
Stable Diffusion app development cost in 2026 usually starts around $35,000 to $70,000 for a narrow API-first MVP, $75,000 to $160,000 for a production workflow app, and $180,000 to $350,000+ for a private GPU-backed or hybrid platform. The model call is only one line item. The real budget comes from prompt controls, queueing, storage, moderation, asset review, model routing, analytics, support, and the operating discipline needed to keep image generation reliable after launch.
For most teams, the safest first release is API-first: prove one repeatable workflow, measure accepted outputs, and delay private GPU infrastructure until privacy, volume, latency, or custom-model needs are real. If you already know the product needs private assets, custom LoRA/style workflows, strict latency, high steady throughput, or customer-specific deployment, treat the project as a platform build rather than a simple AI feature.
This guide is for founders, CTOs, product managers, marketing operations leaders, and AI product teams budgeting a Stable Diffusion-powered app, image generation workflow, or internal creative automation tool. If you need implementation support for production image workflows, NextPage's Stable Diffusion development services page covers the service path behind this cost model.
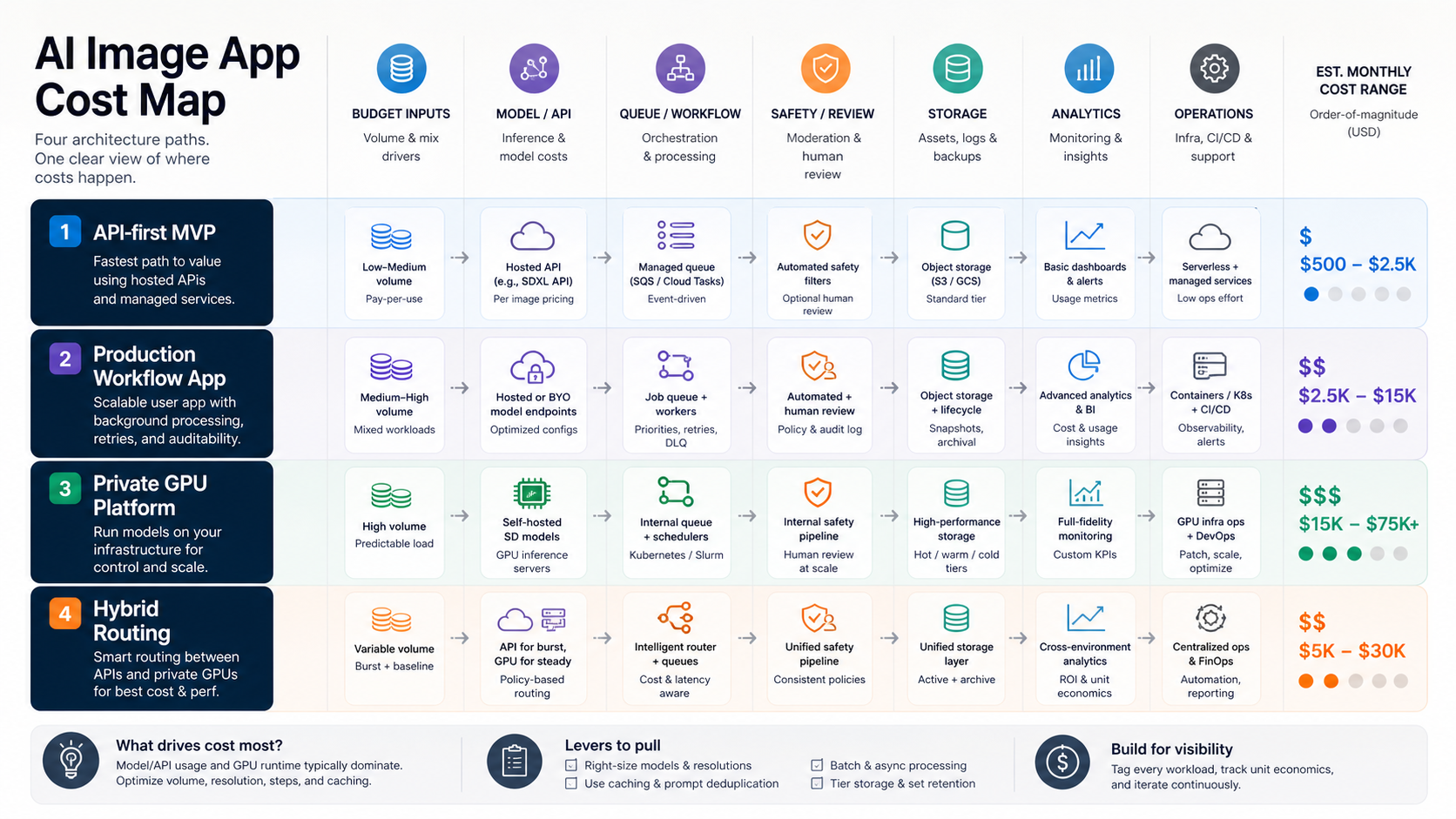
Quick Cost Ranges For Stable Diffusion App Development
Use these bands as planning ranges, not fixed quotes. Final cost depends on product type, release-one workflow, platform coverage, integration count, moderation depth, compliance needs, and whether the app uses a managed API, model platform, private GPU stack, or hybrid routing.
| Scope | Typical Budget | Best Fit | Main Cost Drivers |
|---|---|---|---|
| Prototype or internal proof of concept | $12,000-$30,000 | Validate one workflow with a small user group | Prompt UI, managed API connection, basic output history, light admin controls |
| API-first MVP | $35,000-$70,000 | Launch a focused web or mobile image tool | Accounts, payments or credits, templates, moderation, storage, analytics, QA |
| Production workflow app | $75,000-$160,000 | Agencies, ecommerce, media, marketing, or internal creative operations | Roles, approvals, brand presets, batch jobs, asset library, integrations, reporting |
| Private GPU or hybrid platform | $180,000-$350,000+ | High volume, private data, custom models, strict control | GPU orchestration, model serving, observability, evaluation, uptime, security, incident response |
The fastest way to lower estimate risk is to scope the product system, not only the generation endpoint. Run the first release through the MVP Scope Builder, then pressure-test the budget with the custom software cost estimator.
What Actually Drives The Cost?
Stable Diffusion app cost is shaped by seven decisions.
Product workflow: a single prompt box is cheap. A useful workflow may need prompt libraries, negative prompts, reference images, ControlNet-style guidance, batch generation, approval status, saved brand styles, version history, team folders, export formats, and comments.
Deployment model: managed APIs reduce infrastructure work and fit most MVPs. Self-hosting can make sense for private workloads or heavy volume, but it adds DevOps, GPU scheduling, monitoring, scaling, model loading, and incident response.
Safety and rights controls: business users need prompt policy, blocked terms, output review, user reporting, audit logs, retention rules, watermark/provenance decisions, and escalation paths for unsafe or off-brand generations.
Asset storage: generated images create storage, CDN, deletion, metadata, search, and retention requirements. Once teams adopt the app, they also ask for favorites, folders, campaign links, and export history.
Custom model work: LoRA or DreamBooth-style fine-tuning, brand style matching, product image consistency, and evaluation datasets can add meaningful cost. Model work must include versioning, comparison, rollback, and quality tests.
Integration count: Shopify, DAM, CMS, social scheduling, Slack approvals, SSO, CRM, and product catalogs often cost more than model integration because they define how generated assets enter real business workflows.
Evaluation and analytics: the app should track cost per accepted asset, rejection rate, generation latency, failed jobs, model version performance, prompt template effectiveness, and spend by workspace or customer.
Managed API Vs Self-Hosted GPU
For most first releases, managed API is the pragmatic path. Current model providers make it possible to prototype image generation without owning GPU operations, compare output quality, and learn which prompts users repeat. API-first does not mean shallow; the first release can still include billing, usage limits, admin reporting, moderation, queueing, and asset review.
Private GPU hosting becomes attractive when the product has steady high volume, sensitive customer assets, customer-specific deployment requirements, custom model workflows, or strict latency and rollback needs. The tradeoff is operational weight: GPU uptime, cold starts, autoscaling, storage, network transfer, observability, security patches, model optimization, and people who can debug inference failures.
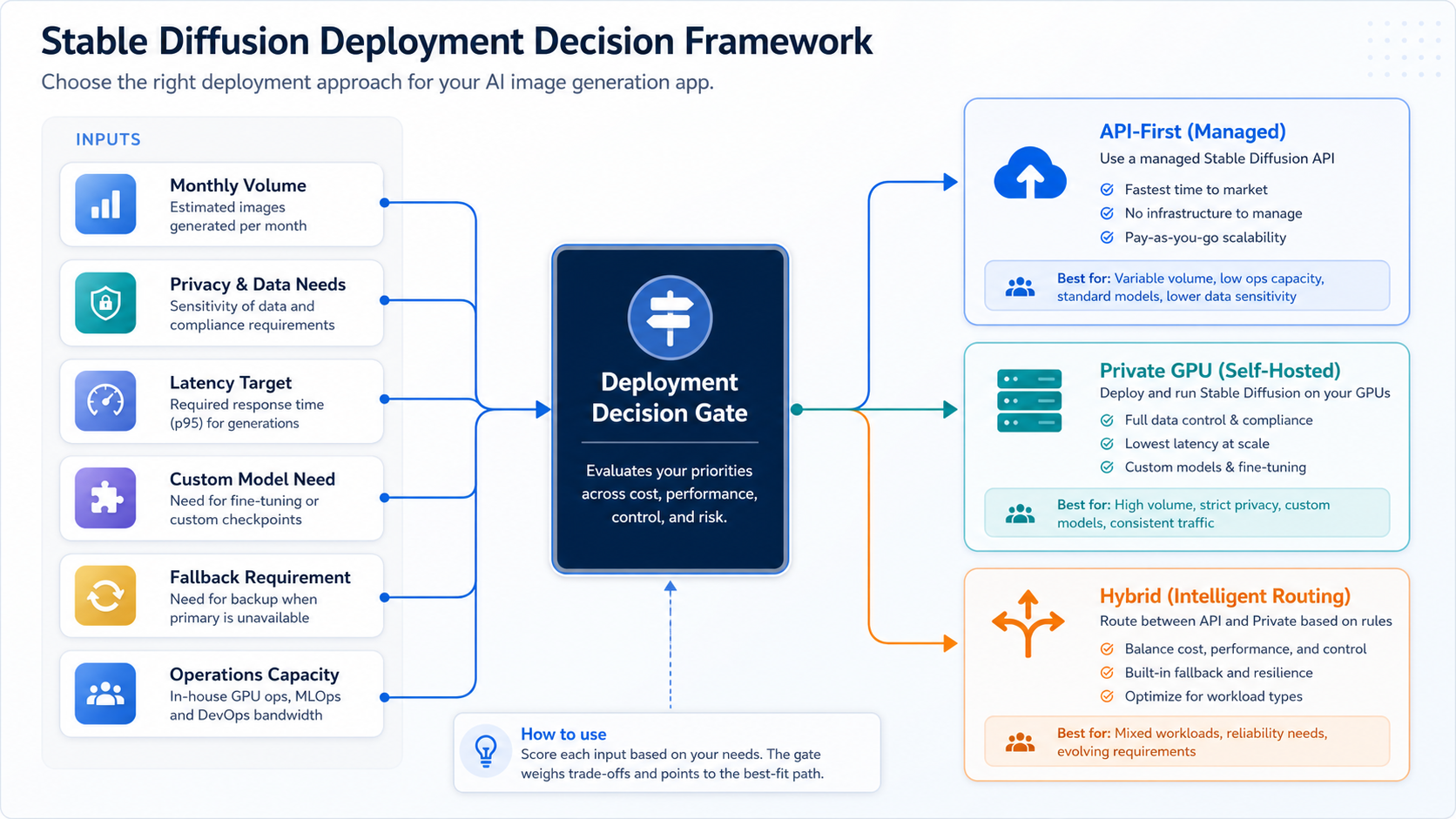
| Choice | Pros | Risks | Use It When |
|---|---|---|---|
| Managed API | Fast launch, less infrastructure, simpler vendor support | Vendor pricing, data handling constraints, less low-level control | You are validating demand or serving moderate volume |
| Model platform | Many models, flexible experimentation, hardware-time pricing | Provider-specific reliability, data terms, and performance variance | You need model variety without managing GPUs |
| Self-hosted GPU | Control, privacy, routing, and possible unit-cost gains at scale | Idle capacity, DevOps complexity, incident response | You have high volume, private workflows, or custom model needs |
| Hybrid | Balance speed, privacy, quality tiers, and fallback | More architecture, billing, QA, and observability work | You need different routes by customer, asset type, or SLA |
For adjacent product architecture decisions, use NextPage's AI image generation app development guide as a companion to this cost breakdown.
What Should Be In The MVP?
A strong MVP proves one user job and one output category. Examples include ecommerce product-background generation, ad concept variations, game asset ideation, real estate image enhancement, localized campaign creative, or internal brand-approved draft generation.
The MVP feature set usually includes authentication, workspace or project organization, prompt templates, generation settings, a model/API adapter, async job status, output history, download/export, basic moderation, cost tracking, and admin controls. Paid products need subscriptions, credits, usage limits, invoices, failed-payment handling, and abuse prevention. Internal tools need SSO, workspace quotas, audit logs, and permission roles.
Do not put custom training, marketplace features, native mobile apps, and multi-provider routing into release one unless they are central to the business model. A narrower MVP helps the team learn which prompts users repeat, which outputs they accept, and where generation cost is wasted.
Architecture Plan For A Production App
A production Stable Diffusion app needs a controlled request path. The user submits a prompt, reference image, product SKU, campaign brief, or brand preset. The app checks policy, workspace credits, file constraints, and permissions. The job enters a queue. A routing layer chooses managed API, model platform, private GPU worker, or fallback route. The output is stored with metadata, reviewed by automated and human checks when needed, and returned with usage, cost, and quality events.
- Input layer: prompt, reference image, product data, brand preset, target format, and user intent.
- Policy layer: blocked input checks, file validation, brand rules, role permissions, and workspace quotas.
- Queue layer: asynchronous jobs, retries, cancellation, rate limits, and progress states.
- Model router: managed API, model platform, private GPU worker, fallback path, and version rollback.
- Storage layer: original inputs, generated outputs, thumbnails, metadata, retention, deletion, and search.
- Review layer: automated checks, human approval, comments, rejection reasons, and audit history.
- Integration layer: CMS, Shopify, DAM, product catalog, social scheduler, Slack, analytics, or internal dashboards.
- Measurement layer: cost, latency, failure rate, accepted output rate, model quality, and user retention.
This is why Stable Diffusion projects overlap with production generative AI development. The model is only one component; the product also needs orchestration, permissions, evaluation, monitoring, UI design, and operating workflows.
Budget Breakdown By Workstream
For an API-first MVP in the $35,000-$70,000 range, a common split is 20%-30% product discovery and UX, 25%-35% frontend and backend development, 10%-20% AI/model integration, 10%-15% moderation and admin tooling, 10%-15% QA and launch hardening, and 5%-10% project management and DevOps.
For a production workflow app, expect more time in roles, permissions, billing, integrations, and asset management. For a private GPU platform, expect a larger share in infrastructure, model serving, evaluation, security, and reliability. The cost pattern starts to look less like a simple app and more like a specialized SaaS system.
Use labor-rate comparisons carefully. A low hourly rate will not save a project that lacks product decisions, safety rules, acceptance criteria, and a deployment plan. For broader budgeting context, compare your scope against NextPage's custom software development cost guide.
Operating Costs Buyers Miss
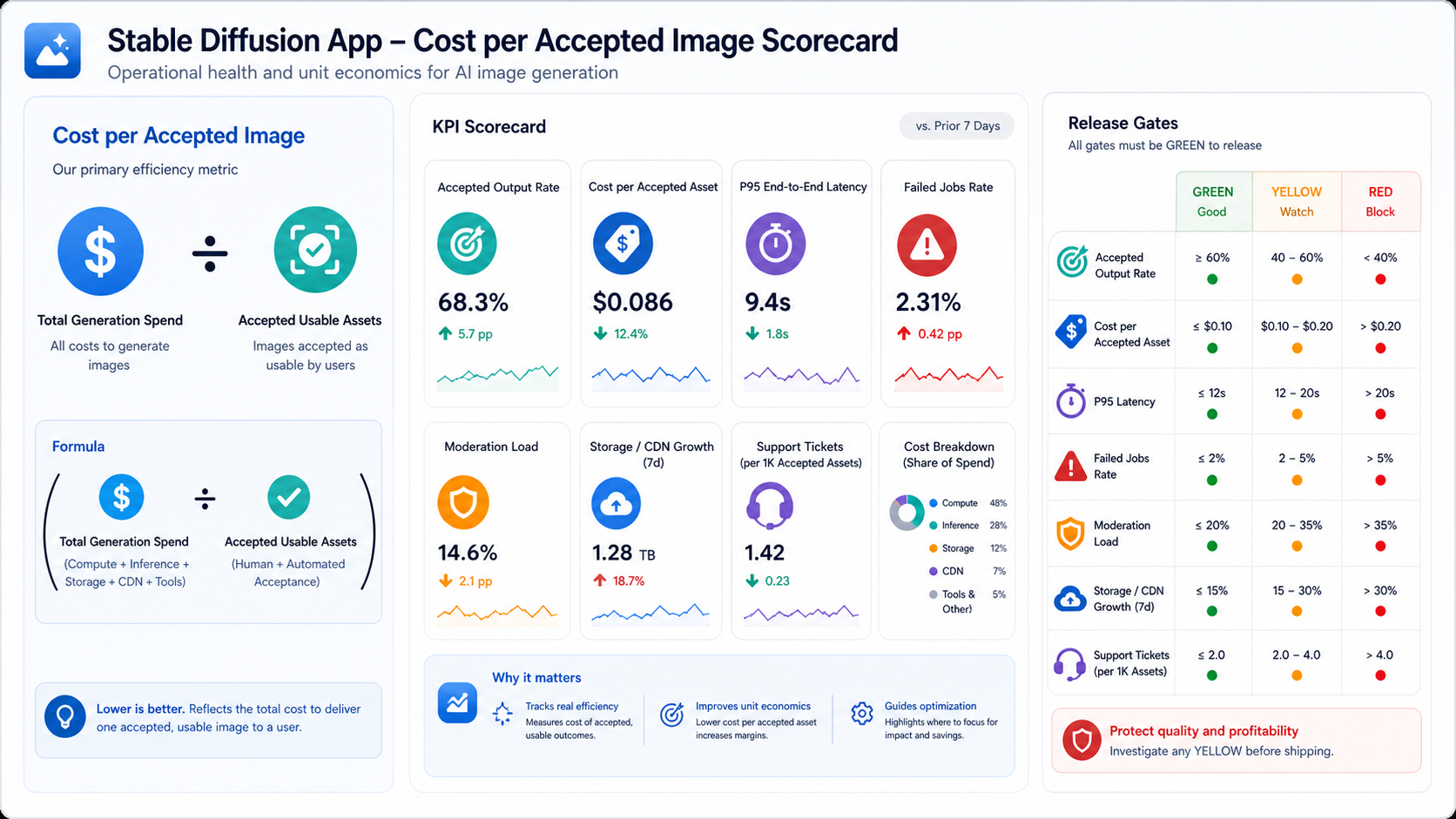
Post-launch cost can surprise teams because image products have variable usage. Budget for API credits or GPU hours, object storage, CDN traffic, database growth, logs, monitoring, moderation review, support, provider changes, model evaluation, and abuse prevention. Public tools also need rate limits, payment checks, workspace quotas, user reporting, and support escalation.
The most useful metric is cost per accepted asset, not only cost per generated image. If users generate ten variants and approve two, the accepted asset cost is five times the raw model call before storage, review, support, and engineering maintenance are included.
| Metric | Why It Matters | Owner |
|---|---|---|
| Accepted output rate | Shows whether prompts, routing, and review are producing usable images | Product and creative operations |
| Cost per accepted asset | Connects model spend, storage, review, and support to business value | Finance and product |
| Latency p95 | Reveals whether queue and model route fit the user workflow | Engineering |
| Failed job rate | Surfaces provider, GPU, queue, or file-handling reliability issues | Engineering and support |
| Moderation queue volume | Shows safety workload and abuse pressure before it overwhelms operations | Trust, safety, and operations |
As a planning formula, treat cost per accepted asset as total generation, storage, review, and support cost divided by approved assets. That one metric keeps model decisions tied to product value instead of raw output volume.
How To Reduce Cost Without Weakening The Product
- Start API-first. Use managed generation until volume, privacy, latency, or quality requirements justify GPU work.
- Constrain the job. Build for one repeatable use case instead of a generic image playground.
- Cache and reuse outputs. Save prompt settings, seeds, thumbnails, and accepted assets so users do not regenerate the same work.
- Use asynchronous queues. A queue protects the UI, supports retries, and gives the business a cost-control point.
- Add quality gates early. Prompt templates, blocked terms, image size limits, and workspace quotas prevent waste.
- Measure accepted output rate. Optimize prompts and model route around approved assets, not raw generations.
- Postpone custom model training. Fine-tuning should follow evidence that base models and prompt systems cannot meet the workflow.
When Should You Build A Stable Diffusion App?
Build when image generation is part of a repeatable workflow users already understand: product photography variants, ad creative drafts, marketing localization, game concept ideation, social content operations, architecture moodboards, or internal brand asset production. Do not build only because the model is impressive. Build when the workflow saves time, reduces creative bottlenecks, creates new revenue, or improves consistency at scale.
The right first question is not whether Stable Diffusion is cheaper than another model. It is whether your users need a controlled workflow around image generation. If yes, define the workflow, pick the deployment model, set usage controls, and launch the narrowest version that can prove value.
Next Steps For Budget Planning
Before asking for quotes, prepare five inputs: target user workflow, expected monthly generation volume, privacy requirements, model/provider preference, and integrations around generated assets. With those inputs, an engineering team can estimate the product and the operating model instead of guessing from a feature list.
NextPage can help turn that into a build plan, architecture estimate, and MVP roadmap. Start with a scoped estimate, then decide whether the first release should be API-first, hybrid, or GPU-backed.