
An AI assurance testing strategy is a release discipline for LLM, RAG, and agentic systems. It combines failure taxonomy, eval datasets, retrieval and grounding tests, safety checks, human review, release gates, production monitoring, and governance evidence so teams can reduce AI risk continuously instead of relying on a few demo prompts before launch.
The practical version is not "run an eval tool." It is an operating model: define what can go wrong, create evidence for the riskiest behaviors, block releases when those behaviors regress, and feed production failures back into the test set. That is how AI quality becomes part of software delivery instead of a one-time model benchmark.
This guide is written for engineering leaders, QA leads, AI product owners, and compliance-aware teams moving enterprise AI systems from prototype to production. If you are still deciding which workflow is ready for AI, start with the AI Agent Readiness Assessment; if the workflow is already selected, use this article to design the assurance layer around it.
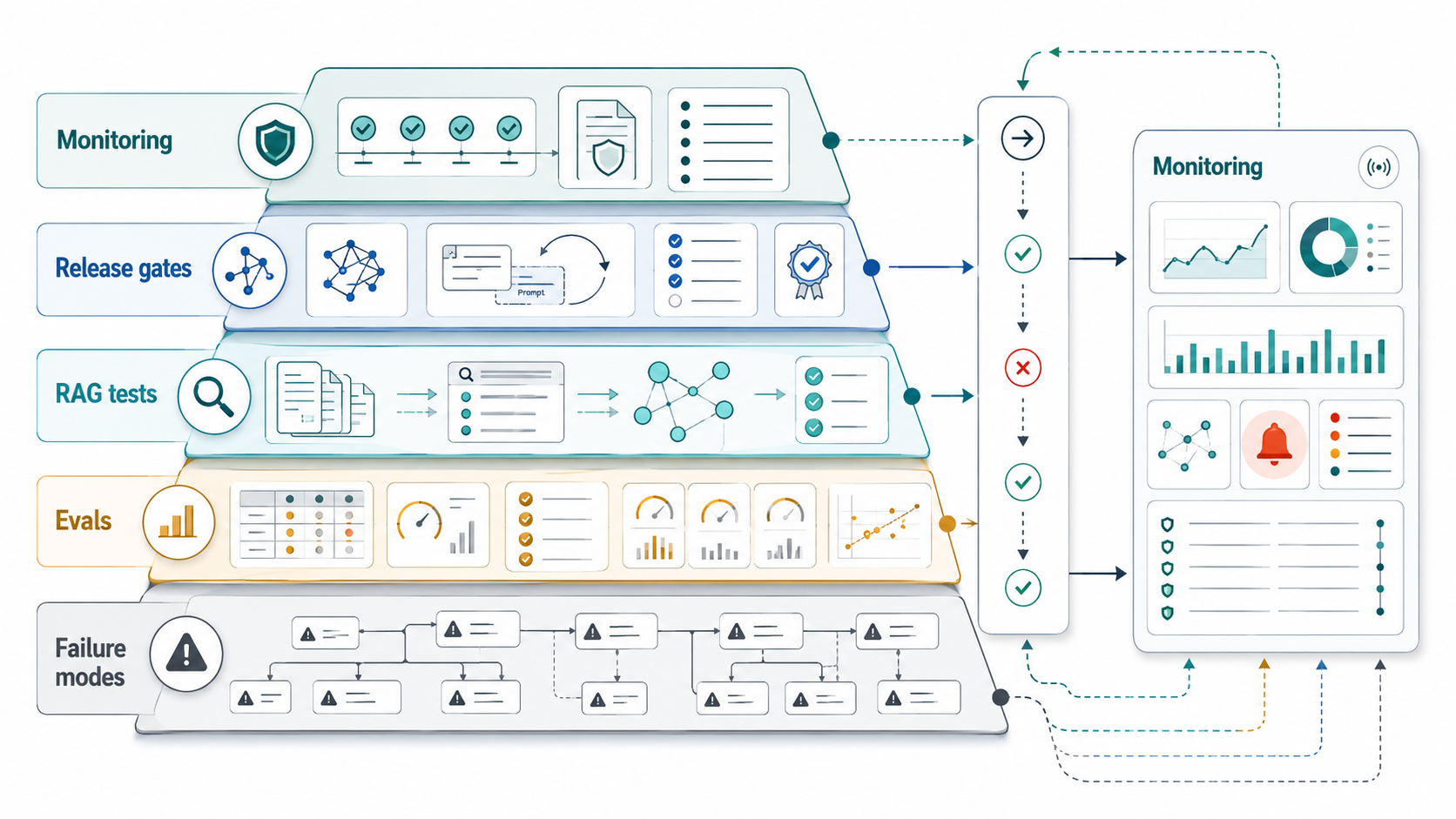
Quick Answer: AI Assurance Testing Strategy
An AI assurance testing strategy is a structured way to prove that an AI system is useful, bounded, monitored, and safe enough for the workflow it supports. It should define the system's failure modes, build representative eval datasets, test RAG quality separately, route high-impact outputs through human review, and turn quality evidence into release decisions.
For a simple internal assistant, the strategy may focus on answer quality, source grounding, privacy, and user feedback. For an agent that can call tools, update records, or affect customers, the same strategy must also test permissions, tool-call accuracy, approval thresholds, rollback paths, incident response, and audit evidence. Teams building agentic workflows should connect assurance with agentic AI development services from the first architecture sprint instead of adding checks after the demo works.
Why AI Assurance Is Different From Traditional QA
Traditional QA is built around expected behavior. A checkout flow either applies the correct discount or it does not. A report either includes the right rows or it does not. AI systems still need those tests around the surrounding product, but the AI layer adds uncertainty: prompts drift, retrieval changes, model versions update, user inputs vary, tool calls fail, and acceptable answers may require human judgment.
The 2026 AI assurance research that seeded this post argues for continuous risk reduction rather than strict correctness verification. That framing matters. A production AI system may be useful even when it cannot be proven correct for every input, but it must still be bounded, evaluated, monitored, and governed. The team needs evidence that the system improves the workflow without creating unacceptable safety, compliance, brand, operational, or financial risk.
For NextPage clients, that means AI delivery has to include more than model integration. Our AI development services evaluate workflow clarity, data sensitivity, latency, model quality, integration depth, and operating cost before the stack is finalized. The assurance strategy should be designed at the same time as the product architecture.
Build A Failure Taxonomy Before Writing Evals
A failure taxonomy is the map of what you are trying to catch. Without one, teams over-test the easy prompts and under-test the failures that would actually stop a rollout. The taxonomy should be specific to the product, not copied from a generic benchmark.
| Failure Mode | Example | Evidence To Collect |
|---|---|---|
| Task failure | The assistant cannot complete the intended workflow or chooses the wrong tool. | Scenario pass rate, tool-call trace, fallback handling |
| Grounding failure | The answer sounds plausible but is not supported by retrieved evidence. | Source relevance, citation checks, unsupported-claim review |
| Retrieval failure | The right answer exists in the knowledge base but the retriever misses it. | Recall@k, query coverage, freshness checks |
| Policy or safety failure | The system reveals sensitive data, gives disallowed advice, or skips escalation. | Adversarial prompts, policy rubrics, human review samples |
| Workflow boundary failure | An agent acts outside its permission scope or keeps looping after uncertainty. | Permission tests, stop conditions, audit log review |
| Operational failure | Latency, cost, retries, or dependency failures make the system unusable. | P95 latency, cost per task, failure-rate monitoring |
This taxonomy becomes the basis for the eval suite. Each important failure mode should have a test source: golden examples, synthetic adversarial cases, production incidents, user feedback, domain-expert reviews, or manual red-team sessions. NextPage's Enterprise AI Readiness Checklist uses the same principle: governance and data readiness are practical delivery requirements, not abstract policy documents.
Assign Ownership Before The Eval Suite Grows
AI assurance breaks down when every team assumes another team owns the evidence. QA can run repeatable checks, but it cannot decide business risk alone. Product can define expected outcomes, but it cannot instrument traces alone. Engineering can build eval pipelines, but it cannot judge domain-specific correctness alone. Compliance can approve controls, but it cannot rescue a workflow that was never narrowed.
| Owner | Assurance Responsibility | Evidence Artifact |
|---|---|---|
| Product owner | Define user job, success criteria, and unacceptable failure modes. | Workflow risk map and acceptance rubric |
| Engineering lead | Instrument prompts, retrieval, tool calls, latency, cost, and rollback paths. | Trace schema, gate runner, and deployment log |
| QA lead | Maintain eval cases, regression suites, defect taxonomy, and release report. | Versioned eval dataset and release checklist |
| Domain expert | Review judgment-heavy answers and calibrate scoring rubrics. | Human review samples and calibration notes |
| Security or compliance | Approve data handling, retention, access control, and incident workflow. | Control review and escalation policy |
This ownership model is especially important when the AI system is part of a larger product. In the FieldIQ portfolio case study, product value came from connecting role-aware operations, media workflows, and AI assistance rather than treating AI as an isolated feature. Assurance needs the same product discipline: every automated decision should have an owner, a trace, and a recovery path.
Design Eval Datasets That Match Real Risk
An eval dataset should look like the work the system will actually do. Do not fill it only with short, clean prompts. Include messy phrasing, missing context, adversarial attempts, stale-document scenarios, permission-boundary cases, ambiguous requests, and examples from production feedback. For RAG and agents, keep separate datasets for retrieval, answer quality, tool use, and policy behavior so failures are easier to diagnose.
A useful first eval set often has four tiers. Tier one covers known happy paths and launch-critical workflows. Tier two covers edge cases that users are likely to hit. Tier three covers safety, privacy, policy, and adversarial cases. Tier four captures real production failures as they happen. The team should version the dataset, keep examples tied to failure categories, and record which model, prompt, retrieval index, and tool version each release used.
If the workflow is still too broad to create representative examples, narrow it before building. The AI Automation ROI Calculator can help compare the value of candidate workflows before a team spends assurance effort on a low-return automation path.
The AI Assurance Pyramid For Enterprise Teams
Think of AI assurance as a pyramid rather than a single eval score. The base is ordinary software quality. The middle layers test AI behavior and workflow fit. The upper layers create release and governance evidence.
- Product and integration tests: permissions, API contracts, data flows, UI states, logging, and deterministic business rules.
- Unit-style AI checks: prompt templates, parser behavior, tool schemas, guardrail responses, and known edge cases.
- Scenario evals: realistic user tasks with expected outcomes, rubric scoring, and domain review.
- System evals: full workflow checks that include retrieval, model response, tool use, escalation, and audit trails.
- Production assurance: monitoring, drift detection, incident review, release gates, and governance reporting.
The pyramid helps teams avoid two common mistakes. The first is trying to solve AI quality entirely with model benchmarks. A high-performing foundation model can still fail inside your private workflow if retrieval, permissions, prompts, or tool boundaries are weak. The second is treating deterministic tests as enough. They protect the app shell, but they do not tell you whether the AI answer was grounded, safe, useful, and acceptable for the user job.
If your AI product includes document search, summarization, copilots, or internal knowledge workflows, the assurance pyramid should connect directly to the architecture. NextPage's LLM development and enterprise RAG implementation services focus on evaluation, retrieval design, workflow integration, and operating controls together because those pieces fail together in production.
RAG Testing Needs Its Own Assurance Layer
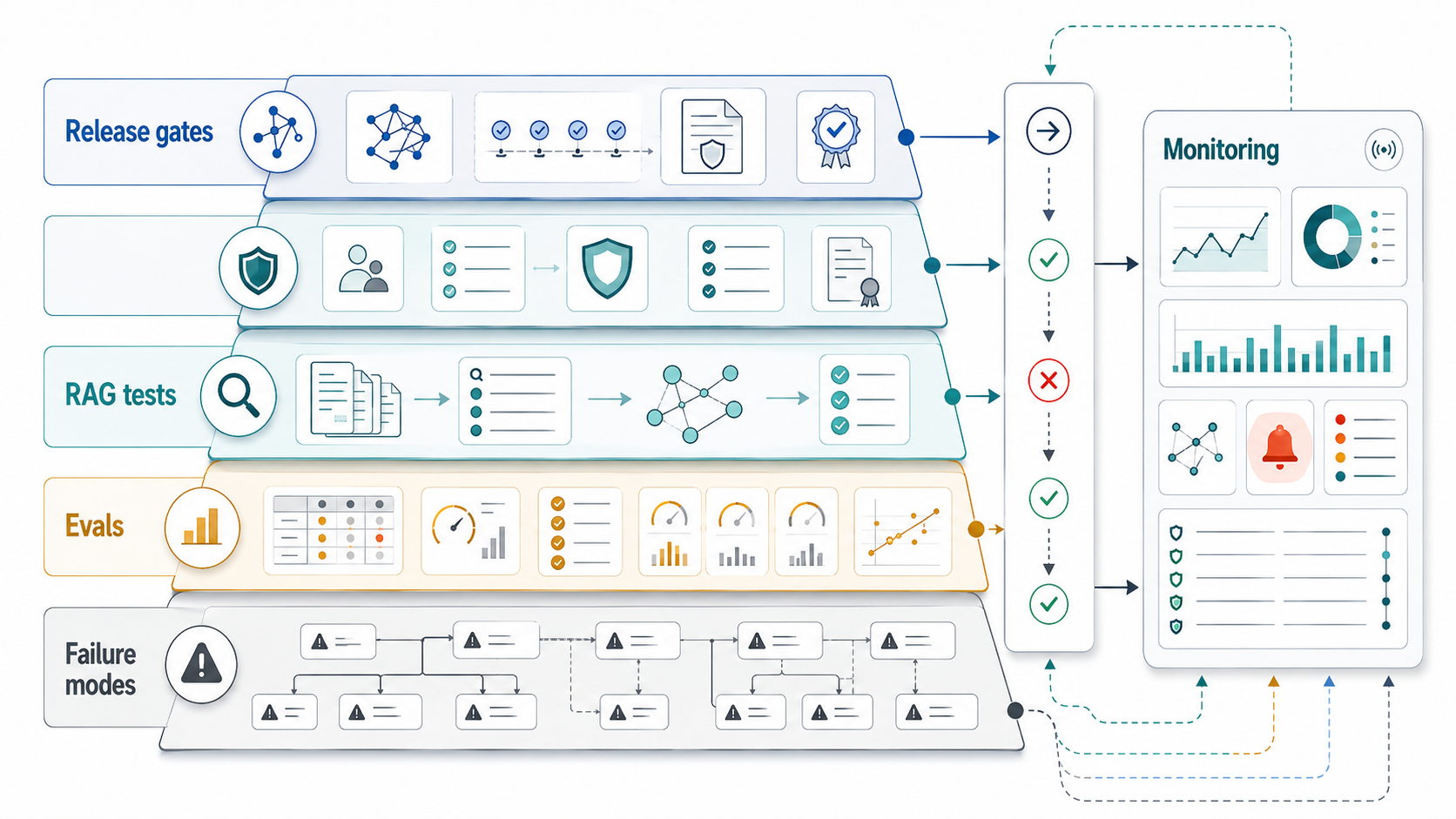
RAG systems fail in ways that ordinary prompt tests hide. An answer can be fluent but unsupported. A retriever can return stale policy. A chunking strategy can bury a decisive exception. A model can cite the right source while misreading it. A test that only grades the final answer will not tell you which layer broke.
Separate RAG assurance into four checks: query coverage, retrieval quality, grounding quality, and regression quality. Query coverage should include common questions, rare edge cases, messy phrasing, multilingual or acronym-heavy inputs, and adversarial prompts. Retrieval quality measures whether the right documents, policies, tickets, or records appear in the context window. Grounding checks whether answer claims are supported by retrieved evidence. Regression quality reruns stable query sets when embeddings, chunking, prompts, rerankers, source documents, or model versions change.
For teams starting with QA rather than AI engineering, NextPage's QA automation testing services can help separate repeatable regression checks from human-led review. The same split applies to RAG: automate what is stable, sample what requires judgment, and preserve evidence for release decisions.
Turn Evals Into Risk-Tiered Release Gates
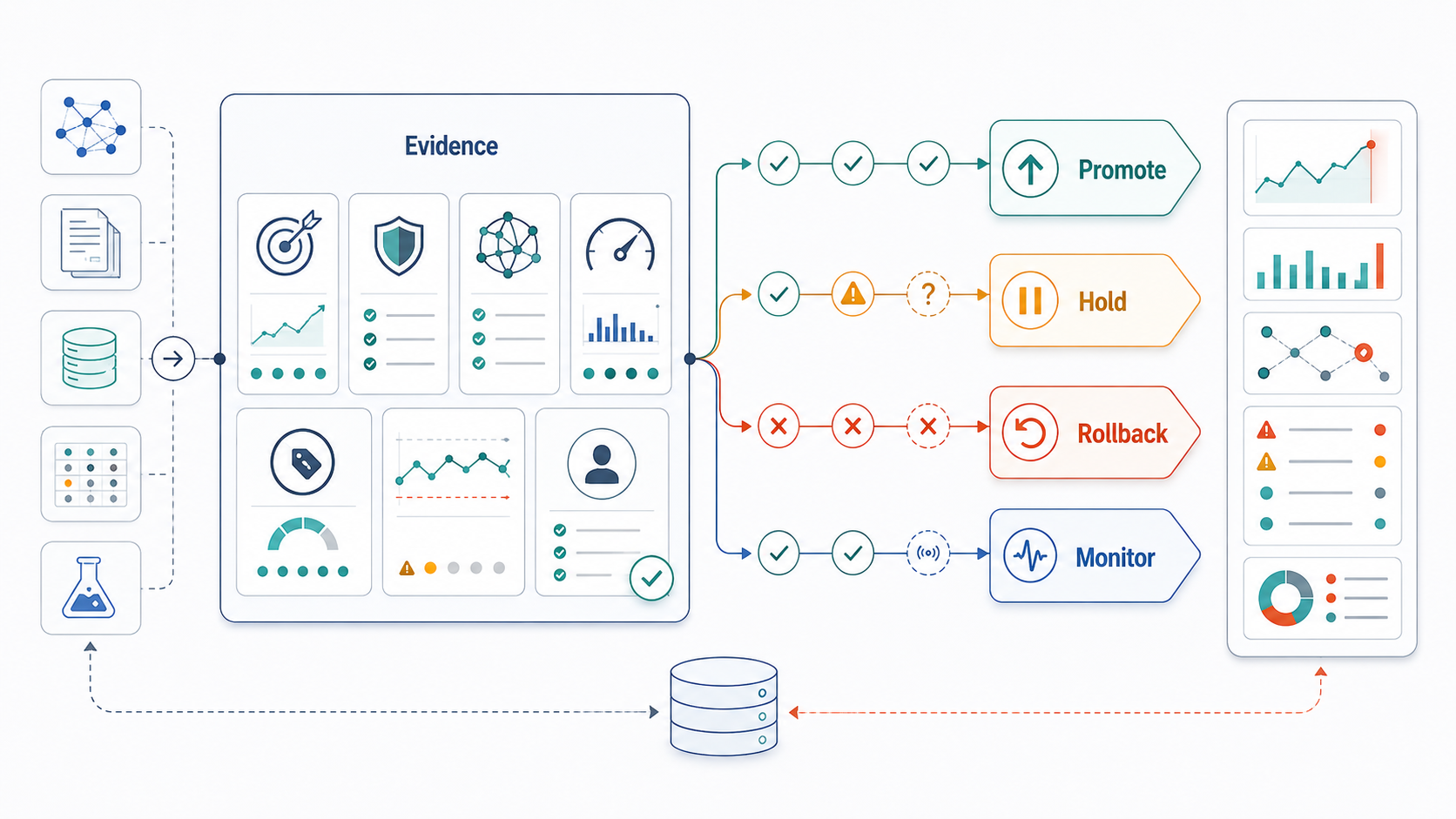
Evals are only useful if they change release behavior. A release gate turns evaluation results into decisions: promote, hold, rollback, or monitor. The thresholds should match business risk. A low-risk internal summarizer may allow limited regression with monitoring. A healthcare, finance, legal, or customer-facing agent may need stricter safety, escalation, and audit evidence before rollout.
| Risk Tier | Example Workflow | Minimum Gate |
|---|---|---|
| Low | Internal draft, summarization, or search assistant | Grounding sample, user feedback, latency and cost watch items |
| Medium | Customer-facing answer, support triage, or sales operation copilot | Scenario eval pass rate, source checks, escalation accuracy, human review sample |
| High | Regulated advice, financial action, legal workflow, or tool-using agent | Policy pass threshold, permission tests, audit logs, approval gates, rollback trigger |
This is where AI assurance and traditional release QA meet. The distinction between UAT, functional testing, and regression testing still matters, but AI adds another layer of evidence. The business validates useful outcomes, QA protects repeatable behavior, engineering owns instrumentation, and AI reviewers define rubrics for judgment-heavy tasks.
Governance, Model Lifecycle, And Production Feedback
AI assurance does not end at launch. Model vendors change behavior, private documents change, users discover new edge cases, integrations fail, and business policy evolves. The assurance strategy needs a lifecycle plan.
Use governance to answer operational questions: who can approve model, prompt, retrieval, or tool-access changes; which eval suites run before each change; which production failures become new regression cases; how user reports and incident tickets are triaged; which logs are retained or redacted; and how often permissions, datasets, prompts, and guardrails are reviewed.
NIST AI RMF is useful because it frames risk work around governance, mapping, measurement, and management. OWASP's LLM guidance is useful because it turns security concerns into application risks such as prompt injection, sensitive information disclosure, insecure output handling, supply-chain weaknesses, and excessive agency. For a broader operating model, pair this section with AI governance for critical infrastructure software.
For systems already in production, model monitoring becomes part of the assurance stack. NextPage's NLP model monitoring and MLOps services help teams track drift, quality, latency, cost, feedback, and release evidence so AI products keep improving after the first deployment.
AI Assurance Implementation Checklist
Use this checklist before you promote an AI feature from pilot to wider rollout:
| Area | Question | Artifact |
|---|---|---|
| Risk taxonomy | Have we defined the failure modes that matter for this workflow? | Failure taxonomy and risk-tier map |
| Eval data | Do eval cases cover happy paths, edge cases, adversarial prompts, and real user failures? | Versioned eval dataset |
| RAG quality | Can we measure retrieval, grounding, abstention, and source freshness separately? | RAG evaluation report |
| Release gates | Which metrics block release, which trigger review, and which are watch-only? | Gate threshold table |
| Human review | Who reviews ambiguous, high-impact, or policy-sensitive outputs? | Review workflow and rubric |
| Observability | Can we reproduce failures from traces without exposing sensitive data unnecessarily? | Trace, log, and redaction plan |
| Governance | Who approves model, prompt, retrieval, and tool-access changes? | Change-control and owner matrix |
If you cannot produce these artifacts, do not compensate with a larger demo. Narrow the first workflow, improve retrieval evidence, add human review, or run a pilot with stricter monitoring. The AI-powered QA automation roadmap is a useful companion when your team also needs to decide where AI should assist test generation and where conventional automation should stay in control.
What To Measure After Launch
Production measurement should connect quality, safety, cost, and business value. Track task success, escalation rate, unsupported-claim rate, retrieval misses, policy violations, human-review disagreement, incident volume, rollback frequency, P95 latency, cost per task, and the percentage of production failures converted into new regression cases.
Also measure whether the AI system is worth expanding. A workflow can pass evals and still fail the business case if it saves little time, creates review burden, or affects a low-value process. If scope or budget is still unclear, use the Custom Software Cost Estimator to frame the software, integration, QA, and monitoring effort behind the assurance plan.
How NextPage Helps AI Teams Ship With Evidence
NextPage helps teams turn AI prototypes into production systems with evaluation, workflow design, RAG architecture, QA automation, governance, and monitoring planned together. We can help you define a failure taxonomy, build the eval dataset, test retrieval and grounding, design release gates, and connect production incidents back into continuous improvement.
A useful first engagement is an AI assurance readiness review. Bring the workflow, current prompts, retrieval sources, model choices, known failures, user roles, compliance constraints, and launch timeline. We will map the assurance gaps and decide what needs to be automated, manually reviewed, monitored, or deferred.