
Quick Answer: Which Private GenAI Deployment Option Fits?
Private generative AI deployment is not one architecture. Most teams should start with the least private option that still satisfies data sensitivity, compliance evidence, latency, integration, and operating-control requirements. A SaaS LLM API is often enough for low-risk content tasks. Private endpoints help when network isolation and stronger access controls matter. VPC deployment fits enterprise workloads that need stronger data boundaries, logs, and integration control. Self-hosted open models make sense when model flexibility, data control, or cost at scale is more important than managed convenience. On-prem GenAI is justified only when regulation, sovereignty, disconnected environments, or strict internal policy makes cloud-hosted processing unacceptable.
The right decision starts with workflow risk, not model hype. In 2026, regulated teams should also decide where policy enforcement, model routing, prompt logging, retrieval permissions, and audit evidence will live before picking a model host. NextPage approaches generative AI development as production software: define the workflow, identify sensitive data, map the approval path, choose the deployment boundary, and design monitoring before scaling usage across teams.
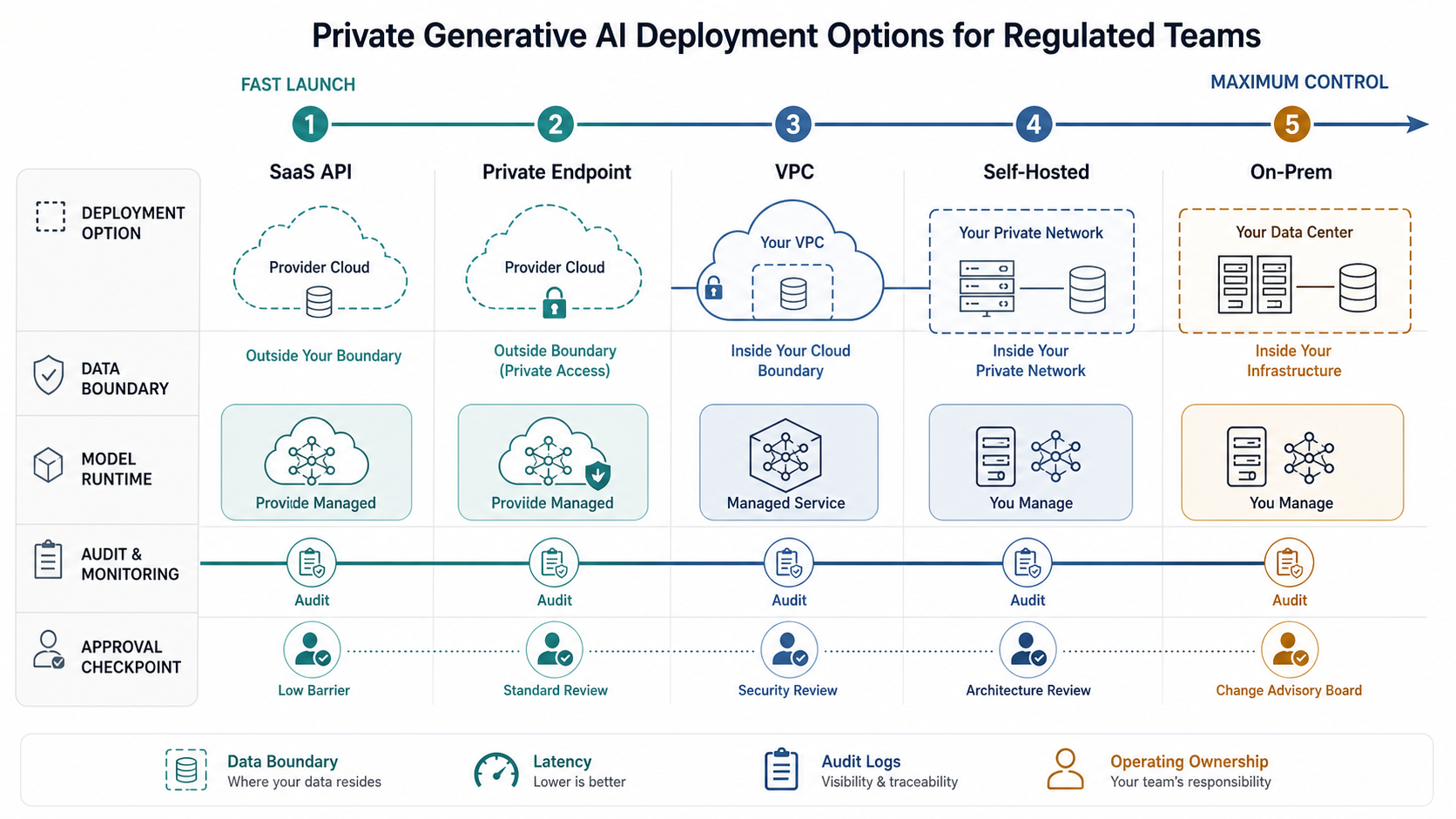
Private Generative AI Deployment Options Compared
Use this table as a first-pass filter before architecture discovery. It does not replace legal, security, or procurement review, but it makes the tradeoffs visible before a team commits to the wrong operating model.
| Option | Best Fit | Main Advantage | Main Tradeoff |
|---|---|---|---|
| SaaS LLM API | Low-risk copilots, drafting, classification, summarization, and prototypes | Fastest launch with managed models and APIs | Less control over vendor boundary, model roadmap, and deep customization |
| Private endpoint | Enterprise cloud users who need network isolation and stronger access controls | Better security posture without operating the full model stack | Still depends on managed provider capabilities and policy terms |
| VPC deployment | Regulated workflows with sensitive data, internal integrations, and audit evidence needs | Stronger data boundary, observability, and enterprise network control | More infrastructure, DevOps, security, and cost governance work |
| BYOC or customer-VPC managed model | Teams that want provider-managed models while keeping runtime, network path, and logs inside an approved cloud boundary | Balances managed model updates with stronger residency, private networking, and audit control | Requires careful review of provider responsibilities, telemetry, support access, and regional availability |
| Self-hosted open model | Teams needing model control, customization, cost control at scale, or strict data handling | High flexibility and ownership over model runtime and data flow | Requires model evaluation, hosting, monitoring, scaling, and security ownership |
| On-prem AI platform | Data-sovereign, air-gapped, defense, government-adjacent, financial, or highly restricted environments | Maximum local control and infrastructure ownership | Highest operational burden, procurement complexity, and upgrade responsibility |
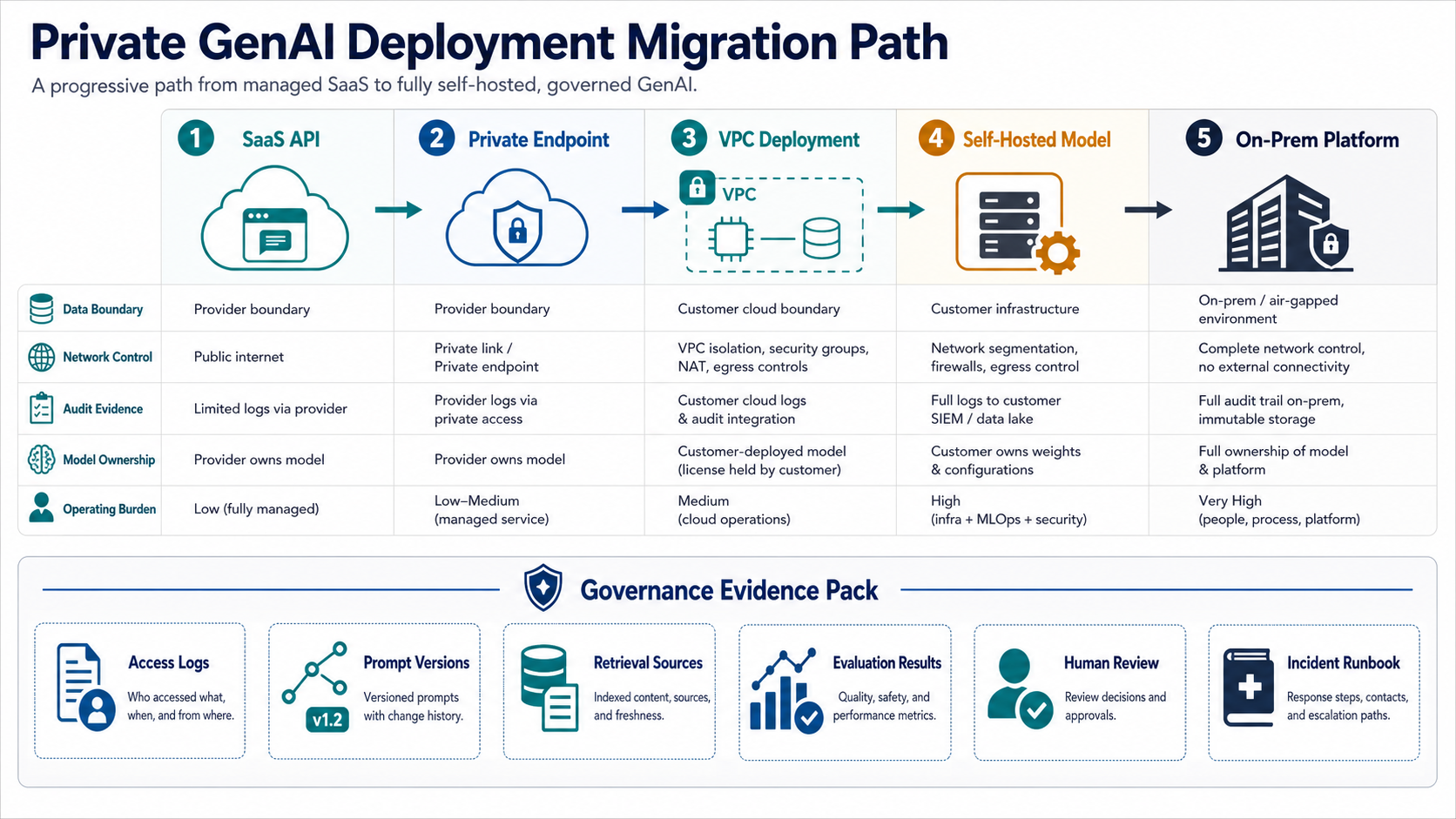
How To Move Between Deployment Patterns Without Rebuilding
Private GenAI architecture should not force a one-way decision. Many teams start with a managed API, add private networking for sensitive workflows, move retrieval and orchestration into a VPC, then self-host only the parts where control, cost, or model behavior justify the extra ownership. The migration plan should separate the app layer, prompt layer, retrieval layer, evaluation set, logging model, and access policy so each can move without rewriting the entire product.
For workflows that will automate operational handoffs, map the decision journey before moving infrastructure. The AI workflow automation guide is useful here because it frames GenAI as intake, retrieval, decision, action, review, and monitoring rather than a standalone model call.
Model Gateway And Evidence Layer Regulated Teams Need In 2026
Private GenAI is now less about a single hosting label and more about the control plane around every model call. A regulated team may use SaaS APIs for low-risk workflows, a customer-VPC model for sensitive workloads, and a self-hosted model for high-volume or sovereignty-bound cases. Without a shared gateway, policy layer, and evidence model, those choices become fragmented exceptions instead of a governed architecture.
The gateway does not have to be a heavyweight platform on day one. It can start as an application service that centralizes provider routing, approved model lists, tenant or workflow policy, prompt and retrieval logging, redaction, cost thresholds, fallback rules, and human-review triggers. For agentic or tool-using workflows, pair that layer with an AI agent identity governance checklist so every non-human actor has named ownership, scoped permissions, audit trails, and revocation paths.
| Control Layer | What It Proves | Why It Matters |
|---|---|---|
| Model gateway | Which provider, model, version, region, and route handled each workflow | Prevents unmanaged model sprawl and gives platform teams a single enforcement point |
| Retrieval policy | Which sources, permissions, and filters shaped the prompt context | Reduces data leakage and makes answers easier to audit |
| Evaluation record | Which test set, red-team checks, and acceptance thresholds approved the release | Turns launch readiness into evidence instead of opinion |
| Human review path | Which outputs require approval before customer, financial, medical, legal, or operational impact | Keeps high-risk decisions accountable even when the infrastructure is private |
| Incident controls | How teams pause a workflow, revoke access, roll back a model route, and preserve logs | Makes private GenAI operable under security or compliance pressure |
When A SaaS LLM API Is Enough
A SaaS LLM API is often the right first option when the workflow does not send highly sensitive data, the team needs speed, and managed reliability matters more than infrastructure control. Typical candidates include internal drafting assistants, marketing variants, support-response suggestions with redaction, taxonomy tagging, document summarization on sanitized inputs, and early experiments.
The mistake is treating SaaS as a shortcut around governance. Even for lower-risk workflows, teams need input filtering, output review, usage logs, prompt versioning, cost controls, and clear data-handling rules. If sensitive data cannot be removed from prompts or retrieval context, move to a stronger deployment pattern before expanding usage.
When To Use Private Endpoints
Private endpoints are useful when a team wants managed model access but does not want traffic flowing over the public internet. They can strengthen network posture, simplify enterprise access policies, and reduce friction with security teams during early production rollout. They are often the first serious control upgrade for teams that need stronger data boundaries but are not ready to operate model infrastructure.
This option works well for organizations already standardized on a cloud provider and identity stack. It is not the same as full data sovereignty or full runtime ownership. Buyers should still review provider data-retention terms, logging behavior, regional availability, incident response, model-change policies, and export controls before assuming the deployment is private enough.
When VPC Deployment Makes Sense
VPC deployment is the practical middle path for many regulated teams. The application, retrieval layer, vector database, orchestration code, access controls, and monitoring can sit inside the organization's cloud boundary while the team uses managed AI infrastructure where appropriate. This gives security and platform teams more control over identity, networking, logs, secrets, data stores, and integration points.
Before choosing VPC deployment, run a cloud migration assessment style review for the AI workload: which data sources are involved, which systems call the AI service, what latency is acceptable, which logs need retention, how secrets are managed, and who owns cost anomalies. VPC deployment is not only an AI choice; it is an infrastructure and operations commitment.
When To Self-Host Open Models
Self-hosted open models make sense when the team needs more control over model behavior, fine-tuning, retrieval patterns, deployment region, marginal cost, or data movement. They are also useful when a business wants to evaluate multiple model families without tying the product roadmap to one hosted provider. Before that move, compare the expected usage volume with the AI Automation ROI Calculator so infrastructure ownership is tied to a real operating case instead of a preference for control.
The tradeoff is ownership. Self-hosting adds responsibility for model selection, benchmarking, inference infrastructure, scaling, security patching, observability, prompt and retrieval quality, and regression testing. Practical LLM development should include evaluation harnesses, fallback paths, and human review before exposing a self-hosted model to high-impact workflows.
When On-Prem GenAI Is Justified
On-prem GenAI is justified when business, regulatory, sovereignty, or network constraints make cloud processing unacceptable. This may apply to defense-adjacent environments, government systems, highly restricted financial workflows, certain healthcare workloads, manufacturing plants with limited connectivity, or enterprises with strict internal policy around data leaving controlled infrastructure.
On-prem deployment should be treated as a serious platform program, not a procurement checkbox. The team needs hardware capacity planning, model update processes, access control, audit logging, patching, backups, incident response, evaluation, monitoring, and support ownership. If those operating responsibilities are not funded, a private cloud or VPC pattern may deliver enough control with less fragility.
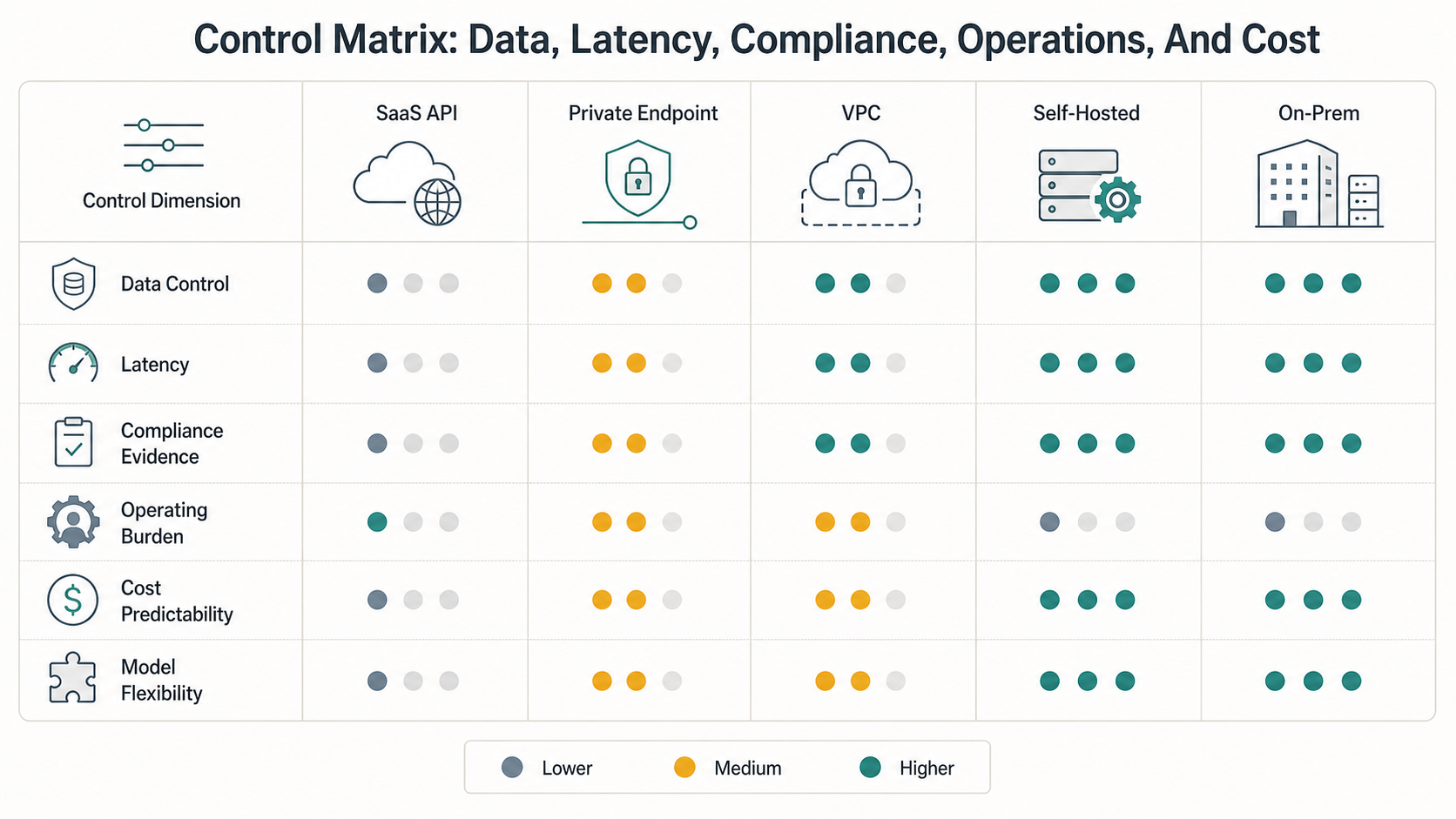
Control Matrix: Data, Latency, Compliance, Operations, And Cost
The more private the deployment, the more ownership the organization accepts. That ownership can be valuable, but only when it maps to real risk or business differentiation. A regulated workflow with sensitive data may need stronger boundaries; a low-risk productivity assistant may not.
Readiness Checklist Before You Choose Infrastructure
Infrastructure choice should come after readiness work. The Enterprise AI Readiness Checklist is a useful starting point because it forces the team to define workflow clarity, data access, integrations, security, governance, and human review before model selection.
- Workflow: Which decision, document, conversation, or operational task will GenAI support?
- Data boundary: What sensitive data appears in prompts, retrieval, logs, files, or model outputs?
- Integration: Which systems need read or write access, and what permissions are required?
- Risk level: Could the output affect money, eligibility, compliance, health, legal obligations, or customer trust?
- Review: Where does human approval stay mandatory?
- Evidence: What logs, model versions, prompt versions, source documents, and decisions must be retained?
- Operations: Who owns uptime, cost, model quality, incidents, security updates, and vendor changes?
For agentic workflows, run the AI Agent Readiness Assessment before choosing private infrastructure. A low readiness score is a sign to simplify the workflow before investing in a heavier deployment model.
Governance Controls Regulated Teams Should Design First
Private deployment does not automatically create responsible AI. Regulated teams need controls in the product, data pipeline, infrastructure, and operating process. Start with role-based access, source permissions, prompt and retrieval logs, approved model routes, output review, escalation paths, model-change approval, red-team tests, cost thresholds, and incident response. For action-taking systems, extend those controls with the permissions, monitoring, rollback, and handoff model described in enterprise AI agent governance.
Compliance teams should be involved before the architecture is locked. If the AI system may fall under emerging regulatory obligations, use an AI compliance readiness checklist to define evidence needs early. Engineering can then design logs, review queues, and data lineage into the system instead of rebuilding them after launch.
Evidence Pack Security Teams Should Request
A private deployment review should end with evidence, not only architecture diagrams. Ask for a launch pack that includes data-flow diagrams, source-system permissions, prompt and retrieval versioning, model and provider records, route policies, evaluation results, red-team findings, access logs, retention rules, incident runbooks, cost thresholds, and rollback criteria. This gives security, legal, compliance, and operations teams a shared artifact for approval and later audits.
The evidence pack also keeps scope honest. If a vendor cannot explain which logs prove data boundaries, which tests catch model regressions, or which human review points remain mandatory, the project is not ready for a high-risk deployment pattern.
Private GenAI Runbook For Regulated Launches
A private GenAI deployment should end with a launch runbook, not just an infrastructure choice. Regulated teams need one place where security, legal, compliance, product, and operations can see which prompts are allowed, where data is processed, how model routes are chosen, who can approve exceptions, and what evidence proves the system can be safely expanded.
Use the runbook to connect vendor commitments with internal controls. OpenAI's current business-data guidance says API data is not used to train models unless the customer opts in, and Azure AI Foundry documents that prompts and completions are not used to train or improve base models. Those commitments still need local evidence: route policy, retention setting, tenant boundary, redaction rule, audit log, retrieval-source list, and incident owner. That evidence is what separates a private GenAI pilot from a production deployment.
| Runbook Lane | Evidence To Attach | Decision It Supports |
|---|---|---|
| Data boundary | Provider data-use terms, region choice, retention setting, encryption owner, and zero-retention exception notes | Can this workload process regulated or customer data through this route? |
| Model route | Approved SaaS API, private endpoint, VPC/BYOC, self-hosted, or on-prem route with fallback rules | Which model path is allowed for each workflow and risk level? |
| Retrieval and tools | Allowed indexes, source freshness, tool scopes, connector owners, and blocked data classes | Can the system answer or act without exposing restricted records? |
| Security testing | Prompt-injection tests, sensitive-output checks, access tests, jailbreak review, and model gateway logs | Does the release account for OWASP LLM risks before users expand usage? |
| Operations | Monitoring dashboard, escalation owner, rollback path, cost threshold, and incident replay packet | Can support and engineering respond when the model, prompt, retrieval source, or vendor route misbehaves? |
NIST's AI RMF and Generative AI Profile are useful because they push the team to govern, map, measure, and manage risk instead of treating private deployment as a one-time hosting decision. For implementation planning, tie this runbook to machine learning development services so model evaluation, monitoring, and release evidence are designed together. If the GenAI workflow can trigger tasks across CRM, ERP, support, or operations systems, connect it to AI automation services planning so tool scopes, approvals, and rollback paths are built before automation expands.
Questions To Ask A GenAI Deployment Partner
A private GenAI partner should be able to discuss workflow risk, infrastructure, security, data, evaluation, and operations in the same conversation. If the discussion stays only at model demos, the project is likely under-scoped.
- Which deployment options do you recommend for this workflow, and which option would you reject?
- How will sensitive data be filtered, stored, retrieved, logged, and deleted?
- What evidence will security, audit, legal, or compliance teams receive?
- How will model quality be evaluated before and after launch?
- What happens when the model provider changes pricing, policies, availability, or model behavior?
- Who owns prompts, retrieval configuration, access policies, observability, and incident response?
- How can the architecture move from SaaS to VPC, self-hosted, or on-prem later if requirements change?
Use an AI development company evaluation checklist alongside these questions so the partner is assessed on delivery discipline, not only AI fluency.
How NextPage Helps Regulated Teams Deploy Private GenAI
NextPage helps regulated and security-conscious teams move from AI idea to deployment architecture. We map the workflow, classify data risk, compare SaaS, private endpoint, VPC, self-hosted, and on-prem options, then design the first production slice around governance, observability, evaluation, and support.
Our AI development services cover practical enterprise automation, LLM products, retrieval systems, human-in-the-loop workflows, security controls, and production rollout. If private GenAI is on your roadmap, bring the workflow, data sources, compliance constraints, existing cloud stack, and support expectations. We will help you choose the smallest deployment pattern that can meet the risk bar without overbuilding the platform.