
Quick Answer: What Should A Big Data Analytics Consulting Checklist Include?
A big data analytics consulting checklist should prove six things before the build starts: the business questions are worth answering, the source systems can support those questions, the pipeline architecture can be trusted, governance is practical enough for daily use, dashboards will change decisions, and AI use cases have enough data readiness to move beyond a demo. The checklist should end with partner deliverables, acceptance evidence, timeline assumptions, cost drivers, and an ownership handoff.
The strongest consulting engagement is not a dashboard build or a data-platform shopping exercise. It is a controlled path from scattered operational data to trusted decisions, forecastable workflows, and AI-ready data products. That means a consultant should inspect source systems, reconcile definitions, expose data quality risks, define semantic-layer ownership, and show how each dashboard or model will change a real workflow.
Use the checklist below before shortlisting analytics partners, approving a warehouse or lakehouse budget, or promising AI outcomes to leadership. It turns the conversation from tool selection into evidence: what data exists, who owns it, how it moves, how quality is measured, and what business decisions it will improve.
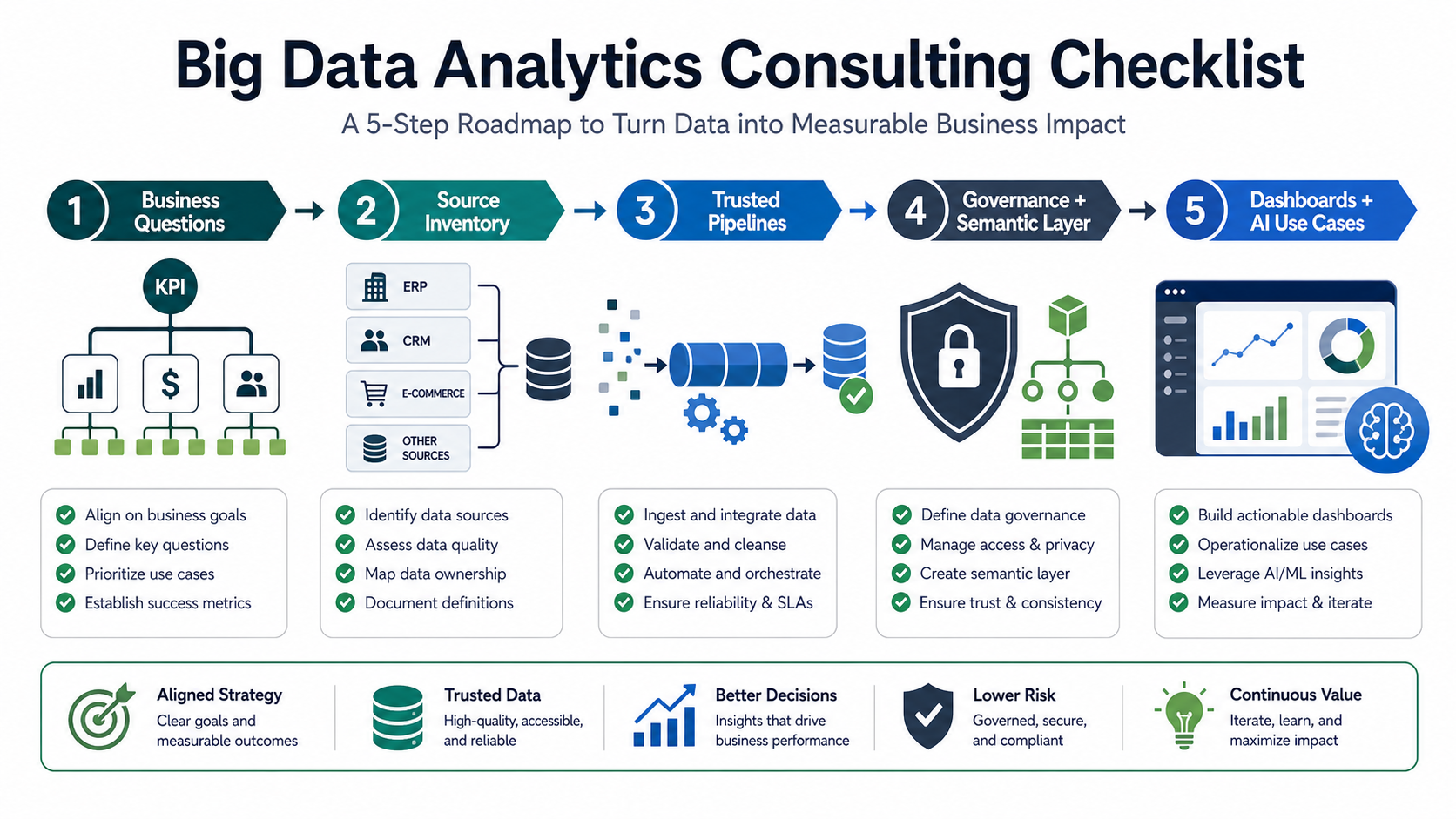
The Big Data Analytics Consulting Checklist
Start with a one-page consulting brief, then ask every vendor to respond with evidence rather than broad claims. A useful response should show how the team will validate data, design pipelines, govern definitions, deliver dashboards, prioritize AI, and transfer ownership after launch.
| Checklist area | Questions to answer | Evidence to request |
|---|---|---|
| Business outcomes | Which decisions, forecasts, workflows, or operating metrics need improvement? | KPI tree, stakeholder map, baseline reports, target decisions, value hypothesis. |
| Source systems | Which systems hold the required data, and which source is authoritative? | Source inventory, owner list, field dictionary, access constraints, sample extracts. |
| Data pipelines | How will data be ingested, transformed, validated, reconciled, and monitored? | Architecture diagram, data contracts, lineage, run logs, failure handling, quality tests. |
| Governance | Who approves definitions, access, retention, privacy rules, and data-product changes? | Ownership model, access matrix, audit trail, glossary, change workflow. |
| Dashboards | Which metrics must be self-serve, operational, executive, embedded, or alert-driven? | Dashboard wireframes, semantic layer, refresh SLAs, adoption plan, usage metrics. |
| AI readiness | Which predictive, generative, or agentic use cases have clean inputs and measurable value? | Use-case scorecard, training/evaluation data review, MLOps plan, risk controls. |
| Delivery model | What will the consultant deliver, transfer, document, and support? | Milestone plan, acceptance criteria, runbooks, documentation, support model. |
1. Start With Business Questions, Not A Data Tool
The first consulting conversation should not be about Spark, Snowflake, BigQuery, Databricks, Power BI, Looker, or a preferred cloud. It should be about the decisions the business cannot make confidently today. Examples include which customer segments are profitable, which inventory policies reduce stockouts, which claims need fraud review, which sales territories need intervention, which assets will fail, and which marketing channels create retained revenue.
Translate each decision into a KPI tree. A retail analytics program might start with revenue, margin, conversion, returns, inventory availability, basket size, and delivery promise accuracy. A SaaS program might prioritize activation, feature adoption, churn risk, expansion signals, support load, and sales pipeline quality. A manufacturing program may need downtime, yield, scrap, maintenance, energy usage, and supplier variability.
This step prevents dashboard sprawl. A consultant should ask who owns each KPI, where the data comes from, how often it needs to refresh, what action changes when it moves, and what level of confidence is required. AWS analytics workload guidance starts with workload context such as business purpose, KPIs, intended users, owners, stakeholders, and compliance requirements. That context should exist before architecture decisions are made.
2. Inventory Source Systems And Ownership
Big data analytics does not mean every dataset is useful. Start with the systems that create operational truth: ERP, CRM, ecommerce platforms, POS, warehouse systems, financial systems, product telemetry, web analytics, support tools, marketing automation, IoT streams, claims systems, spreadsheets, and third-party feeds. Then identify the owner, refresh frequency, data format, access path, retention rules, and known quality issues for each source.
The hard questions are usually about ownership. Which customer ID wins when CRM and billing disagree? Which revenue number should executives trust? Who approves a change to the definition of active user? Which product hierarchy is used by finance versus merchandising? Which source has consent and privacy restrictions? These answers determine whether analytics can scale beyond a one-off dashboard.
If the project will feed ML models or AI agents, compare the source inventory with NextPage's machine learning consulting company checklist. The same data-readiness questions apply before predictive analytics, recommendation systems, anomaly detection, or AI workflow automation can be trusted.
3. Design Pipeline Architecture Around Trust Gates
A good analytics pipeline is boring in the right ways: observable, versioned, recoverable, documented, and easy to reason about when something breaks. The architecture should cover batch ingestion, streaming ingestion when required, raw storage, transformations, warehouse or lakehouse modeling, orchestration, data quality checks, lineage, access control, and downstream consumption through dashboards, APIs, exports, or AI features.
Ask the consulting partner to show how the pipeline handles late-arriving data, schema drift, duplicate records, source outages, partial loads, backfills, personally identifiable information, and failed transformations. A beautiful diagram is not enough. You need run logs, alert rules, ownership, retry behavior, reconciliation totals, and a way for business users to know whether a metric is fresh and reliable.
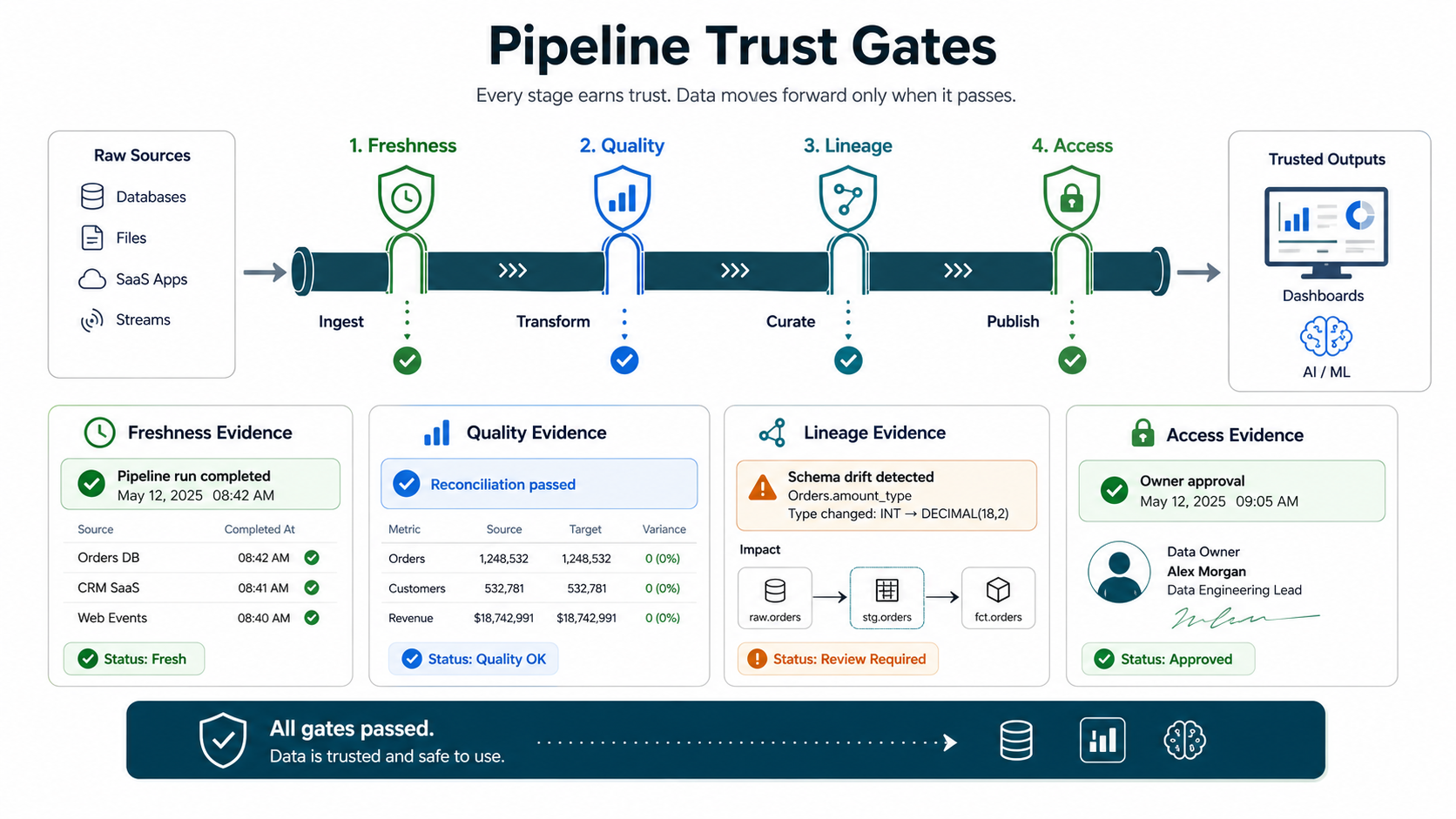
| Pipeline layer | Consulting decision | Acceptance evidence |
|---|---|---|
| Ingestion | Batch, streaming, CDC, API pull, file drop, event bus, or hybrid. | Connector inventory, sample payloads, run schedule, failure behavior. |
| Storage | Warehouse, lakehouse, object storage, time-series store, or domain-specific mix. | Data model, retention policy, partitioning strategy, cost estimate. |
| Transformation | ELT, ETL, dbt-style modeling, Spark jobs, managed dataflow, or custom services. | Versioned transformations, tests, lineage, code review process. |
| Quality | Required checks for completeness, uniqueness, validity, freshness, and reconciliation. | Quality dashboard, thresholds, alerts, exception owner. |
| Operations | Monitoring, alerting, incident response, backfills, and deployment workflow. | Runbook, SLA/SLO definitions, support rota, post-incident review process. |
For custom ingestion services, admin workflows, embedded analytics, or integration-heavy programs, pressure-test the scope with the Custom Software Cost Estimator before committing to a timeline.
4. Make Governance Practical Enough To Use
Governance is not a policy PDF that nobody reads. In analytics consulting, governance should show up in daily delivery: a glossary, data owners, approval workflows, access groups, masking rules, lineage, retention policy, audit trails, and a change process for metric definitions. Microsoft published updated unified data platform guidance in March 2026 that keeps the same practical theme: analytics and AI need trusted, governed, reusable data products rather than isolated reporting assets.
Start with a small set of high-value data products. A data product can be a curated customer table, a revenue model, an operations dataset, a feature set for ML, or an executive KPI layer. Each product needs an owner, consumers, data quality expectations, access rules, refresh schedule, and lifecycle plan. This makes governance concrete and keeps teams from arguing endlessly about abstract enterprise data strategy.
Security and privacy reviews belong here too. Confirm how the project will handle sensitive customer data, health or financial data, employee information, location data, consent, cross-border transfer, retention, deletion requests, audit evidence, and privileged access. For AI use cases, align risk review with NIST AI RMF's govern, map, measure, and manage functions so model behavior, data access, evaluation, and incident response are not treated as afterthoughts.
5. Scope Dashboards Around Decisions And The Semantic Layer
Dashboards are useful when they reduce decision latency. They fail when every stakeholder asks for a custom view built on inconsistent definitions. A consulting partner should help define which dashboards are executive, operational, exploratory, customer-facing, or embedded inside a workflow. Each dashboard needs a user, decision, metric owner, refresh need, drill path, and action threshold.
The semantic layer is where many analytics programs either scale or fracture. If revenue, customer, product, region, margin, retention, and conversion are defined separately in every dashboard, the organization will keep debating numbers instead of acting. The consulting checklist should require shared definitions, approved calculations, row-level access rules, and tests that catch metric changes before they reach leadership.
If stakeholders are debating Power BI, embedded analytics, or a bespoke reporting portal, use the Power BI vs custom dashboard app decision guide alongside the operational dashboard requirements checklist. For teams that need role-aware dashboards connected to workflows, alerts, exports, and source-system QA, NextPage's custom dashboard development services page maps the commercial delivery path.
Useful dashboard scoping questions include:
- Which metric changes should trigger action, and who owns that action?
- Which dimensions must be trusted across teams: customer, product, region, channel, cohort, facility, or account?
- Which reports are board-level, which are operational, and which can remain exploratory?
- What is the acceptable data freshness for each dashboard?
- Which metrics need drill-through to transactions, tickets, orders, claims, events, or source records?
6. Prioritize AI Use Cases Only After Data Readiness
Big data analytics consulting often expands into AI. That can be valuable, but the order matters. A forecasting model, recommendation engine, anomaly detector, churn model, document assistant, or operations agent needs trustworthy data, measurable business value, and a safe operating model. If those are missing, the AI pilot becomes a demo rather than a production capability.
Use a scorecard that ranks each AI use case by value, data availability, label quality, risk, integration complexity, evaluation method, and operating owner. A high-value use case with weak data should become a data-preparation workstream before it becomes a model build. A low-risk use case with clear workflow ownership can become a first pilot if the success metric is measurable.
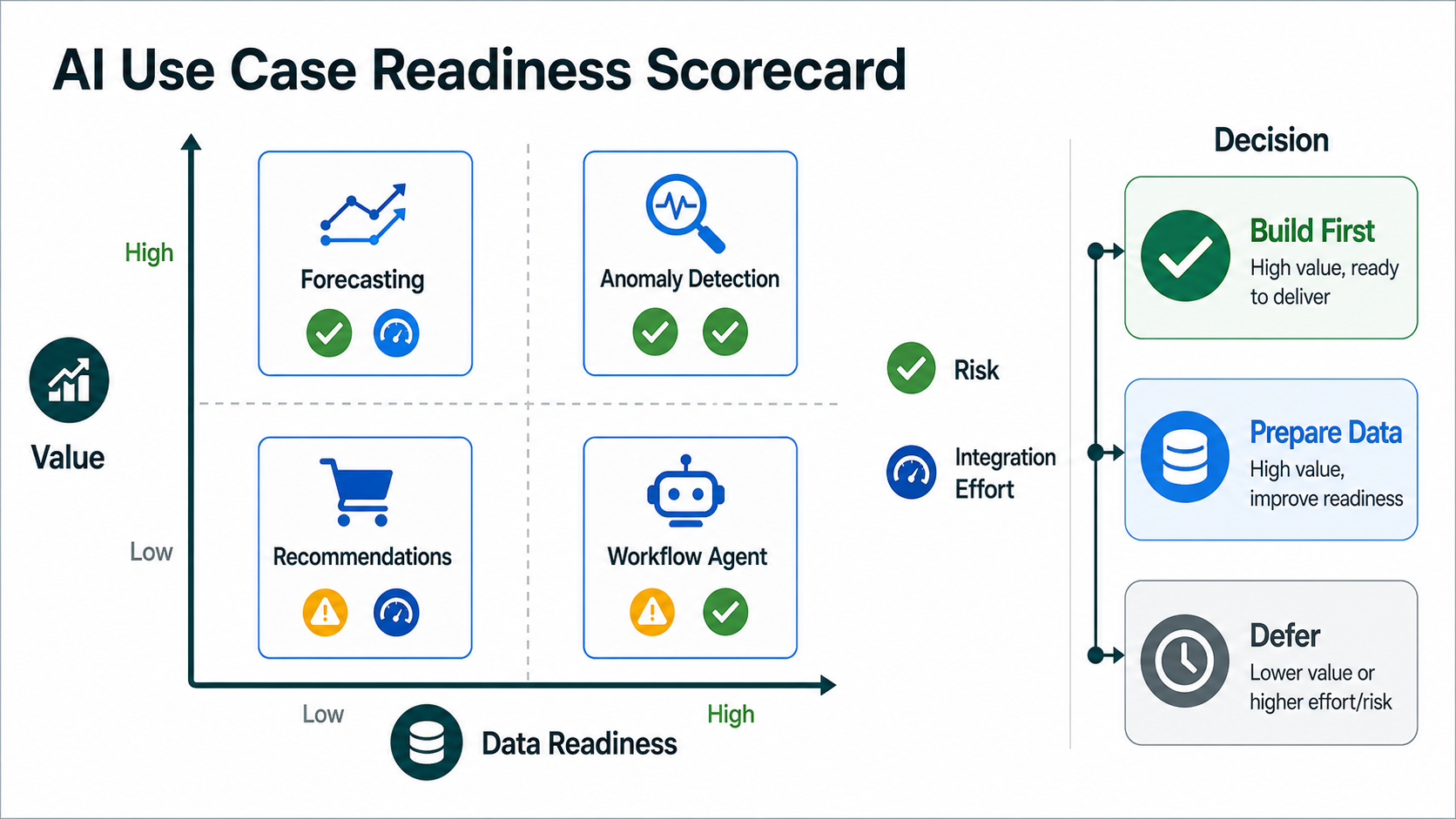
For forecasting, scoring, anomaly detection, and decision-support workflows, compare the consulting plan with NextPage's predictive analytics services model. For production ML systems that need APIs, monitoring, retraining, and model-risk controls, review machine learning development services. For agentic workflows, the AI Agent Readiness Assessment is a useful gate because it forces teams to score workflow clarity, data readiness, integration access, and human-review controls before granting tool access.
| AI use case | Data requirement | Risk to check |
|---|---|---|
| Forecasting | Historical time series, drivers, calendar effects, promotions, external context. | Changing demand patterns, sparse history, no owner for forecast action. |
| Anomaly detection | Clean event streams, baseline behavior, known incidents, alert feedback. | Alert fatigue, missing ground truth, unclear escalation process. |
| Recommendations | Behavior, catalog, transaction history, constraints, outcomes. | Cold start, bias toward popular items, poor explainability. |
| Document or support assistant | Governed knowledge base, access rules, evaluation set, human escalation. | Stale content, over-permissioned retrieval, hallucinated answers. |
| Workflow agent | Task history, tool permissions, process rules, logs, approval boundaries. | Unsafe actions, weak auditability, unclear rollback. |
7. Evaluate The Consulting Partner By Deliverables, Not Claims
Vendor pages often list expertise, technology stack, compliance, reviews, flexibility, and support. Those are useful starting points, but a serious buyer should ask for deliverables and acceptance evidence. The right partner can explain how it discovers data issues, designs pipeline contracts, manages quality, validates dashboards, transfers ownership, and supports production after launch.
Ask these questions before signing:
- What does the discovery phase produce beyond a slide deck?
- How do you document source ownership, data contracts, lineage, and quality checks?
- Which parts of the stack are managed services, which are custom code, and why?
- How do you prevent metric-definition drift across dashboards?
- How do you test data pipelines before business users depend on them?
- What happens when a source schema changes or a pipeline fails after launch?
- What documentation, training, and runbooks does the internal team receive?
- How do you decide whether an AI use case is ready for production?
If the engagement includes predictive analytics, model deployment, or production AI, your partner should also cover MLOps, monitoring, feedback loops, and model-risk review. That is where analytics consulting overlaps with AI development services and production machine learning delivery.
Timeline And Cost Drivers To Discuss Early
Big data analytics consulting cost depends on scope, not only data volume. The largest drivers are source-system access, data quality, number of domains, integration complexity, compliance requirements, dashboard count, real-time needs, AI model complexity, cloud architecture, migration from legacy reports, and the amount of change management required for adoption.
A practical first phase is usually a readiness and roadmap sprint: source inventory, stakeholder interviews, KPI tree, data-quality sampling, architecture options, governance model, dashboard backlog, AI use-case scorecard, and delivery plan. That phase can prevent months of wasted build effort by proving which outcomes are realistic and which dependencies must be fixed first.
Implementation can then proceed in thin vertical slices. For example: ingest CRM and billing data, create a governed revenue data product, launch one executive dashboard, add quality monitoring, then expand into churn prediction. Each slice should produce a working asset, not just a future-state architecture.
Next Steps
If your team is evaluating big data analytics consulting, start by writing down the business questions you cannot answer today. Then map the source systems, owners, data quality risks, dashboard users, and AI ideas attached to those questions. The result is a consulting brief that can be estimated, challenged, and implemented.
NextPage can help with a data readiness and analytics roadmap review, then move into pipeline architecture, dashboard engineering, machine learning workflows, and custom software integrations where needed. The goal is not to add another reporting tool. It is to build a trusted data foundation that improves decisions and makes AI use cases realistic.