
Quick Answer: How To Move A GenAI POC To Production
A GenAI POC moves to production only when the team can prove four things: the workflow is worth automating, the data and retrieval layer are trustworthy, the system can be evaluated against realistic failures, and the operating model can control cost, security, human review, and monitoring after launch. A demo that answers a few prompts is not production evidence.
Most stalled pilots fail because the POC optimizes for excitement while production requires repeatability. The gap is usually not one missing model. It is unclear business ownership, weak source data, no golden evaluation set, missing integration paths, unpriced usage, and no accountable support process.
For teams trying to turn a pilot into a working product, NextPage's generative AI development work starts with a readiness gate: define the business workflow, map the data, test the failure modes, design human review, estimate cost per task, and ship through a staged rollout.
Why GenAI Pilots Fail After The Demo Works
A GenAI pilot can feel successful even when it is not close to production. The demo might summarize documents, answer policy questions, draft support replies, or generate SQL from a clean sample. Production adds messy inputs, permission boundaries, stale knowledge, latency targets, customer impact, audit needs, model updates, and real users who do not behave like the pilot team.
The Talentica source frames common GenAI POC to production challenges around data, evaluation, cost, integration, and adoption. That framing is directionally right. The missing buyer question is sharper: what evidence must exist before the pilot deserves production traffic?
| POC signal | Why it is not enough | Production evidence needed |
|---|---|---|
| Good answers on sample prompts | Samples rarely cover edge cases, unsafe inputs, stale documents, or adversarial phrasing. | Golden dataset, edge-case suite, regression tests, reviewer acceptance threshold. |
| Strong executive demo | Demos hide integration, permissions, latency, and support work. | System architecture, API contracts, access model, fallback path, owner map. |
| High user excitement | Adoption can drop when users must verify every answer manually. | Human-review workflow, confidence display, source citations, escalation rules. |
| Low pilot cost | Production traffic changes token, retrieval, storage, review, and observability costs. | Unit economics by task, usage caps, rate limits, cost alerts, budget owner. |
| One team can run it manually | Production needs repeatable deployment, support, monitoring, and rollback. | Runbook, release process, monitoring dashboard, incident path, rollback trigger. |
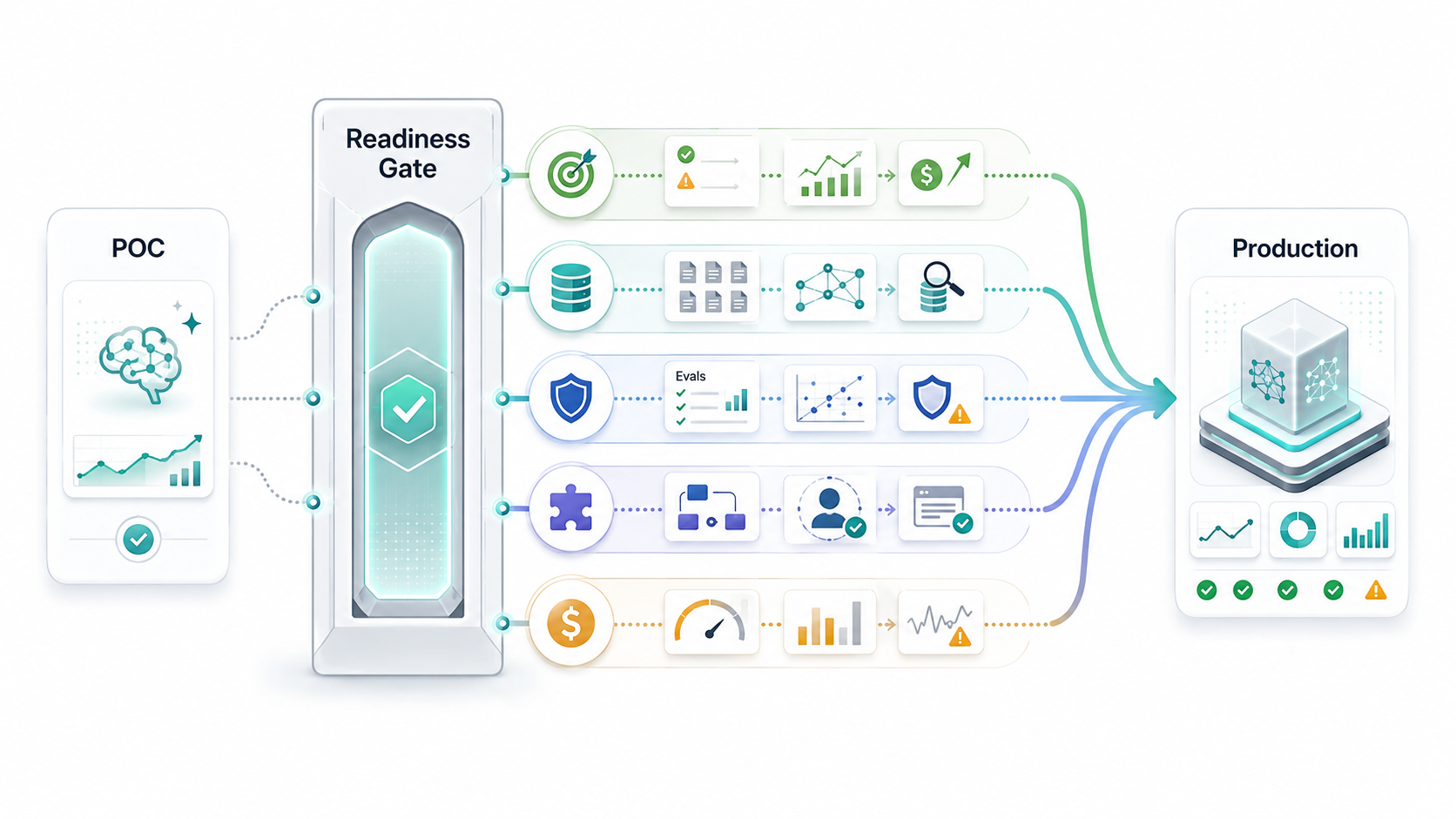
The GenAI Production Readiness Gate
The cleanest way to avoid pilot drift is to put every GenAI initiative through a readiness gate before a production build. The gate should not be heavy for every use case. A low-risk internal summarizer does not need the same evidence as a regulated claims assistant or revenue-impacting sales agent. But every production candidate needs enough evidence for its risk tier.
Start with the AI Agent Readiness Assessment when the workflow involves tools, actions, approvals, or multi-step autonomy. Even if the first release is a RAG assistant instead of an agent, the same readiness areas apply: workflow clarity, data quality, integration access, and human-review controls.
| Gate | Decision question | Artifact |
|---|---|---|
| Business fit | Is this workflow valuable enough to operationalize? | Use-case brief, baseline metric, expected ROI, accountable owner. |
| Data and retrieval | Can the system access the right context safely? | Source inventory, permissions, freshness rules, chunking/retrieval test. |
| Evaluation | Can quality be measured before and after release? | Golden set, failure taxonomy, acceptance threshold, regression suite. |
| Controls | Can the workflow prevent or contain bad output? | Guardrails, human review, audit logs, escalation, policy checks. |
| Operations | Can the team run it without surprise cost or downtime? | Cost model, monitoring, fallback, support runbook, rollback plan. |
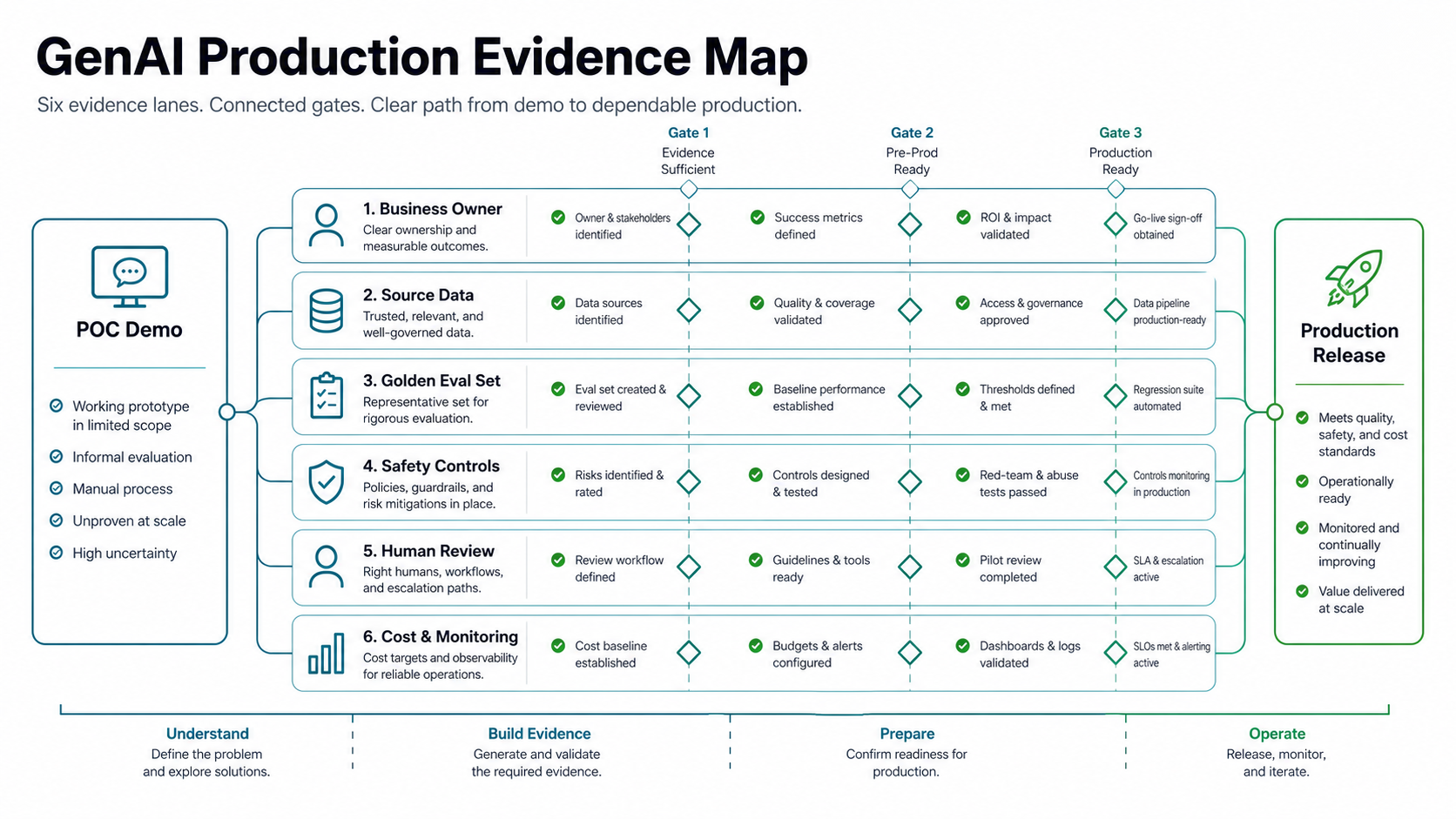
The readiness gate should produce evidence, not just opinions. Assign one owner for each artifact, define an acceptance threshold, and decide what happens when the pilot misses the threshold. For higher-risk workflows, connect this gate to an enterprise AI readiness checklist so data governance, legal review, security, and operating support are not left until the final release meeting.
Data Readiness Is Usually The First Hard Stop
GenAI pilots often use hand-picked PDFs, clean wiki pages, or manually exported spreadsheets. Production systems need current sources, permission-aware retrieval, deduplication, metadata, tenancy rules, and a way to remove stale or revoked information. If the workflow depends on customer records, policy documents, contracts, code, tickets, or regulated data, data readiness becomes a product requirement.
Before choosing a model or vector database, answer these questions:
- Source ownership: who owns each source system and who can approve AI use?
- Permissions: can retrieval respect user role, tenant, region, and document-level access?
- Freshness: how quickly do updates, deletions, and policy changes reach the AI workflow?
- Grounding: can answers cite the exact source that supports the recommendation?
- Feedback: can reviewers label wrong, incomplete, unsafe, or outdated outputs?
For many teams, a production RAG or LLM workflow sits between data engineering and product delivery. NextPage's AI development services combine workflow design, data access, LLM integration, evaluation, and deployment instead of treating the model as a standalone experiment.
Build The Evaluation Plan Before The Production Build
A GenAI system without evaluation is a subjective demo. Evaluation turns production readiness into an engineering conversation. The evaluation plan should test the business workflow, not just the model's general language ability. The owner should be able to point to the golden set, the review rubric, the failure taxonomy, and the threshold that decides whether the release moves forward.
Use a layered evaluation set:
- Happy-path tasks: common cases the system must handle quickly and accurately.
- Edge cases: ambiguous requests, incomplete inputs, conflicting sources, stale policies, and unusual formats.
- Safety cases: prompt injection, sensitive-data exposure, policy bypasses, unsupported advice, and unsafe actions.
- Operational cases: vendor timeout, retrieval failure, high-cost loop, rate limit, and fallback behavior.
- Human-review cases: examples where a reviewer must approve, edit, reject, or escalate output.
The AI development lifecycle is a useful companion here because it turns evaluation, governance, release, monitoring, and improvement into repeatable gates. For GenAI, the important point is to keep the eval set alive after launch. Every production failure should become either a regression test, a data fix, a prompt change, or a workflow decision.
Integration And Human Review Decide Real Adoption
A GenAI pilot often lives in a sandbox chat UI. Production users usually need the assistant inside a CRM, ERP, support desk, document system, analytics workflow, or internal web app. If the AI output requires copy-paste, manual verification, and separate approvals, adoption will stall even when the answers are good.
Design the workflow around user decisions:
| Workflow moment | Production design choice | Why it matters |
|---|---|---|
| Input | Pre-fill context from approved systems where possible. | Reduces prompt variation and missing information. |
| Output | Show sources, confidence cues, and editable structured fields. | Makes review faster and more accountable. |
| Approval | Route high-risk outputs to named human reviewers. | Prevents unsafe automation of judgment-heavy work. |
| Action | Separate draft, recommend, and execute permissions. | Keeps agentic behavior inside controlled boundaries. |
| Learning | Capture edits, rejections, and escalation reasons. | Turns production use into better evals and roadmap decisions. |
Do not add autonomy before the workflow is measurable. A summarizer, drafting assistant, RAG copilot, tool-using agent, and multi-agent workflow carry different risk. NextPage's guide to Generative AI vs AI Agents vs Agentic AI can help teams choose the right level of autonomy for the first production release.
Cost, Monitoring, And Support Must Be Designed Early
Production GenAI cost is not only model tokens. It can include embeddings, vector storage, document parsing, reranking, tool calls, observability, human review, security testing, and incident support. A POC may hide these costs because usage is small and the team manually handles failures.
Before launch, define:
- Expected cost per task, user, document, or transaction.
- Traffic assumptions for normal, peak, and abuse scenarios.
- Budget owner, alerts, quotas, and shutdown thresholds.
- Fallback behavior when a model, vector store, or source system fails.
- Monitoring for latency, errors, grounding failures, review outcomes, and business KPIs.
The budgeting work should happen before scale decisions. NextPage's generative AI development cost guide is useful for estimating how architecture choices, integrations, evaluation, and governance change the real cost of production GenAI.
A Safe GenAI Production Rollout Plan
Move from POC to production in stages. The goal is not to remove risk completely. The goal is to expose risk in controlled increments while collecting evidence.
| Stage | Scope | Exit criteria |
|---|---|---|
| Readiness review | Workflow, data, risk, integration, evaluation, cost. | Named owner, approved sources, release hypothesis, risk tier. |
| Controlled beta | Small user cohort and limited tasks. | Reviewer acceptance, source accuracy, latency, cost, and support data meet thresholds. |
| Production pilot | Real workflow with guardrails and fallback. | Business metric improves without unacceptable risk or support burden. |
| Scaled rollout | More users, systems, and use cases. | Monitoring, governance, support, and release process are stable. |
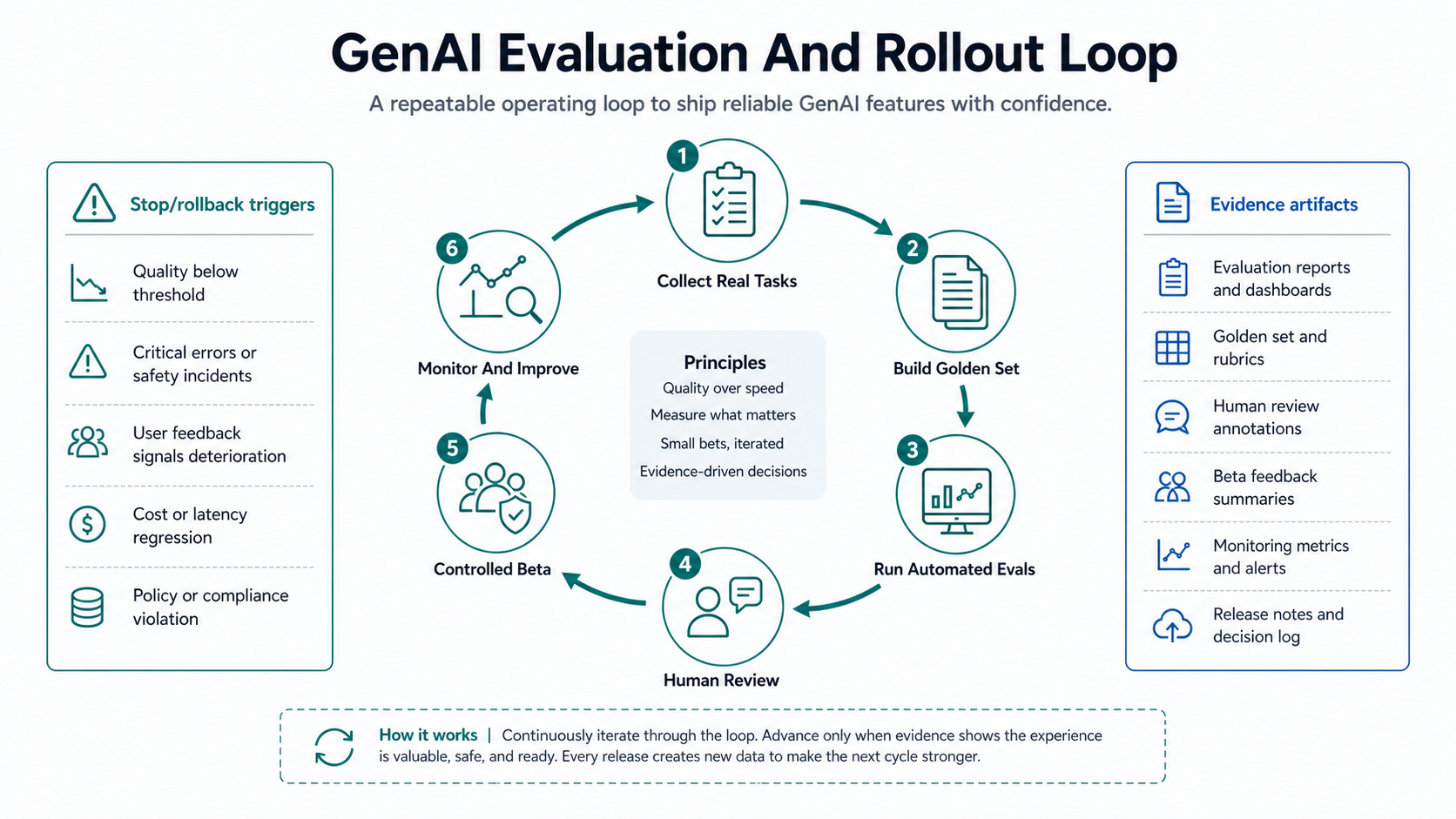
Teams should also be willing to stop. Some GenAI pilots should become workflow automation, search improvements, better dashboards, or a smaller assistant instead of a full production AI product. The strongest production teams prune weak AI ideas as rigorously as they scale promising ones.
Define stop and rollback triggers before launch: unsupported answer rate, reviewer rejection rate, hallucinated citations, sensitive-data exposure, latency breach, cost spike, workflow abandonment, or repeated support escalation. When a trigger fires, the team should know whether to disable the feature, route all output to review, narrow the use case, refresh the data, update the eval set, or revert the model/prompt release.
Next Steps
If your GenAI POC is stuck, do not start by changing models. Start by asking what evidence is missing: business owner, data approval, evaluation set, integration path, human review, cost model, or monitoring. Once those gaps are visible, the production plan becomes concrete.
NextPage can help assess the gap and build the production path through Generative AI Development, AI Development Services, and readiness planning for RAG, copilots, AI agents, and workflow automation. The goal is not a better demo. It is a GenAI workflow your team can operate, measure, improve, and trust.