
Quick Answer: What Should An AI Data Readiness Checklist Prove?
An AI data readiness checklist should prove that the data needed for RAG, agents, forecasting, or workflow automation is accessible, owned, clean, fresh, permission-aware, retrievable, testable, and connected to the business process where AI will act. If those checks are weak, model choice is premature.
This checklist is for CTOs, operations leaders, data owners, and product teams preparing fragmented business data for AI. Use the AI Agent Readiness Assessment when you need a quick first pass on workflow, data, integration, and governance readiness before committing to a build.
Why AI Projects Fail Before Model Choice
Many AI initiatives fail before the model has a chance to help. The data is scattered across SaaS tools, databases, documents, tickets, chats, spreadsheets, and legacy systems. Owners are unclear. Permissions are inconsistent. Freshness is unknown. Pipelines work for reporting but not for retrieval, agents, or real-time decisions.
The current platform guidance from Google Cloud, Microsoft Azure, and AWS keeps pointing to the same operating reality: AI data work is not only storage or model training. Teams need quality controls, governance, security, evaluation, monitoring, and production operations around the data path. The practical NextPage question is more direct: can this data safely support the AI workflow you want to ship?
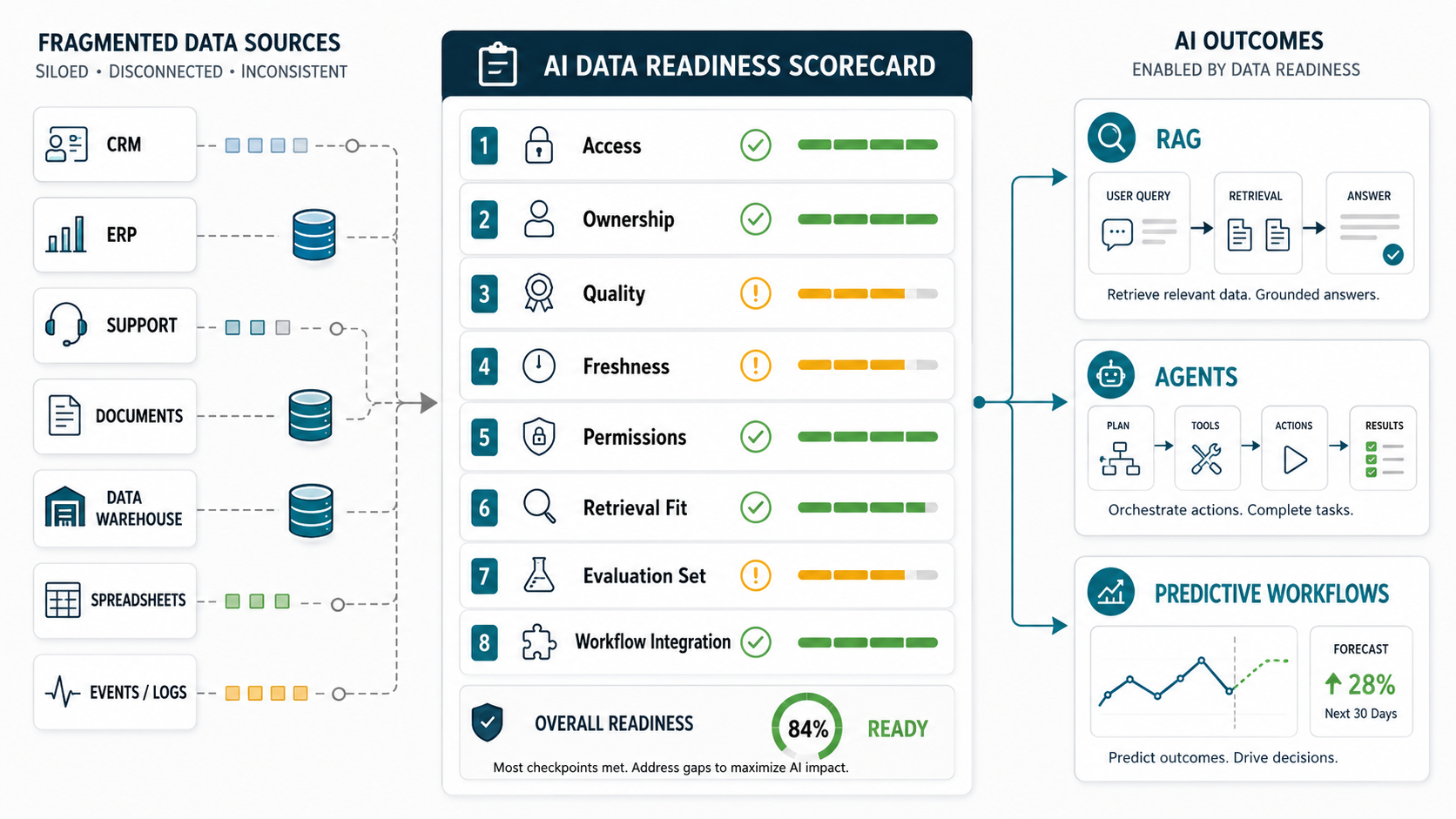
1. Score Data Readiness Before Scoping The AI Build
Use a scorecard before writing prompts, choosing vector databases, or designing agent tools. Score each area from 0 to 3: 0 means unknown, 1 means documented but weak, 2 means usable with remediation, and 3 means production-ready evidence exists.
| Readiness Area | What To Verify | Evidence |
|---|---|---|
| Access | Can systems expose the needed data through APIs, exports, streams, or governed connectors? | Source inventory, access method, environment, owner. |
| Ownership | Who approves usage, fixes quality issues, and accepts business risk? | Data owner, steward, escalation path. |
| Quality | Are records complete, deduplicated, valid, consistent, and usable? | Quality rules, defect rate, sample checks. |
| Freshness | How current must the data be for the use case? | Refresh SLA, timestamp field, stale-data behavior. |
| Permissions | Can AI respect roles, consent, retention, and sensitive data boundaries? | Policy map, masking rules, access tests. |
| Retrieval fit | Can data be chunked, indexed, searched, cited, and explained? | Chunking test, retrieval evals, source links. |
| Evaluation | Can the team test answers, predictions, or actions against known examples? | Golden set, failure cases, acceptance criteria. |
| Workflow integration | Where will AI output be reviewed, approved, acted on, and logged? | Workflow map, human review, audit log. |
2. Map Readiness By AI Use Case
Data readiness is not identical for every AI workload. RAG needs retrievable, permission-aware knowledge with citation paths. Agents need safe access to data and tools, action boundaries, approval flows, and audit logs. Predictive workflows need history, labels, leakage checks, segment coverage, drift monitoring, and business acceptance criteria.
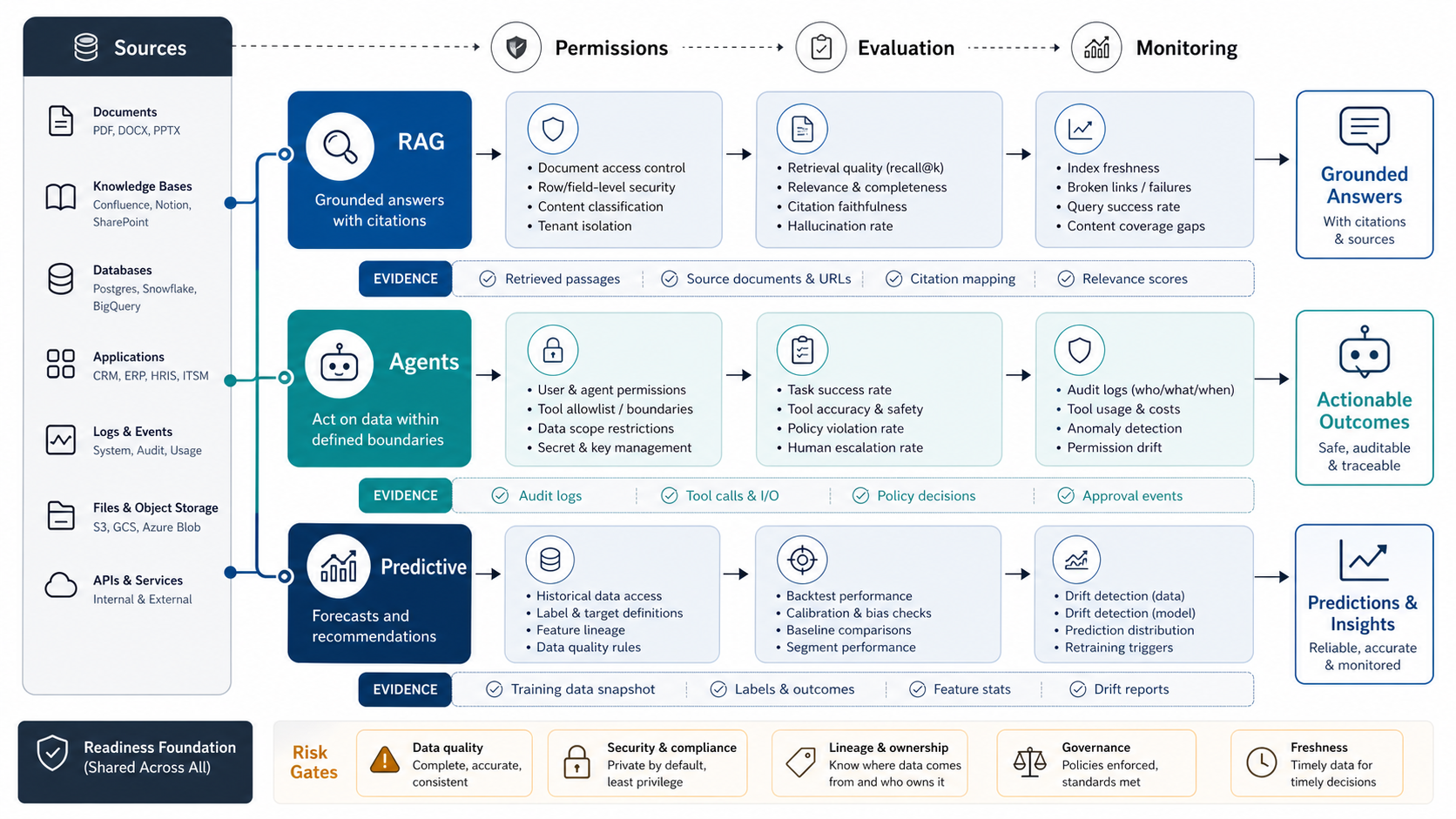
Use the same source inventory, but do not approve all three use cases from one generic data-quality score. A document repository may be ready for a narrow RAG assistant while still being unsafe for an agent that can update CRM records. A clean event table may support forecasting while being useless for policy citation. This is why readiness should be scored by use case, not only by data platform.
3. RAG Data Readiness Is About Retrieval, Not Just Storage
RAG systems need more than a document dump. They need source clarity, chunking strategy, metadata, permissions, version handling, citation paths, and retrieval evaluation. If users ask policy, product, legal, support, or operational questions, the system must retrieve the right context and show where it came from.
For production knowledge workflows, enterprise RAG implementation services should start with source-system inventory and retrieval tests. The knowledge representation for RAG systems guide goes deeper on ontologies, graphs, and preparation choices when simple chunks are not enough. If the buyer is still deciding the AI pattern, compare the tradeoffs in Prompt Engineering Vs RAG Vs Fine-Tuning before committing to the data architecture.
4. Agent Data Readiness Requires Permissions And Action Boundaries
Agents can do more than answer. They can draft, update records, trigger workflows, route tickets, call APIs, or recommend actions. That makes permission and workflow readiness more important than in a passive chatbot.
Before building an agent, map what data it can read, what tools it can call, what actions require approval, what logs are retained, and how failed actions are reversed. The enterprise AI readiness checklist is useful when the blocker is broader than data: workflow clarity, governance, security, and human review must also be ready. For teams moving from assessment into build planning, AI agent development should be scoped around permissions, tool contracts, test cases, and fallback paths before autonomy is expanded.
5. Predictive Workflow Readiness Depends On History And Labels
Forecasting, scoring, churn prediction, anomaly detection, recommendations, and prioritization workflows need historical data that matches the decision being predicted. A clean table is not enough. The team needs event history, labels or outcome fields, time windows, leakage checks, segment coverage, and monitoring signals.
When the use case depends on model training or statistical validation, machine learning development services should review data volume, label quality, feature availability, drift risk, and business acceptance criteria before promising ROI. For forecasting, ranking, or operational scoring, predictive analytics services should also define how predictions will be monitored after launch.
6. Governance Must Be Built Into The Data Path
AI-ready data needs governance at the point of use, not only in a policy document. That means classification, retention rules, consent, PII masking, role-based access, tenant separation, audit logs, and incident response. For RAG and agents, permissions must be enforced during retrieval and tool use, not only during ingestion.
| Risk | Readiness Check | Failure Mode |
|---|---|---|
| PII exposure | Mask or restrict sensitive fields before retrieval or prompt assembly. | Private data appears in AI answers. |
| Wrong user access | Apply user and role permissions at answer time. | Users see records they should not access. |
| Stale policies | Track source version, effective date, and freshness SLA. | AI cites outdated rules or prices. |
| No audit trail | Log source IDs, prompts, retrieved chunks, tool calls, and approvals. | Teams cannot explain or debug AI behavior. |
7. Turn The Scorecard Into A Remediation Plan
Do not treat a low score as a failed AI idea. Treat it as a scope signal. Some teams should pause model work and fix data ownership. Some should run a narrow proof of concept with a limited source set. Some can ship a supervised workflow while improving automation later.
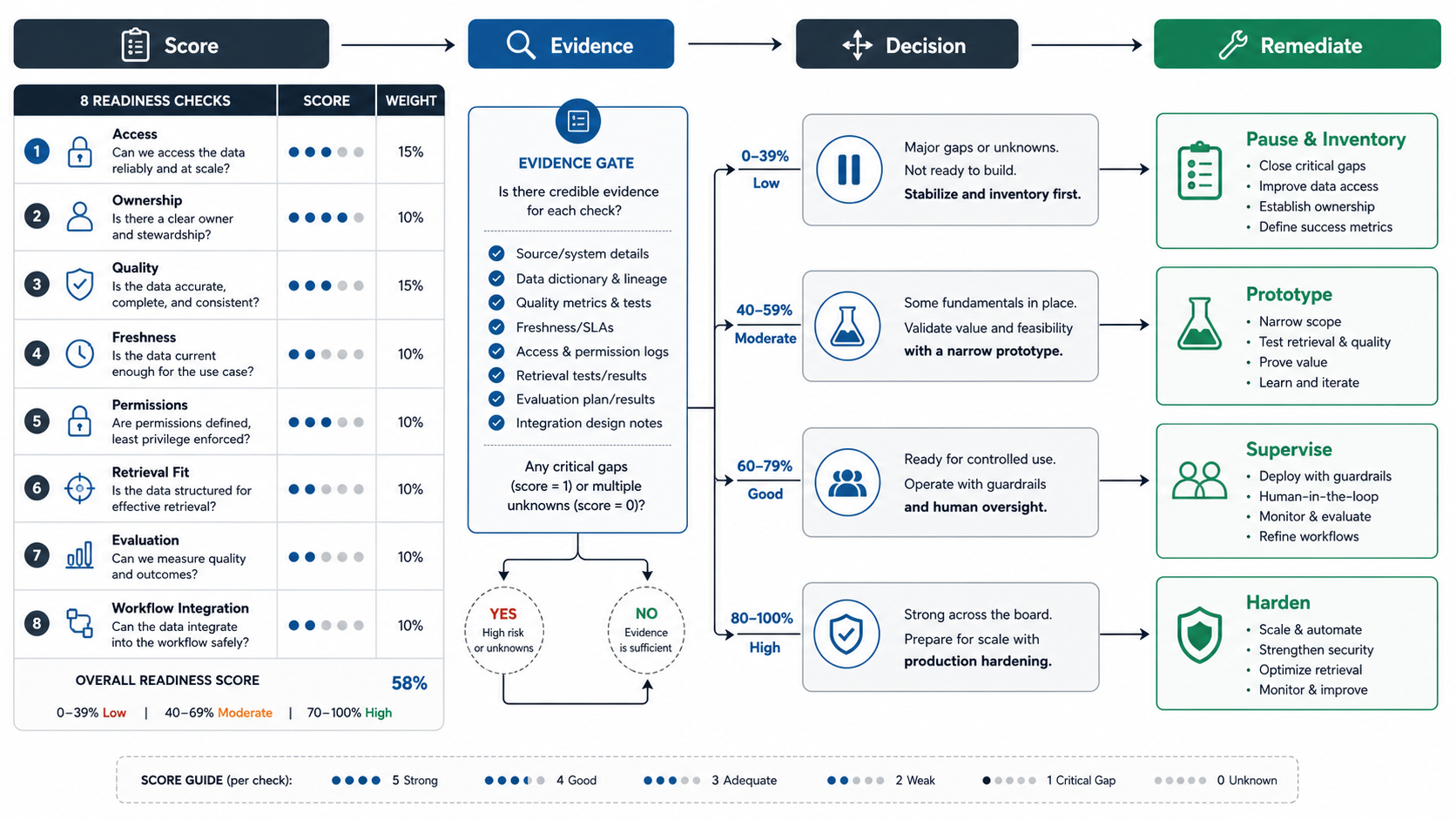
- Score 0-8: pause the AI build; inventory systems, owners, permissions, and quality issues first.
- Score 9-16: run a narrow prototype with limited data and explicit caveats.
- Score 17-22: build a supervised workflow with evaluation and human review.
- Score 23-24: plan production hardening, monitoring, permissions, and rollout.
If you are selecting a partner, use these questions alongside how to choose an AI development company. A credible AI partner should raise data readiness early, not after the build budget is approved.
8. Build The Evidence Pack Before AI Delivery
The best readiness review ends with artifacts the delivery team can actually use. Create a source-system inventory, data dictionary, access and permission map, quality report, freshness SLA, representative sample set, evaluation set, workflow diagram, risk register, and acceptance criteria. These artifacts make scope clearer and reduce the chance that implementation teams discover basic blockers after the AI budget is already committed.
For larger estates, pair AI readiness with a data migration checklist when source-of-truth cleanup, deduplication, field mapping, or system consolidation is part of the remediation plan. For release discipline after the data foundation is ready, the LLMOps Vs MLOps Release Playbook helps teams define evaluation, monitoring, rollback, and operating ownership.
NextPage's AI Data Readiness Checklist
- List source systems, owners, access paths, environments, and refresh patterns.
- Document data definitions, lineage, and business meaning before indexing or training.
- Measure completeness, duplicates, consistency, outliers, and known defects.
- Classify sensitive data and enforce permissions during retrieval and tool use.
- Test retrieval with real questions, citations, expected answers, and failure cases.
- Prepare evaluation sets for RAG answers, agent actions, or predictive outputs.
- Map human review, approval, rollback, and audit logging into the workflow.
- Choose pause, prototype, supervised rollout, or production hardening based on score.
How NextPage Can Help
NextPage helps teams turn AI interest into a buildable plan by scoring workflow, data, integration, and governance readiness before implementation. Start with the AI Agent Readiness Assessment, then move into RAG, agent, LLM, or ML implementation once the data foundation can support the use case.
If the roadmap needs business proof before sponsorship, review the NextPage portfolio for shipped systems that connect data, workflows, dashboards, integrations, and operational decision-making. The right next step is not always a model build. It is the smallest data-backed workflow that can be measured, governed, and improved.