
Quick Answer: Managed Cloud Services Checklist
A managed cloud services checklist helps you decide whether a provider can actually operate your cloud environment, not just monitor dashboards. The checklist should cover cost optimization, security posture, observability, reliability targets, backup and disaster recovery, migration handoff, modernization backlog, support ownership, and reporting. The strongest providers bring evidence: runbooks, access reviews, tagging standards, SLOs, incident reports, cost reports, backup test results, support RACI, and a clear escalation model.
Use this guide before signing a managed cloud contract or expanding an existing support agreement. If your cloud move is still in progress, pair it with a cloud migration services plan so the migration team hands over clean architecture, infrastructure-as-code, access controls, and operational runbooks instead of leaving support to reverse-engineer the environment later.
What Managed Cloud Services Should Include
Managed cloud services are ongoing operating support for cloud workloads across AWS, Azure, Google Cloud, hybrid cloud, or private infrastructure. A useful provider helps keep applications secure, reliable, observable, cost-aware, and ready for change. That scope can include infrastructure management, DevOps, container operations, data backup, incident response, compliance support, migration assistance, and cloud performance tuning.
The source page for this queue item lists common managed cloud capabilities: infrastructure management, migration, managed data security, application development, analytics, containerization, network management, performance optimization, support operations, regulatory security, backup, disaster recovery, and observability. That is a useful capability map. Buyers still need a sharper question: what evidence proves those services are operating well?
A checklist should therefore ask for artifacts, not promises. Ask for current dashboards, recent incident notes, patch cadence, IAM review history, cost allocation reports, backup restore evidence, deployment pipeline ownership, and an onboarding plan. NextPage's DevOps consulting services use the same operating view: cloud support should connect infrastructure, delivery, monitoring, security, and cost control.
Managed Cloud Service Scope Table
Use this table to separate essential managed cloud coverage from optional add-ons.
| Area | Minimum coverage | Evidence to request |
|---|---|---|
| Cost optimization | Tagging, budgets, rightsizing, waste review, reserved capacity review | Monthly cost report, owner map, savings backlog, anomaly alerts |
| Security | IAM review, patching, secrets, network rules, vulnerability response | Access review, security findings, patch SLA, remediation log |
| Observability | Metrics, logs, traces, alert rules, dashboard ownership | Dashboard list, alert tuning history, runbooks, noisy-alert report |
| Reliability | SLOs, uptime targets, capacity checks, failover and recovery planning | SLO report, incident review, resilience test, capacity forecast |
| Backup and DR | Backup policy, retention, restore testing, disaster recovery runbook | Successful restore evidence, RPO/RTO, backup failure alerts |
| Migration support | Readiness assessment, landing zone, migration waves, cutover support | Migration plan, rollback plan, test evidence, handoff checklist |
| Support ownership | Escalation model, ticket severity, on-call rules, reporting cadence | RACI, SLA/SLO terms, ticket samples, monthly service review |
Do not assume one provider covers every row equally. Some are strong at infrastructure and weak at application support. Some are strong at cost reviews but weak at incident response. Some can migrate workloads but do not want long-term ownership. The contract should match the operating gap you actually have.
Cost Optimization and FinOps
Cloud cost optimization should be an operating practice, not a one-time cleanup. The provider should help identify idle resources, overprovisioned databases, noisy logging, oversized Kubernetes nodes, unused volumes, stale snapshots, inefficient storage tiers, and unowned environments. They should also help teams connect spend to business value.
FinOps matters because cloud costs are created by product, engineering, usage, procurement, and architecture decisions together. A managed cloud provider can produce reports, but internal owners still need to decide which costs are acceptable for growth, resilience, developer speed, or customer experience. Good managed cloud support turns that into a cadence: allocate, observe, optimize, forecast, and review.
Ask these cost questions:
- Are all resources tagged by owner, environment, application, and cost center?
- Which services created the largest month-over-month changes?
- Which savings require architecture changes versus simple rightsizing?
- Are reserved instances, savings plans, or committed-use discounts reviewed against actual utilization?
- Which environments can scale down outside working hours?
- Are logs, traces, metrics, and backups priced into the operating plan?
For SaaS teams, the cost model often overlaps with delivery architecture. NextPage's DevOps consulting for SaaS teams guide explains why CI/CD, environments, observability, and FinOps should be planned together.
Security and Compliance Checklist
Managed cloud security is shared work. The cloud provider secures the underlying cloud services, but your team and managed provider must handle identity, network access, data protection, workload configuration, secrets, patching, monitoring, and incident response. AWS, Azure, and Google all frame cloud architecture around security, reliability, operational excellence, cost, and performance; managed support should map to those pillars.
| Security control | Checklist question | Evidence |
|---|---|---|
| Identity | Are users, service accounts, roles, and privileged access reviewed? | IAM review, break-glass policy, MFA status |
| Network | Are public endpoints, firewall rules, private links, and ingress paths documented? | Network diagram, open-port report, rule owner list |
| Secrets | Are secrets stored, rotated, and audited through approved tooling? | Secret inventory, rotation cadence, access log |
| Vulnerabilities | Are images, dependencies, servers, and managed services checked and patched? | Scanner report, patch SLA, exception register |
| Data protection | Are encryption, retention, regional, and backup rules explicit? | Data classification, encryption report, retention map |
| Incident response | Who responds when a cloud security alert fires? | Runbook, severity matrix, escalation contacts |
If the provider cannot show these artifacts during onboarding, security work will likely become reactive after an incident or audit request.
Monitoring, Observability, and AIOps
Monitoring tells you something is wrong. Observability helps you understand why. Managed cloud support should cover both. At minimum, define metrics, logs, traces, dashboards, alerts, on-call routing, incident severity, and post-incident review. For complex environments, add anomaly detection, dependency mapping, alert correlation, and automated triage. That is where AIOps consulting services can help reduce alert noise and speed up incident investigation.
Ask for a monitoring inventory that includes application health, infrastructure health, database health, queue depth, job failures, certificate expiry, backup failures, API latency, error rates, cloud spend anomalies, and security alerts. Every alert should have an owner, severity, expected response, and runbook. If nobody owns an alert, it is dashboard decoration.
Also ask how the provider measures their own support quality: mean time to acknowledge, mean time to resolve, recurring incident count, noisy alert count, unresolved risk items, and overdue remediation actions.
Reliability, SLOs, Backups, and Disaster Recovery
Reliability support starts with business expectations. A checkout system, internal dashboard, batch report, and development environment do not need the same uptime, failover, or recovery design. The provider should help translate business requirements into SLOs, RPO, RTO, capacity plans, backup policies, and disaster recovery tests.
Use realistic reliability questions:
- Which workloads need high availability, and which can tolerate planned downtime?
- What are the recovery point objective and recovery time objective for each workload?
- When was the last restore test, and what failed?
- Which services are single points of failure?
- Can deployments be rolled back quickly?
- Are incidents reviewed with action items and owners?
Reliability is also tied to performance. If users complain about latency, capacity, or intermittent failures, managed support should include profiling, scaling review, database tuning, caching review, and architecture changes. NextPage's cloud performance optimization services focus on those runtime bottlenecks and cost/performance tradeoffs.
Migration Handoff and Modernization
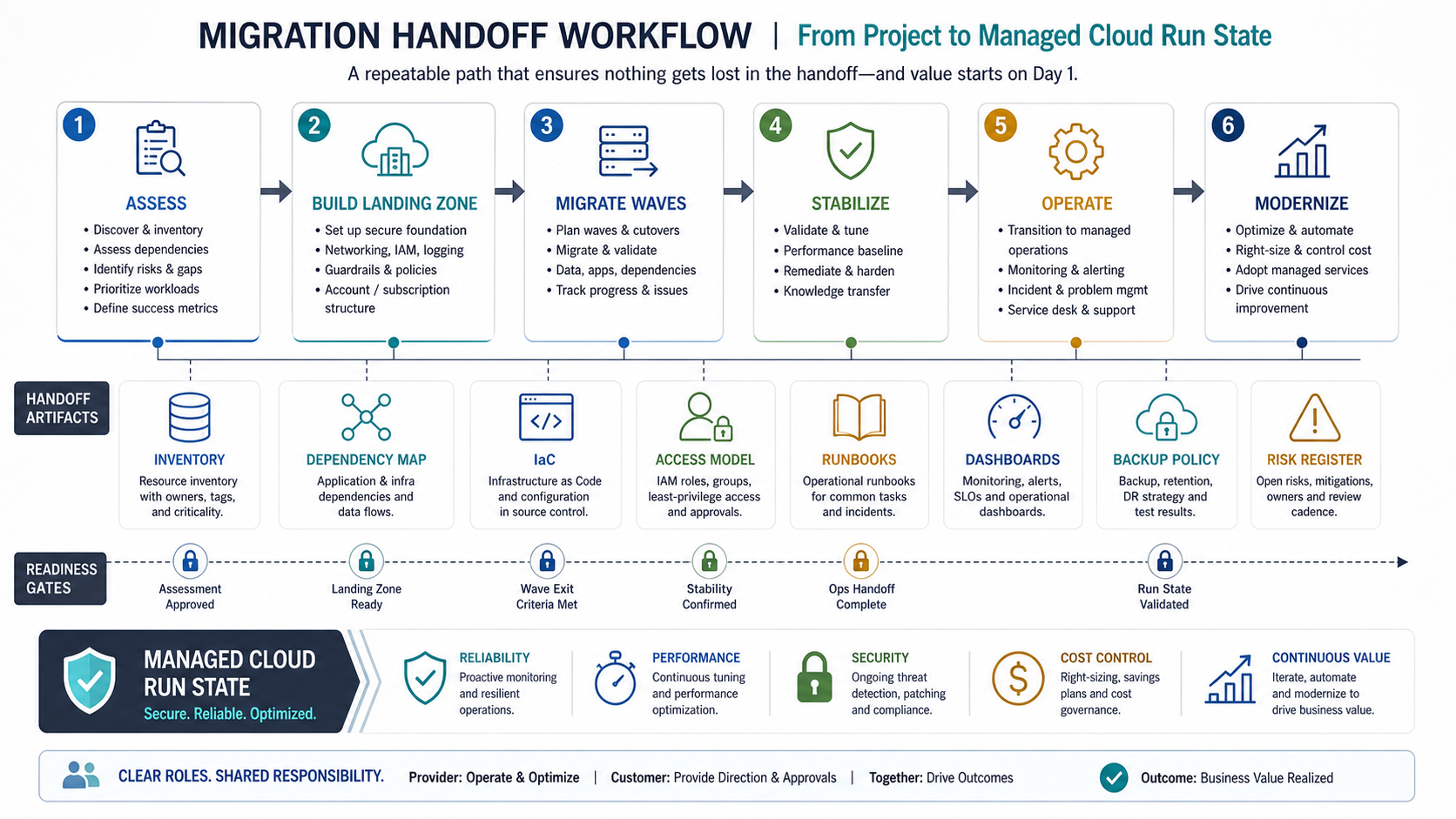
Managed cloud service starts earlier than many teams think. If the migration team does not hand over clean documentation, support begins in discovery mode. A strong migration handoff includes workload inventory, dependency map, environment plan, IAM design, network layout, deployment process, data migration evidence, test results, rollback plan, monitoring setup, backup policy, and known risks.
After handoff, managed support should maintain a modernization backlog. That backlog may include replacing manual deployments with CI/CD, moving pets to containers, cleaning up storage, tightening IAM, adding infrastructure as code, simplifying networks, improving observability, or splitting fragile monolith workloads gradually. For legacy environments, application migration services and managed support should work from the same roadmap.
The handoff should end with a run-state review: what is monitored, what has a runbook, what is backed up, what has rollback evidence, what is still a known risk, and who owns the next modernization decision.
Managed Cloud Provider Scorecard

Score managed cloud providers by operating evidence, not by the number of services listed in a proposal. A useful scorecard should cover the six areas that decide whether support will be proactive: cost, security, observability, reliability, backup/DR, and support ownership.
| Scorecard area | Strong evidence | Warning sign |
|---|---|---|
| Cost and FinOps | Tagged resources, owner map, monthly variance review, savings backlog, anomaly alerts | Only a high-level bill export with no owner or action list |
| Security posture | IAM review, network exposure report, patch SLA, secrets inventory, remediation log | Security is described as "included" without control ownership |
| Observability | Dashboards, alert owners, runbooks, alert tuning history, incident review notes | Dashboards exist but nobody owns noisy or unactioned alerts |
| Reliability | SLO report, capacity forecast, incident trend, rollback evidence, resilience tests | Uptime promise without workload-specific SLOs or recovery evidence |
| Backup and DR | Restore test results, RPO/RTO map, backup failure alerts, DR runbook | Backups run but restore tests are not scheduled or documented |
| Support ownership | RACI, severity matrix, escalation path, monthly service review, open-risk register | All requests go through the same ticket queue with unclear priority |
This scorecard also helps separate platform support from product responsibility. A managed provider can run infrastructure, but your team still owns product tradeoffs, customer impact, data classification, and budget decisions.
What To Keep Internal Vs Managed
Do not outsource decisions that require business context. Keep product risk acceptance, budget thresholds, data classification, customer communication, roadmap priority, and architecture tradeoffs inside your leadership or engineering team. Managed support can recommend changes, execute approved runbooks, maintain dashboards, and document risks, but the provider should not silently decide which reliability, security, or cost tradeoffs are acceptable for your customers.
A healthy model is shared ownership: your team sets business priorities and accepts risk; the provider maintains cloud evidence, proposes improvements, executes operational work, and escalates decisions before risk compounds.
Vendor Evaluation Questions
Use these questions in vendor calls and proposals:
- What is included in onboarding, and what evidence do you need from us?
- How do you document environments, owners, access, and runbooks?
- What is your process for cost optimization and budget reviews?
- How often do you review IAM, network exposure, patching, and vulnerabilities?
- What monitoring do you set up by default, and what do you tune after the first month?
- How do you handle incidents, escalation, root-cause analysis, and action items?
- Do you test backup restores, or only report that backups ran?
- How do you support migration cutover, rollback, and post-migration stabilization?
- Which work remains our responsibility?
- What does the monthly service review include?
The last question is important. A managed provider can operate cloud infrastructure, but your team still owns product priorities, business risk, data classification, user impact, and budget tradeoffs.
How NextPage Helps
NextPage helps teams plan cloud migration, stabilize cloud operations, improve observability, reduce avoidable cloud waste, and modernize workloads that have outgrown ad hoc support. We start with current-state evidence: architecture, spend, incidents, access, deployments, backups, and operational ownership.
If your team is preparing for a move, start with cloud migration services. If the workload is already in cloud but support feels reactive, NextPage can help with DevOps, cloud performance, AIOps, and support planning. Budget the work like ongoing product maintenance, not a one-time ticket queue; the software maintenance cost guide is a useful companion for that conversation.