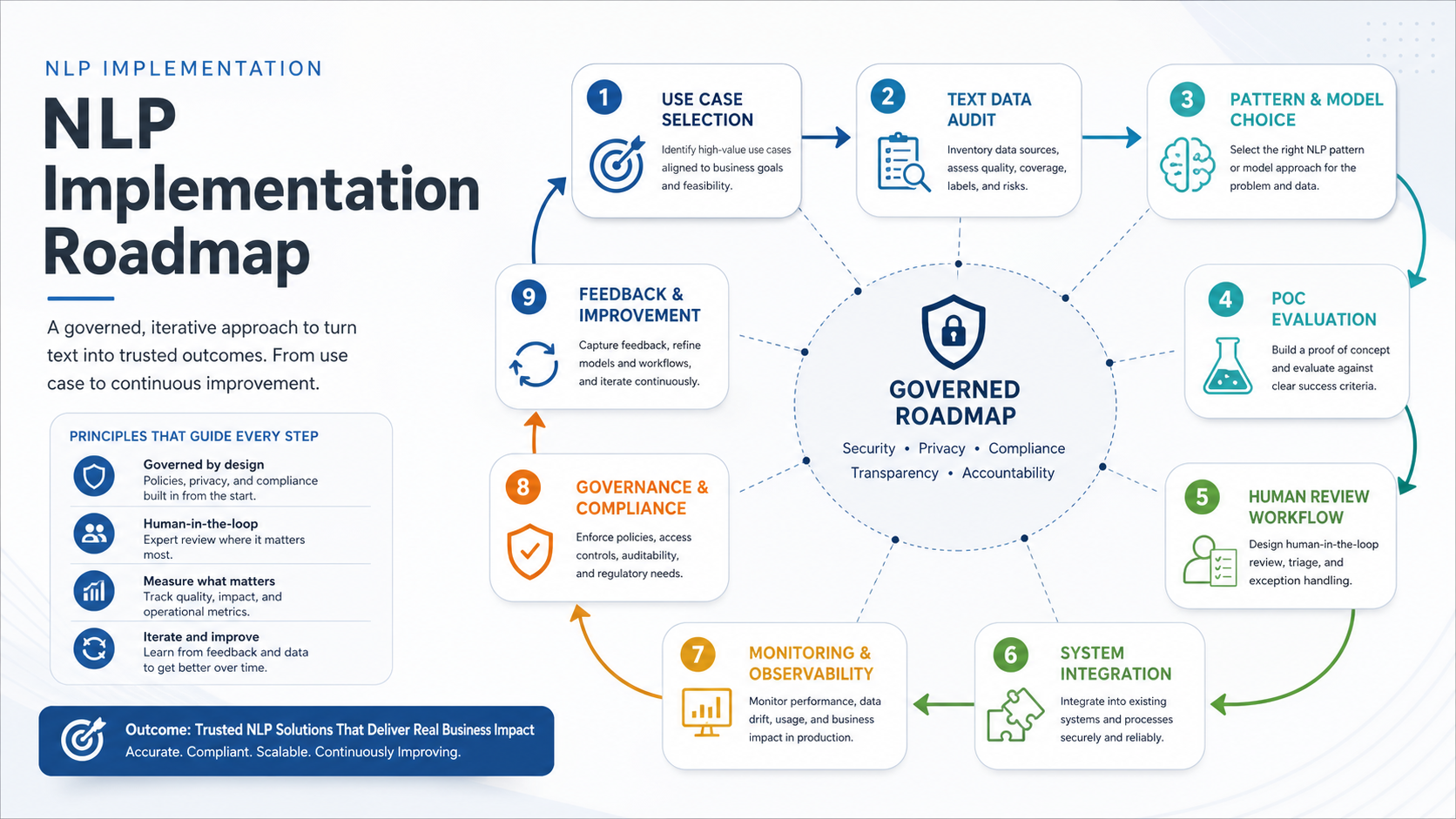
The NLP Implementation Roadmap
A reliable NLP roadmap should move through clear gates instead of jumping from demo to rollout. Each gate proves a different risk: whether the use case is worth solving, whether the text is usable, whether an NLP or LLM approach improves the current process, whether the workflow can be integrated safely, and whether production monitoring can catch quality drift.
| Phase | Main Question | Output |
|---|---|---|
| Discovery | Which language workflow has measurable value? | Use-case brief, owner, baseline, success metric |
| Data audit | Is the text usable, permitted, and representative? | Data inventory, sample set, labels, privacy constraints |
| Pattern selection | Should the workflow use rules, ML, RAG, extraction, summarization, or an agentic workflow? | Architecture decision and evaluation plan |
| PoC | Can the approach beat the current process on real examples? | Prototype, evaluation report, risk notes |
| Workflow design | How will users review, approve, and act? | Human-in-the-loop flow, exception policy, UI requirements |
| Production | Can the system run, monitor, and improve safely? | Integrated service, observability, rollback, improvement loop |
Use the roadmap to avoid unfocused pilots. A sentiment model, document extractor, chatbot, semantic search tool, or ticket classifier can all be valid, but each needs a different data plan, evaluation set, user interface, and operating model. The narrow AI for business guide is useful when teams need to decide which language task is buildable first.
Choose The NLP Use Case And Decision Owner
Start by naming the workflow, not the technology. Good NLP use cases have repeated text inputs, a known business decision, a clear owner, and a measurable improvement target. Examples include classifying support tickets, extracting invoice fields, summarizing sales calls, tagging compliance documents, routing inbound leads, detecting escalation risk, or answering policy questions from a controlled knowledge base.
For each candidate, document the current process: who reads the text, what they decide, which system they update, how long it takes, what mistakes cost, and what evidence a reviewer needs. This exposes whether the project is closer to a classifier, extraction pipeline, retrieval-augmented assistant, summarizer, semantic search tool, or rules-plus-model hybrid.
- Owner: the team accountable for the workflow result, such as support, operations, legal, sales, finance, or HR.
- Text source: tickets, emails, chat logs, documents, call transcripts, product reviews, contracts, or knowledge articles.
- Decision: classify, extract, summarize, recommend, route, escalate, search, answer, or trigger a follow-up.
- Metric: review time, resolution time, extraction accuracy, false escalation rate, missed SLA, rework, or hours saved.
- Control: when the system can act automatically and when a human must approve.
If the workflow is operational and repeated, estimate its value with the AI Automation ROI Calculator. Use conservative assumptions: current review volume, manual minutes per item, reviewer hourly cost, expected automation percentage, and exception rate.
Audit Text Data, Labels, Privacy, And Access
NLP projects fail early when teams discover that the useful text is scattered, sensitive, duplicated, inconsistently formatted, stale, or unlabeled. Before promising a model, build a text data inventory. List every source system, document type, language, format, owner, retention rule, consent boundary, access method, refresh cadence, and quality issue.
For classification and extraction, sample examples from both normal and edge cases. For summarization or RAG, inspect whether the source content is current, authoritative, chunkable, and properly permissioned. For customer or employee text, map privacy and compliance obligations before any prompt, embedding, training, or review workflow is designed. NextPage's enterprise AI readiness checklist covers the broader governance questions that sit around the data audit.
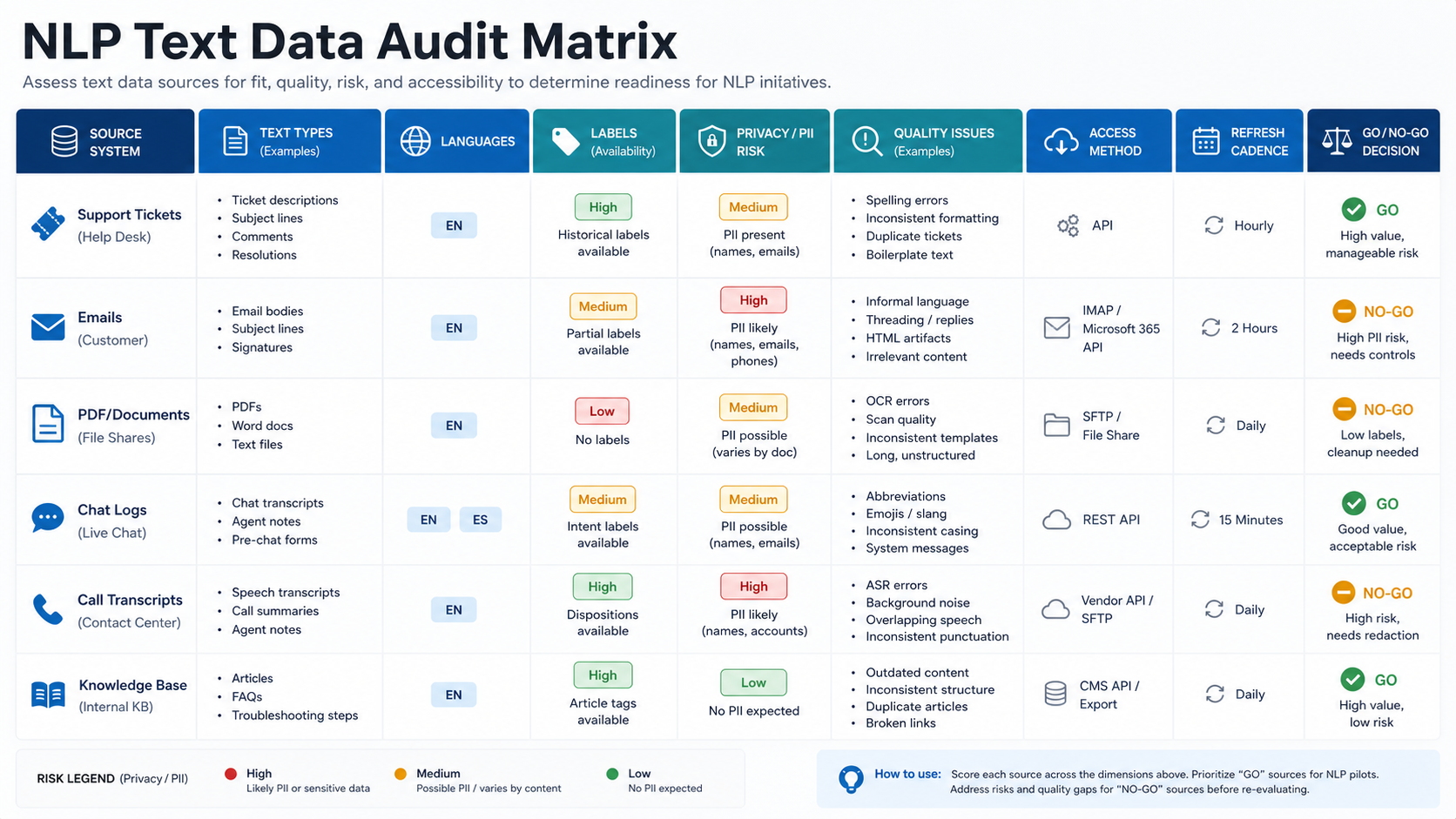
| Audit Area | What To Check | Why It Matters |
|---|---|---|
| Coverage | Volume, languages, channels, historical range, edge cases | Prevents a PoC that works only on clean examples |
| Labels | Existing categories, reviewer agreement, field definitions | Controls training and evaluation quality |
| Permissions | PII, contracts, retention, consent, customer data boundaries | Protects production use and vendor choices |
| Format | PDFs, scans, emails, HTML, transcripts, OCR quality | Shapes preprocessing and extraction effort |
| Access | APIs, exports, rate limits, ownership, refresh cadence | Determines whether production integration is realistic |
Choose The Right NLP Pattern
Do not force every language workflow into a chatbot. Many production NLP wins come from smaller patterns: a classifier, extraction service, semantic search index, summarizer, routing assistant, validation rule, or human-reviewed workflow. The right pattern depends on the business decision, text structure, risk, latency, integration needs, and how much evidence users need before acting.
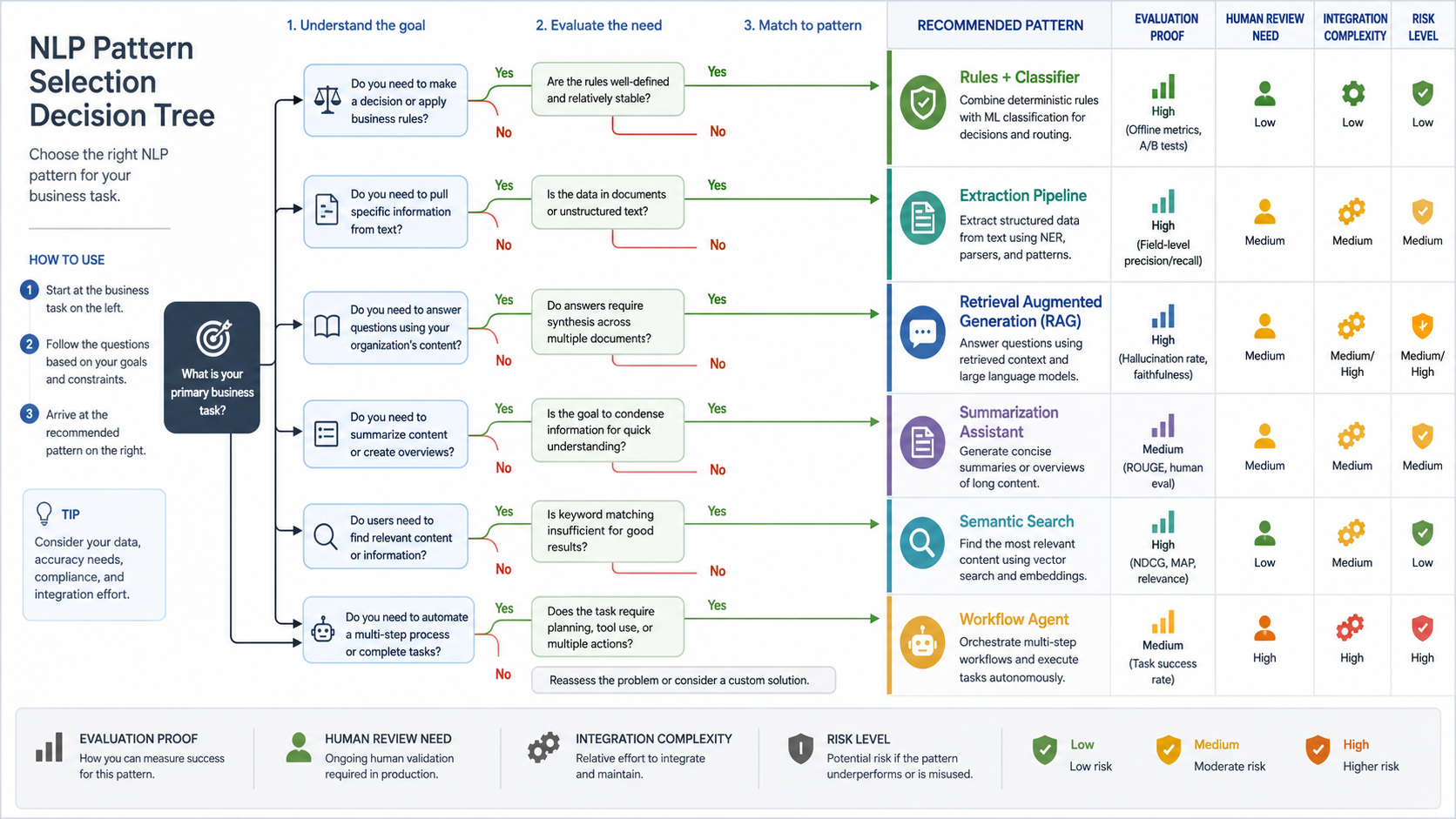
| Workflow Need | Likely Pattern | Proof Needed |
|---|---|---|
| Route repeated tickets or leads | Rules plus classifier | Precision, recall, escalation rate, reviewer acceptance |
| Read structured fields from documents | OCR plus extraction and validation | Field-level accuracy, missing-field handling, audit trail |
| Answer from approved knowledge | RAG assistant | Retrieval quality, source grounding, refusal behavior |
| Condense long text for reviewers | Summarization assistant | Completeness, factuality, time saved, reviewer edits |
| Find related records or policies | Semantic search | Relevant result rate, permission filtering, latency |
| Trigger multi-step actions | Governed workflow agent | Tool permissions, approval steps, rollback, audit logs |
LLM-heavy workflows need extra care around prompts, retrieval, tool permissions, observability, and cost. NextPage's LLM development work covers these production concerns, while enterprise chatbot integration services are relevant when the interface must connect to CRM, ERP, helpdesk, knowledge base, or internal workflow systems.
Build A PoC That Tests Workflow Value
An NLP PoC should not be a polished demo over hand-picked samples. It should test the riskiest assumptions with representative inputs and a clear baseline. For a classifier, compare output against human-labeled examples. For extraction, measure field-level precision, recall, and reviewer correction effort. For summarization, test whether users can make the downstream decision faster without losing important detail. For RAG, check answer grounding, refusal behavior, retrieval quality, and source traceability.
Keep the PoC narrow enough to finish, but realistic enough to reveal production constraints. Include messy text, short text, long text, ambiguous cases, repeated templates, missing fields, out-of-scope requests, sensitive snippets, and examples from each major language or channel. A controlled PoC can still be valuable if it tells the team whether to build, pause, change scope, or gather better data.
When selecting an implementation partner, ask for the PoC plan and the production path in the same conversation. The machine learning consulting company checklist is useful for testing whether a vendor is honest about baselines, data readiness, MLOps, costs, and risk.
Design The Production NLP Workflow
Production NLP is a workflow, not only an endpoint. Text arrives from one or more systems, gets cleaned or chunked, passes through a model, rules layer, or LLM call, receives confidence scoring or validation, lands in a user interface or API response, and triggers an action only when the control policy allows it. Human review should be designed before launch, not added after errors appear.
For high-impact decisions, start in assistive mode. The system can draft classifications, summaries, extracted fields, or recommended actions while a reviewer approves or edits the output. For low-risk, high-volume work, the roadmap can move toward bounded automation once confidence, monitoring, and rollback are proven. This is why many NLP programs become AI workflow automation projects: they connect intake, reasoning, review, action, and monitoring.
- Input controls: validate source, language, file type, document age, and permission.
- Output controls: show confidence, source snippets, extracted fields, uncertainty, and missing information.
- Human review: route low-confidence or high-risk cases to the right owner with editable outputs.
- Action policy: define which outputs can update systems, create tasks, notify users, or stay advisory.
- Feedback loop: capture edits, rejections, new labels, prompt issues, and edge cases for improvement.
Plan Integration, MLOps, And Monitoring
Integration planning should start before the PoC ends. The roadmap must identify where text enters, where outputs are stored, which APIs are available, how reviewers work today, what audit trail is required, and how the system behaves when data, retrieval, model calls, or downstream systems are unavailable.
Production monitoring should track both technical and workflow signals. Technical signals include latency, error rate, token or inference cost, model version, retrieval failures, extraction validation errors, and drift in input types. Workflow signals include reviewer acceptance rate, edit distance, escalation rate, false positives, false negatives, and time saved. The MLOps implementation checklist is the right companion once the NLP system is headed toward live use.
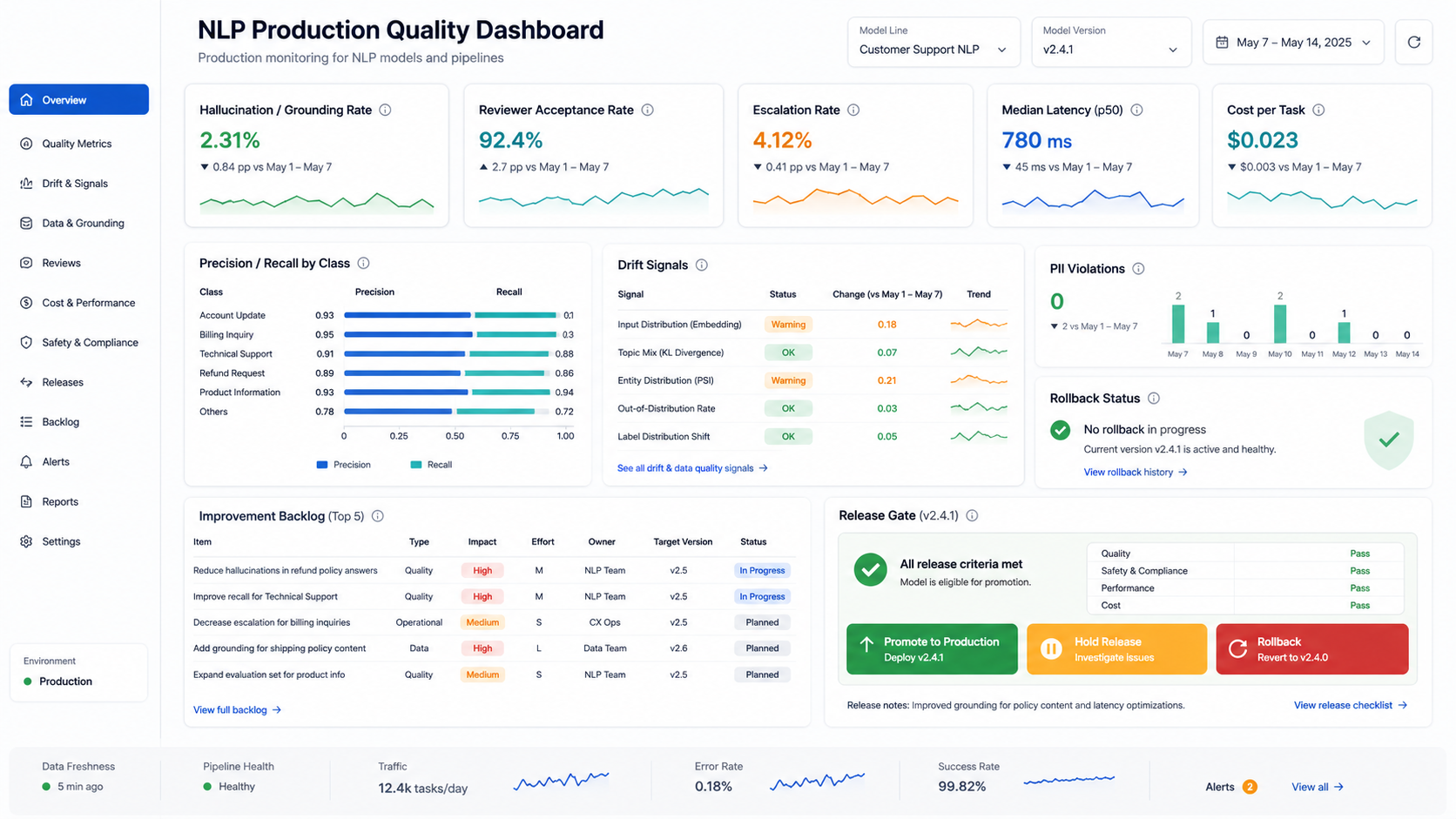
| Production Control | What To Define | Example Evidence |
|---|---|---|
| Evaluation set | Representative examples and edge cases | Gold set, reviewer notes, acceptance thresholds |
| Versioning | Prompt, model, retrieval, preprocessing, and label versions | Release log and rollback path |
| Monitoring | Quality, latency, cost, exceptions, and reviewer behavior | Dashboard and alert rules |
| Security | Data access, PII handling, retention, and audit trails | Access matrix and log samples |
| Improvement | How feedback becomes better prompts, labels, retrieval, or models | Review queue, retraining plan, monthly quality review |
For live language systems, NextPage NLP model monitoring and MLOps services can help teams connect evaluation sets, drift checks, reviewer feedback, dashboards, and release governance.
Security, Privacy, And Governance Controls
NLP systems often process sensitive customer, employee, legal, financial, or health-related text. Treat security and privacy as implementation requirements, not late legal review. The roadmap should define what text can be processed, where it can be stored, which vendors can see it, how long examples are retained, whether outputs are logged, and who can approve automated actions.
- PII handling: classify sensitive fields, redact when possible, and limit prompt or training exposure.
- Permission-aware retrieval: ensure users cannot retrieve documents they are not allowed to view.
- Audit trails: record source, output, reviewer action, model or prompt version, and downstream write-back.
- Vendor and deployment choice: match cloud, private, or hybrid patterns to data sensitivity and compliance needs.
- Abuse and prompt controls: test prompt injection, unsafe tool use, sensitive data leakage, and refusal behavior.
For larger programs, NextPage's AI development services can combine discovery, workflow design, integration engineering, and production hardening so the NLP feature fits the business system instead of living as a disconnected prototype.
Timeline, Roles, And Decision Gates
A realistic NLP timeline depends on data access and integration depth. A focused discovery and data audit can take one to three weeks. A narrow PoC can often run in three to six weeks when source data is accessible and reviewers are available. Production workflow design, integration, monitoring, security review, and rollout can take another six to twelve weeks for a controlled first release. Complex regulated workflows, multilingual coverage, OCR-heavy documents, or multi-system write-backs take longer.
Assign ownership early. Business owners define value and acceptance criteria. Data owners approve access and retention. Subject-matter reviewers label examples and evaluate outputs. Engineers build ingestion, preprocessing, APIs, UI, observability, and deployment. Security and compliance teams review data flows. Product owners decide whether each gate is ready to move forward.
- Gate 1: Use case approved. The workflow has value, owner, baseline, metric, and risk boundary.
- Gate 2: Data usable. The team has representative samples, permissions, labels, and quality notes.
- Gate 3: Pattern selected. The team knows whether to use rules, ML, RAG, extraction, summarization, semantic search, or a governed agent.
- Gate 4: PoC passes. The approach improves the baseline on real examples and exposes known limitations.
- Gate 5: Workflow accepted. Reviewers can understand, correct, approve, and reject outputs.
- Gate 6: Production ready. Integration, monitoring, rollback, security, and support ownership are in place.
Red Flags In An NLP Implementation Plan
Weak NLP plans usually sound model-first. They promise accuracy before data is reviewed, skip human review, ignore edge cases, or treat integration as a final step. A roadmap should surface these risks early because the cost of correcting them increases after users depend on the workflow.
- No named workflow owner: nobody can define what a good output changes in the business process.
- No representative sample set: the PoC uses clean examples while production text is messy, multilingual, scanned, or incomplete.
- No evaluation policy: the team cannot explain precision, recall, acceptance rate, hallucination risk, or reviewer override logic.
- No human-review design: the system can produce output but users cannot inspect evidence, correct mistakes, or send feedback.
- No integration path: the demo does not connect to source systems, permissions, audit trail, or destination workflow.
- No monitoring or rollback: production quality, cost, drift, and version changes cannot be tracked or reversed.
If several red flags appear, run a readiness pass before building. The AI Agent Readiness Assessment is a useful proxy for many NLP workflows because it scores workflow clarity, data readiness, integration access, and human-review controls.
How NextPage Helps
NextPage helps teams turn NLP ideas into controlled software workflows. A practical engagement can start with an NLP feasibility and roadmap workshop: define the use case, audit the text data, map the workflow, choose the right model pattern, estimate ROI, identify integration constraints, and decide what a useful PoC must prove.
From there, the work can move into prototype design, evaluation set creation, LLM or ML pipeline development, reviewer UI, API integration, monitoring, and production rollout. The goal is not just an NLP demo. The goal is a measurable language workflow that your team can trust, improve, and operate.
If your team is planning NLP for support, operations, documents, knowledge search, compliance, or internal automation, start with one repeated text workflow and one decision owner. NextPage can help assess feasibility, design the roadmap, and build the production path with the right controls from the beginning.