
Quick Answer: What Is An Agentic SOC Implementation Roadmap?
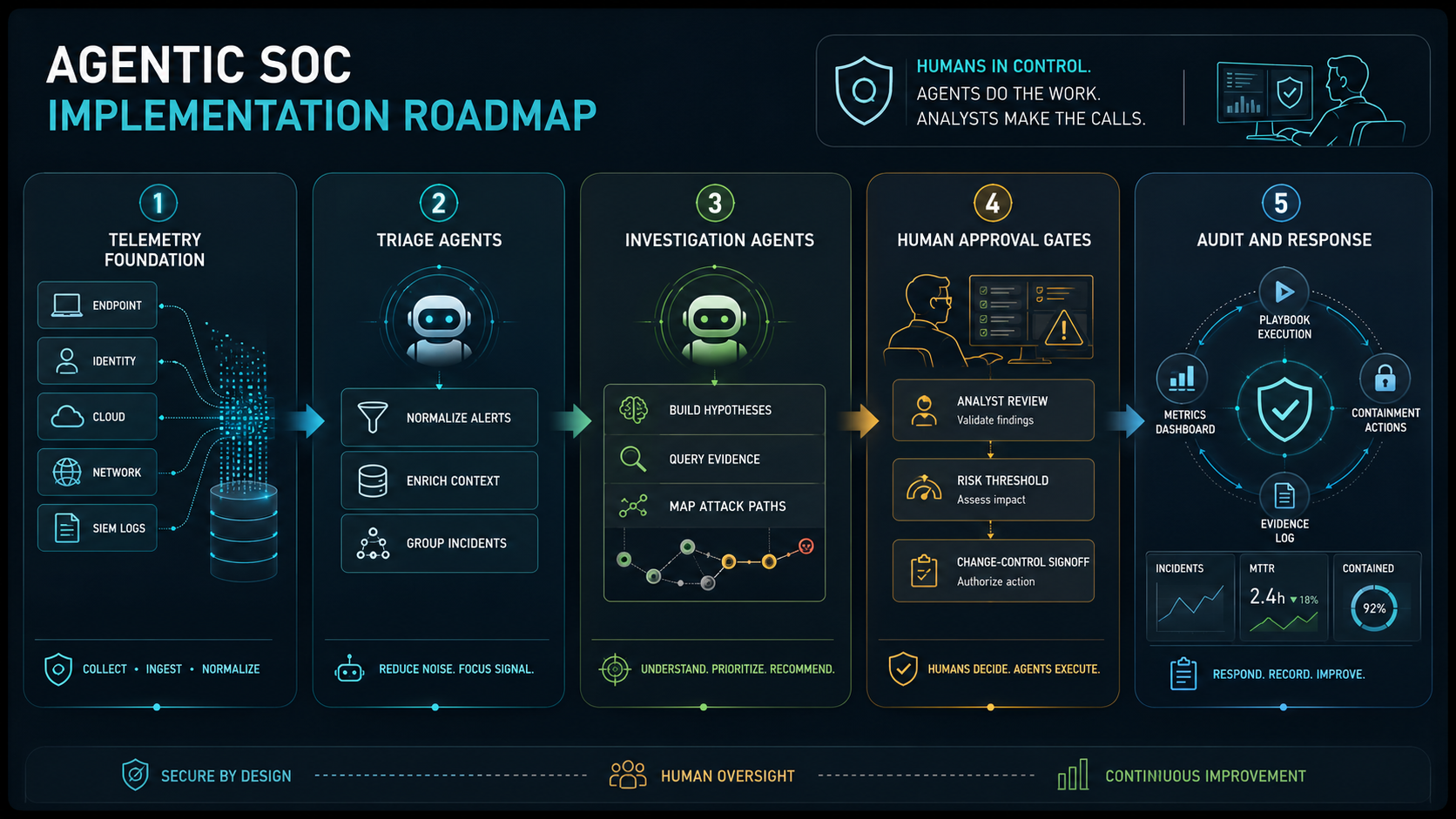
An agentic SOC implementation roadmap is a phased plan for using AI agents inside security operations without handing over uncontrolled response authority. It defines which alerts agents can triage, which evidence they can collect, which tools they can call, which playbooks they can recommend, when a human must approve action, how every decision is logged, and how performance is measured after release.
The practical goal is not to replace analysts. The goal is to reduce alert fatigue, speed up evidence gathering, make playbook execution more consistent, and give senior analysts better incident context. Mature teams treat SOC agents like privileged operational systems: scoped access, clear runbooks, monitored outputs, rollback paths, and audit evidence.
If your team is still deciding whether a workflow is ready for agent support, start with the AI Agent Readiness Assessment. Security workflows need stricter readiness gates than ordinary back-office automation because poor evidence, weak permissions, or missing review paths can turn a useful assistant into operational risk.
Start With SOC Readiness, Not Agent Autonomy
The fastest way to fail with an agentic SOC is to start with the question, "What can the agent do by itself?" A better first question is, "Which SOC workflow has enough volume, evidence, repeatability, review capacity, and risk controls to benefit from agent assistance?"
Good first candidates usually have high alert volume, repetitive enrichment steps, clear escalation rules, and low downside when the agent is limited to evidence gathering or recommendation. Examples include phishing intake triage, duplicate alert clustering, endpoint alert enrichment, identity-risk summary, cloud misconfiguration explanation, known IOC lookups, and draft incident summaries. Weak first candidates include production isolation, account lockout, firewall changes, broad data deletion, customer notification, and any workflow where evidence is fragmented or ownership is unclear.
The AI workflow automation guide is useful here because an agentic SOC is still a workflow automation problem. You need intake, context retrieval, decision rules, action boundaries, human review, monitoring, and continuous improvement. Security adds higher stakes, stronger evidence requirements, and tighter permissions.
| Readiness Area | What To Confirm | Why It Matters |
|---|---|---|
| Workflow scope | One alert type or playbook is clearly bounded | Prevents the first agent from becoming an untestable general SOC assistant |
| Evidence sources | SIEM, EDR, identity, cloud, network, and ticket data are accessible | Agents cannot reason reliably from partial telemetry |
| Decision rules | Escalation and suppression criteria are documented | Analysts can review agent behavior against known policy |
| Action boundary | Allowed tools and forbidden actions are explicit | Reduces accidental containment, lockout, or business disruption |
| Review capacity | Humans can approve, correct, and label outcomes | Creates the feedback loop needed to improve safely |
Build The Telemetry Foundation Agents Need
Agentic SOC initiatives often expose the same visibility gaps analysts already live with. Endpoint data may be rich while identity context is thin. Cloud logs may be delayed. Network telemetry may be sampled. SaaS audit logs may be missing. Asset ownership may live in spreadsheets. If analysts cannot get a coherent incident picture quickly, an agent will not magically infer it.
Before adding agents, map the evidence needed for each workflow. For a suspicious login, that may include identity provider logs, device posture, geo-location, impossible travel signals, MFA method, recent password changes, session token events, SaaS activity, privileged role membership, endpoint health, and related alerts. For an endpoint malware alert, the evidence set may include process tree, hash reputation, command line, parent process, user, network connections, file writes, persistence artifacts, vulnerability exposure, and business owner.
Use a source-of-truth matrix. For each data object, record the system, owner, retention period, freshness, API access, permissions, rate limits, and failure mode. Agents should retrieve evidence through approved interfaces, not analyst credentials or uncontrolled browser sessions. For teams still formalizing data and governance, the Enterprise AI Readiness Checklist gives a broader way to assess data, workflow, security, and ownership before production AI work begins.
Choose The First Agentic SOC Use Cases
A practical roadmap starts with supervised assistance, then moves toward controlled automation only after evidence quality and review outcomes are stable. The first use case should be narrow enough to test against historical incidents and current analyst judgment.
| Use Case | Agent Role | Human Role | Automation Level |
|---|---|---|---|
| Alert deduplication | Group related alerts, summarize shared entities, identify likely incident cluster | Confirm cluster and assign owner | Low |
| Phishing triage | Extract indicators, check sender history, inspect links safely, draft verdict | Approve classification and user response | Low to medium |
| Endpoint investigation | Collect process, network, hash, user, and asset evidence | Decide containment or escalation | Medium |
| Cloud alert enrichment | Explain resource context, IAM exposure, related changes, and blast radius | Approve remediation ticket or emergency change | Medium |
| Detection tuning | Find noisy rules, suggest threshold changes, draft detection logic | Review logic, test, and approve deployment | Medium |
The AI agent development cost guide explains why budget depends on workflow depth, tool access, evaluation, and governance rather than the word "agent." A SOC agent that only drafts investigation summaries is very different from one that can call EDR, SOAR, IAM, ticketing, and cloud APIs.
Design Human Approval Gates Before Response Automation
Human approval should not be an afterthought added after the first scary demo. It should be part of the system design. Define approval gates by action risk, confidence threshold, asset criticality, customer impact, data sensitivity, and reversibility.
Low-risk actions can often be automated after a warm-up period: attach evidence to a ticket, mark duplicate alerts, add a note to an incident, request more logs, enrich an IOC, or draft a user message. Medium-risk actions usually need analyst confirmation: create a remediation ticket, escalate severity, suppress a noisy rule for a limited period, request endpoint scan, or recommend access review. High-risk actions should require explicit approval, change record, and rollback plan: isolate a production server, disable a privileged account, block a network range, revoke tokens, delete files, or notify external stakeholders.
Approval should capture who approved, what evidence was shown, which policy or playbook applied, what action was taken, what changed, and how the team can reverse it. This is where SOC agents overlap with release governance. The AI Development Lifecycle article is a useful companion for release gates, evaluations, monitoring, and production governance.
Turn Playbooks Into Auditable Agent Workflows
Many SOC playbooks are written for humans: check this console, search this query, compare this field, escalate if suspicious. Agents need a more explicit workflow contract. Each step should specify the tool, input, output, timeout, fallback, permission scope, and audit event.
| Playbook Step | Agent Contract | Audit Evidence |
|---|---|---|
| Normalize alert | Parse source, severity, entity, timestamp, rule, and affected asset | Raw alert reference and normalized fields |
| Enrich context | Query approved SIEM, EDR, identity, cloud, and asset sources | Queries, timestamps, returned evidence, and missing-source notes |
| Build hypothesis | Explain likely benign and malicious interpretations | Reasoning summary tied to evidence, not hidden chain-of-thought |
| Recommend action | Map to allowed playbook actions and approval level | Recommended action, risk level, confidence, and required approver |
| Execute approved response | Call only scoped tools after approval | Approver, command/API call, result, rollback note |
Security teams should also maintain negative playbooks: actions an agent must never take, evidence that is insufficient for escalation, and conditions that force human-only handling. If your team is already improving security release controls, connect this work to a DevSecOps pipeline checklist so detection changes, secrets, scans, and release gates are managed consistently.
Reference Architecture For An Agentic SOC
A production-ready agentic SOC architecture usually has five layers. The first is the telemetry layer: SIEM, EDR, identity, cloud, network, vulnerability, asset, email, ticketing, and threat intelligence data. The second is the retrieval and tool layer: approved APIs, query templates, rate limits, secrets management, scoped service accounts, and logging. The third is the agent layer: triage, investigation, detection-engineering, reporting, or playbook agents with narrow responsibilities. The fourth is the governance layer: policy checks, confidence thresholds, approval gates, prompt and tool versioning, evals, and safety tests. The fifth is the operations layer: dashboards, incident review, model performance, analyst feedback, cost tracking, and change management.
Do not make every agent capable of everything. A triage agent should not need the same access as a response agent. A detection engineering agent should not have production containment permissions. A reporting agent should not query raw secrets. Scoped roles reduce blast radius and make audit review easier.
For broader implementation sequencing, use the AI implementation roadmap. It helps teams move from use-case selection to data readiness, prototype, pilot, production rollout, and optimization without skipping governance.
A Phased Agentic SOC Rollout Plan
Start in shadow mode. The agent reads historical and live alerts, drafts triage notes, and recommends actions without affecting the production workflow. Compare its output to analyst decisions. Track false positives, missed context, hallucinated evidence, missing data, and analyst time saved.
Move next to assisted mode. The agent adds evidence to tickets, drafts investigation summaries, and recommends escalation, but analysts approve every classification and action. This is where teams refine prompts, tools, data contracts, confidence thresholds, and playbook language.
Only then should teams introduce limited automation. Start with reversible, low-risk actions such as duplicate grouping, ticket enrichment, low-confidence escalation requests, or evidence gathering. For medium-risk actions, require analyst approval. For high-risk response, keep explicit approval, change record, and rollback. Autonomy should increase by workflow and action class, not across the whole SOC at once.
| Phase | Scope | Exit Criteria |
|---|---|---|
| Phase 1: readiness | Workflow selection, telemetry audit, access model, policy review | Approved use case, evidence matrix, and risk boundary |
| Phase 2: shadow | Agent drafts triage and investigation notes without workflow changes | Measured agreement with analysts and known failure modes |
| Phase 3: assisted | Agent enriches tickets and recommends next steps | Human review quality, audit logs, and feedback loop are stable |
| Phase 4: controlled automation | Low-risk actions and approved medium-risk playbooks | Rollback tested, metrics improve, no unmanaged tool access |
| Phase 5: optimization | Detection tuning, broader playbooks, cost and performance tuning | Governance review, incident learning, and model/tool updates are routine |
Metrics, Failure Modes, And Governance
Agentic SOC metrics should combine security outcomes, analyst experience, operational reliability, and governance. Track mean time to triage, mean time to evidence, analyst review time, escalation accuracy, duplicate reduction, false-positive reduction, missed critical context, playbook completion rate, approval override rate, failed tool calls, cost per investigation, and audit completeness.
Also track failure modes. Did the agent cite evidence that did not exist? Did it miss identity context? Did it over-trust a threat-intelligence source? Did it recommend a response outside policy? Did it suppress an alert without enough evidence? Did it fail closed when a tool timed out? Did it expose data to the wrong user? These are not only model-quality issues. They are production system issues.
Governance should include versioned prompts, tool contracts, test cases, regression alerts, access reviews, incident review notes, and a clear owner for each playbook. SOC agents need the same seriousness as any system that touches production security controls.
How NextPage Helps Build Governed SOC Agent Workflows
NextPage helps teams turn AI agent interest into buildable, governed workflows. For SOC and security operations, that means choosing a narrow first use case, mapping telemetry, designing the agent/tool boundary, defining human approval gates, building evaluation sets, integrating with tickets or security tools, and measuring whether the workflow actually improves analyst throughput and incident quality.
We can help with AI readiness scoring, workflow automation architecture, secure agent design, internal tools, audit logging, dashboards, and phased rollout planning. The result should feel less like an AI demo and more like an operational system analysts can trust.
Start with the AI Agent Readiness Assessment, or use it as the first input for an agentic SOC implementation workshop.