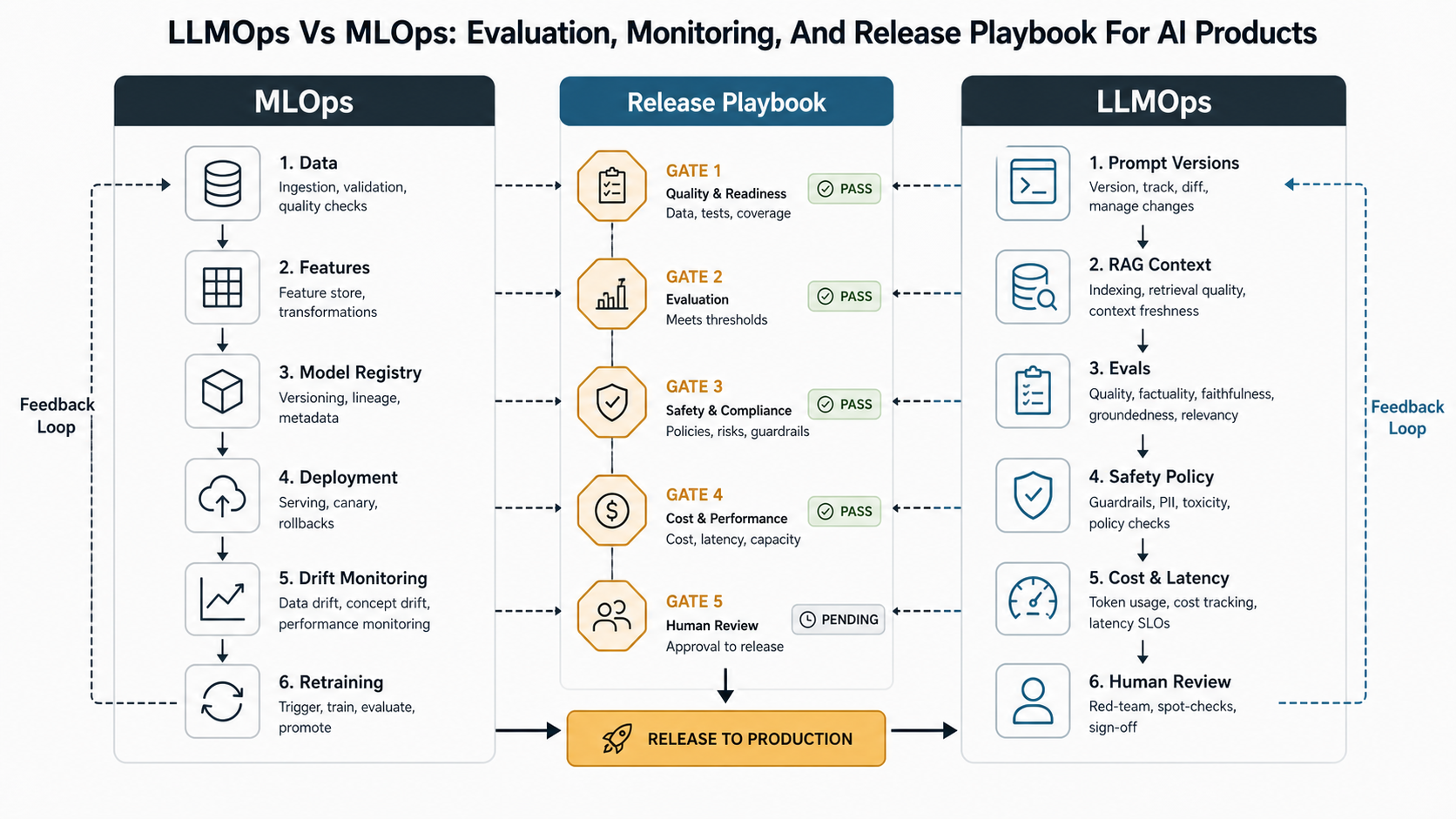

MLOps manages the trained-model lifecycle. LLMOps manages the product-behavior lifecycle around large language models. Most production AI products need both, but they fail in different ways. MLOps controls datasets, features, model versions, deployments, drift, and retraining. LLMOps adds controls for prompts, retrieval, eval sets, groundedness, safety, cost, latency, tool use, human review, and rollback when a behavior change does not involve model training at all.
The practical rule is simple: use MLOps when the primary risk is model performance over structured data. Use LLMOps when the product depends on prompts, RAG, tool calls, generated responses, policy compliance, or human trust. For teams moving from prototype to production, LLM development should include a release playbook that treats prompt, RAG, model, policy, and tool changes as governed product releases.
Quick Answer: LLMOps Vs MLOps
MLOps answers: is the model trained, versioned, deployed, monitored, and retrained reliably? LLMOps answers: did the AI product use the right prompt, context, model route, tool permission, safety policy, eval threshold, and human escalation path for this workflow?
If a fraud model drifts because incoming transaction patterns changed, that is mainly an MLOps problem. If a support copilot starts citing stale refund policy after a knowledge-base update, that is an LLMOps problem. If a product uses classifiers, embeddings, rerankers, RAG, and generated answers together, the operating model must combine both.
LLMOps Vs MLOps Comparison Matrix
A useful comparison should separate artifacts, release triggers, quality evidence, monitoring signals, and rollback scope. This keeps teams from forcing LLM product behavior into a model-only governance process.
| Operating Area | MLOps Focus | LLMOps Focus | Release Evidence |
|---|---|---|---|
| Primary artifact | Dataset, features, model, training job. | Prompt, RAG corpus, eval set, policy, tool plan. | Versioned artifact, owner, review notes. |
| Release trigger | New model, retraining, feature pipeline, drift fix. | Prompt update, model route, RAG source, tool permission, guardrail update. | Change ticket, eval result, rollback path. |
| Quality test | Accuracy, precision, recall, calibration, drift. | Groundedness, answer usefulness, refusal behavior, task success, safety. | Offline evals plus reviewed edge cases. |
| Monitoring | Prediction drift, data drift, inference latency, endpoint health. | Prompt version, retrieved context, token cost, unsafe output, escalation rate. | Trace, alert, dashboard, reviewer queue. |
| Rollback | Model, feature pipeline, threshold, endpoint. | Prompt, retrieval index, model route, policy, tool access, UI handoff. | Known-good version and tested restore path. |
For teams that still need the traditional model side, NextPage's MLOps implementation checklist is the companion piece for model registry, deployment gates, drift alerts, and retraining cadence.
Why LLM Products Need A Different Operating Model
LLM products behave differently because many important changes happen outside the trained model. A team can change a system prompt, add a knowledge source, adjust retrieval ranking, expose a new tool, switch model providers, or alter refusal rules without retraining anything. Each change can alter quality, safety, cost, latency, and user trust.
That is why production LLM systems need traceability across prompt versions, retrieved documents, model routes, policy checks, tool calls, and review outcomes. Without that trail, debugging becomes guesswork. Without release gates, every prompt or retrieval change becomes an uncontrolled production experiment.
If the product is an agent rather than a passive assistant, the control surface expands again. Use the AI Agent Readiness Assessment before increasing autonomy so workflow clarity, data readiness, integration access, and human-review controls are visible before build scope grows.
Where MLOps Still Matters
LLMOps does not replace data engineering, model evaluation, deployment automation, or drift monitoring. It adds another layer for generative behavior. Many products still rely on classifiers, forecasts, embeddings, rerankers, fine-tuned components, or scoring models that need disciplined machine learning development services.
For example, a support copilot may classify ticket type, retrieve policy snippets, rank evidence, draft an answer, and update a CRM field. The classifier and embedding pipeline need MLOps controls. The generated answer and CRM action need LLMOps controls for prompt behavior, retrieved context, policy, permission, evaluation, and review.
Build A Release Playbook Instead Of A Prompt Checklist
A prompt checklist is too narrow. A release playbook should cover the full behavior chain from input to output. Treat every meaningful behavior change as a release candidate, even when no model is retrained.
- Scope the change: prompt, model route, retrieval source, tool permission, policy, eval set, or UI behavior.
- Define the expected improvement: answer accuracy, task completion, lower cost, faster latency, safer refusal, or fewer escalations.
- Run offline evals: compare old and new behavior against representative examples and known failure modes.
- Check groundedness: verify whether answers cite or rely on approved sources.
- Measure cost and latency: track tokens, retrieval size, model route, retries, and tool calls.
- Stage release: use feature flags, reviewer-only release, shadow traffic, or limited rollout before full exposure.
- Watch production signals: monitor failures, escalations, user feedback, unsafe outputs, and unexpected spend.
- Keep rollback ready: revert prompt, model, retrieval index, guardrail, or tool access quickly.
That playbook should be written in product language, not only platform language. Product owns user impact, engineering owns reliability, security owns permissions, and operations owns escalation outcomes.
Use Release Gates For LLMOps And MLOps Changes
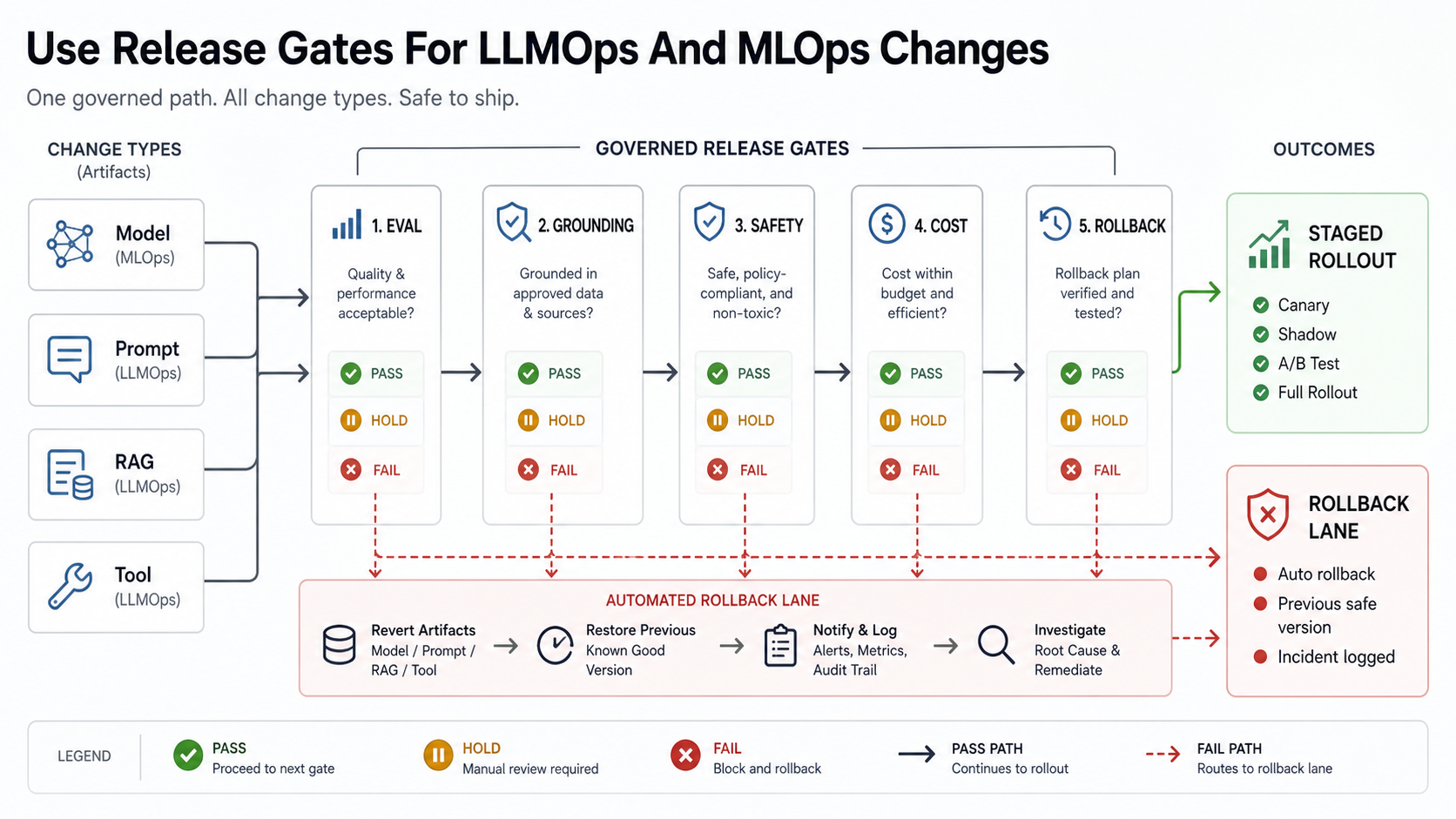
The release gate should be visible to product, engineering, data science, security, support, and domain reviewers. Different teams own different risks, but the release should not ship until the core gates are complete.
| Gate | What To Check | Owner | Hold The Release When |
|---|---|---|---|
| Data and context | Training data, embeddings, source freshness, permissions, retrieval relevance. | Data and AI engineering. | Sources are stale, inaccessible, duplicated, or permission-unsafe. |
| Prompt and policy | Prompt version, refusal rules, tone, scope boundaries, protected workflows. | Product and AI engineering. | Behavior changes are not tied to acceptance criteria. |
| Evaluation | Golden examples, regression tests, groundedness, unsafe output tests, task success. | AI engineering and domain reviewers. | Failures cluster around high-value or high-risk tasks. |
| Cost and latency | Token budget, model route, retrieval size, retries, tool calls, response time. | Platform and product owner. | Better quality depends on unacceptable cost or slow UX. |
| Monitoring and rollback | Trace quality, alerts, escalation paths, feature flags, rollback owner. | Platform, support, and security. | No one can replay, explain, or reverse a bad outcome. |
What To Monitor In LLMOps
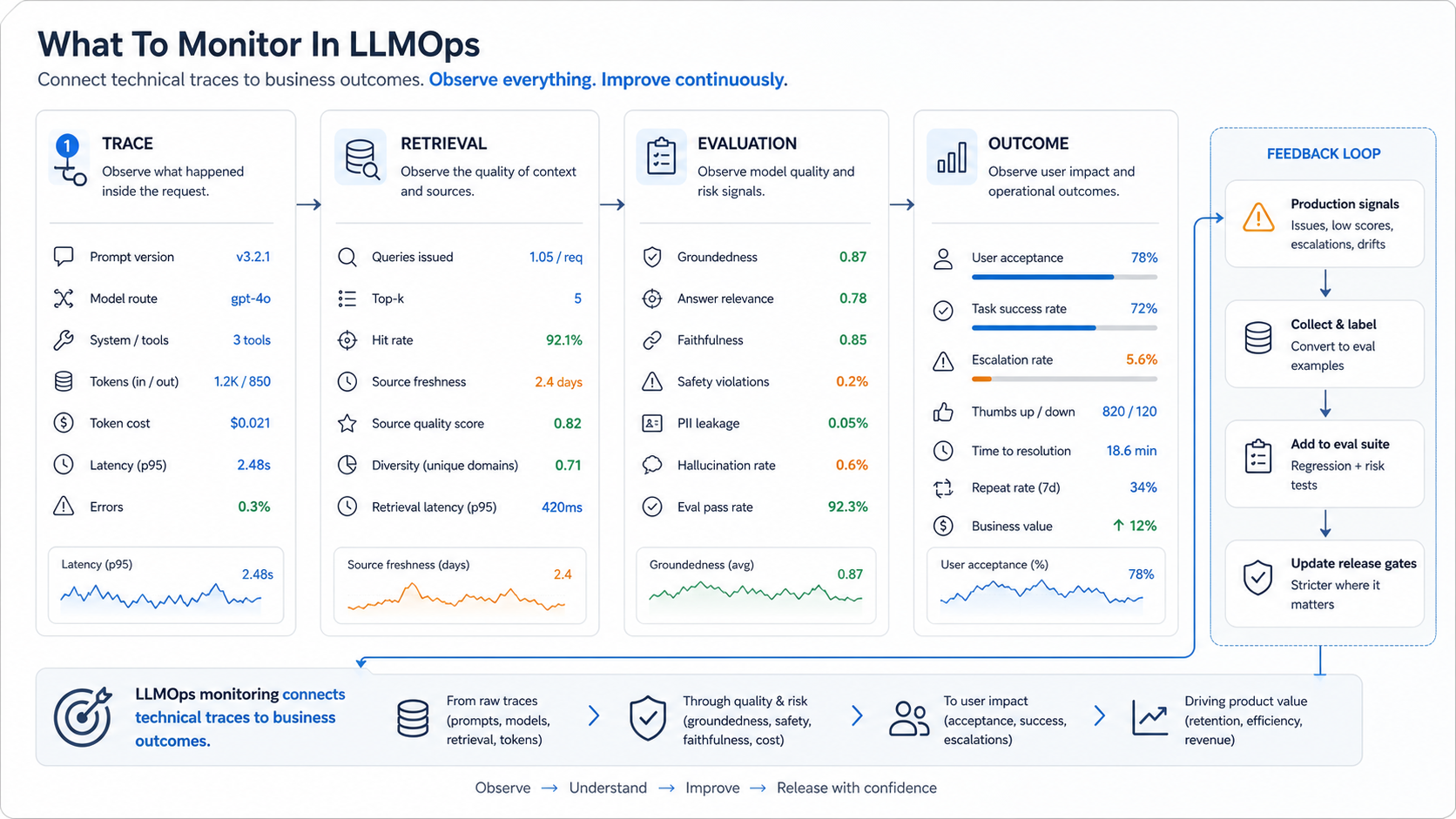
LLMOps monitoring should connect technical traces to product outcomes. Token counts matter, but they are not enough. Track whether the workflow succeeded, whether the user needed help, whether the answer used approved context, and whether the output triggered a safety or policy concern.
- Prompt version: which instruction set created the output.
- Model route: provider, model, mode, fallback, and temperature or reasoning setting.
- Retrieval trace: query, source documents, ranking, freshness, permissions, and citations.
- Evaluation signal: pass/fail scores for groundedness, format, safety, and task completion.
- Cost signal: tokens, retrieval size, tool calls, retries, cache hit rate, and human review time.
- User signal: acceptance, correction, escalation, abandonment, support follow-up, and repeat usage.
For language-heavy products, NLP model monitoring and MLOps services can cover drift and reliability, while LLMOps adds prompt, retrieval, generated-output, and human-trust observability. The AI agent observability checklist goes deeper when tool calls, permissions, and rollback evidence are part of the workflow.
Turn Production Failures Into Better Evals
The best LLMOps systems treat production failures as evaluation data. A low score, bad citation, reviewer correction, escalation, unsafe refusal, or high-cost trace should not disappear into a dashboard. It should become a labeled example, regression test, prompt improvement, retrieval fix, policy update, or release-gate change.
| Production Signal | Likely Cause | LLMOps Action |
|---|---|---|
| User corrects the answer | Weak instruction, missing context, or ambiguous task. | Add the case to evals and review prompt/context rules. |
| Groundedness drops | Bad chunking, stale source, poor retrieval ranking. | Reindex, rerank, or tighten approved-source filters. |
| Escalations spike | Policy uncertainty, confidence gap, or new user intent. | Update review thresholds and add decision examples. |
| Cost per successful task rises | Wrong model route, overlarge context, retries, or tool loops. | Adjust routing, caching, context budget, and retry policy. |
| Unsafe output appears | Missing refusal case, weak guardrail, or risky tool permission. | Block the path, add safety evals, and require review before re-release. |
This feedback loop is where LLMOps becomes operating discipline rather than reporting. It also gives product leaders a practical way to compare quality improvements against cost, latency, and review load.
RAG Changes Need Release Control
RAG systems create a special release risk because the model may stay the same while the answer changes. A new document, stale policy, bad chunk, missing permission, or retrieval ranking change can affect output quality. Treat retrieval changes like software releases.
Production generative AI development should include source ingestion rules, chunk quality checks, permission filters, freshness signals, and retrieval regression tests. If the system answers business-critical questions, the team should be able to replay a failed answer and see the exact context that was available at the time. The knowledge representation for RAG systems guide is a useful next read when source structure, ontologies, or graph context are becoming blockers.
Evals Are The Center Of LLMOps
Evals turn subjective answer quality into a release discussion. Start with a small but representative eval set: common user tasks, hard edge cases, unsafe requests, outdated source scenarios, formatting requirements, and examples that require refusal or escalation.
Use a mix of automated and human review. Automated checks can catch missing citations, malformed JSON, policy keywords, empty answers, response length issues, and obvious grounding failures. Human reviewers are still needed for domain judgment, usefulness, and risk. Good prompt engineering services should include regression examples and acceptance criteria, not just prompt text.
For broader workflow planning, the enterprise AI readiness checklist helps teams confirm data access, security, governance ownership, and rollout operations before the eval suite becomes a proxy for missing product clarity.
Who Owns LLMOps?
LLMOps needs shared ownership. Data science may own model quality, but product owns the workflow, platform owns reliability and cost, security owns permissions, and operations owns escalation outcomes.
| Role | LLMOps Responsibility | Evidence They Should Review |
|---|---|---|
| Product owner | Defines workflow success, release scope, user impact, and launch threshold. | Task success, acceptance, escalation, business metric movement. |
| AI engineering | Owns prompts, retrieval, model routing, evals, and generated-output quality. | Eval results, traces, prompt diffs, retrieved context, failure clusters. |
| Platform engineering | Owns deployment, tracing, cost controls, latency, and rollback systems. | Latency, cost, errors, route health, feature flags, restore drills. |
| Security and compliance | Owns data access, tool permissions, audit logs, and protected actions. | Permission decisions, policy blocks, audit events, incident packets. |
| Domain reviewers | Review examples, edge cases, and high-risk outputs before release. | Golden examples, reviewer notes, corrected answers, escalation reasons. |
For delivery evidence across complex software workflows, a portfolio review can help teams see how NextPage structures operating systems, dashboards, and review queues beyond the AI layer. Start with the NextPage portfolio when buyer stakeholders need proof patterns before approving a production AI roadmap.
LLMOps Implementation Roadmap
Teams do not need a heavy platform before their first LLM feature. They need enough operating discipline to avoid invisible behavior changes.
- Inventory AI behavior: list prompts, RAG indexes, model routes, tools, policies, and reviewers.
- Create an eval set: include success cases, edge cases, unsafe cases, and known failure modes.
- Add tracing: log prompt version, retrieval context, model route, cost, latency, and output status.
- Define release gates: choose what must pass before prompt, model, retrieval, or tool changes ship.
- Stage rollout: use limited traffic, reviewer-only release, shadow mode, or feature flags.
- Monitor production: watch user acceptance, escalation, safety, cost, latency, and outcome quality.
- Review monthly: update evals with real failures, new policies, and changing business workflows.
If your team is choosing between RAG, fine-tuning, AI agents, or transformer-based workflows, transformer model development services can help separate model decisions from product operating decisions.
Common LLMOps Mistakes
- Shipping prompt changes without regression tests. Prompts are product behavior, and product behavior needs release discipline.
- Monitoring only infrastructure health. A fast, available system can still produce ungrounded, unsafe, or unhelpful answers.
- Ignoring cost per successful task. A stronger model may be justified for high-value workflows, but cost must be compared against task success and review effort.
- Treating RAG content as static. Source freshness, permissions, chunking, and retrieval quality need monitoring just like model performance.
- Letting ownership stay vague. If no one owns the eval set, escalation queue, rollback path, or policy exception, the LLMOps system will look mature until the first production incident.
How NextPage Can Help
NextPage helps teams build production AI systems with the right mix of MLOps and LLMOps. We can design eval sets, prompt release gates, RAG observability, model routing, monitoring dashboards, rollback plans, and human review workflows for real products.
If your AI feature is moving from prototype to production, the next step is not only choosing a model. It is building a release playbook that lets your team change prompts, retrieval, tools, and policies without losing quality, trust, or control. For broader build planning, NextPage's AI development services connect LLM delivery with product engineering, integrations, QA, monitoring, and rollout operations.