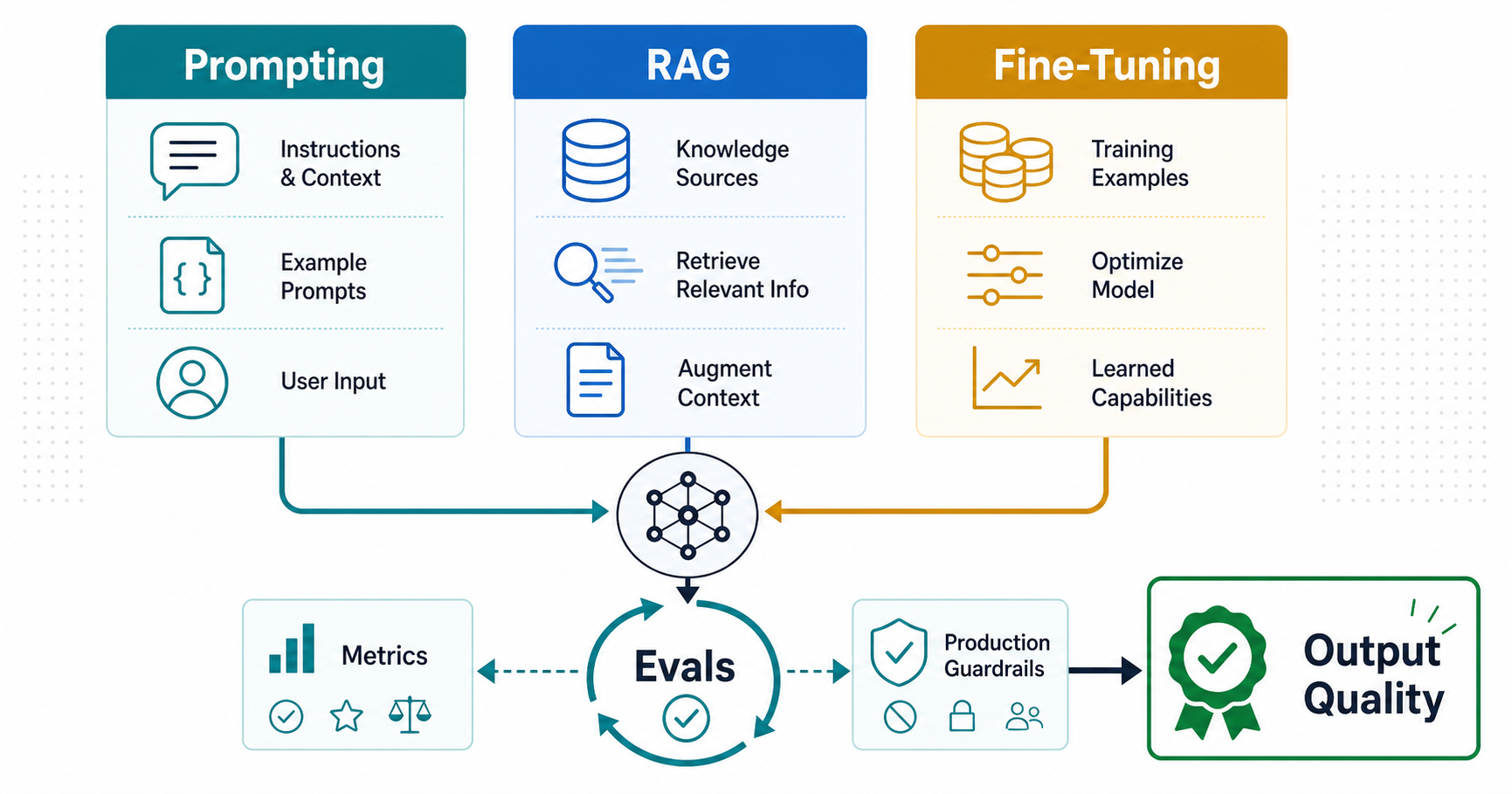

Quick Answer: Which Lever Should You Use?
Use prompt engineering when the model already has enough knowledge and the failure is instruction clarity, examples, output structure, tone, or task boundaries. Use retrieval-augmented generation when the answer depends on private, fresh, source-backed, product-specific, policy-specific, or permission-aware knowledge. Use fine-tuning when the system repeatedly fails a narrow behavior, format, classification, or style pattern even after strong prompts, schemas, and retrieval have been tested.
The practical order is usually not prompt engineering vs RAG vs fine-tuning as a one-time choice. Start with evals, improve prompts, add retrieval when the model needs grounded knowledge, and consider fine-tuning only when you have enough representative examples to prove the remaining gap. If the issue is unsafe workflow behavior, permissions, or irreversible actions, redesign the product flow before training a model.
For most business applications, NextPage starts by diagnosing the failure mode inside the workflow. Our LLM development work typically maps the user journey, expected answer, data sources, failure categories, and acceptance tests before choosing a model architecture.
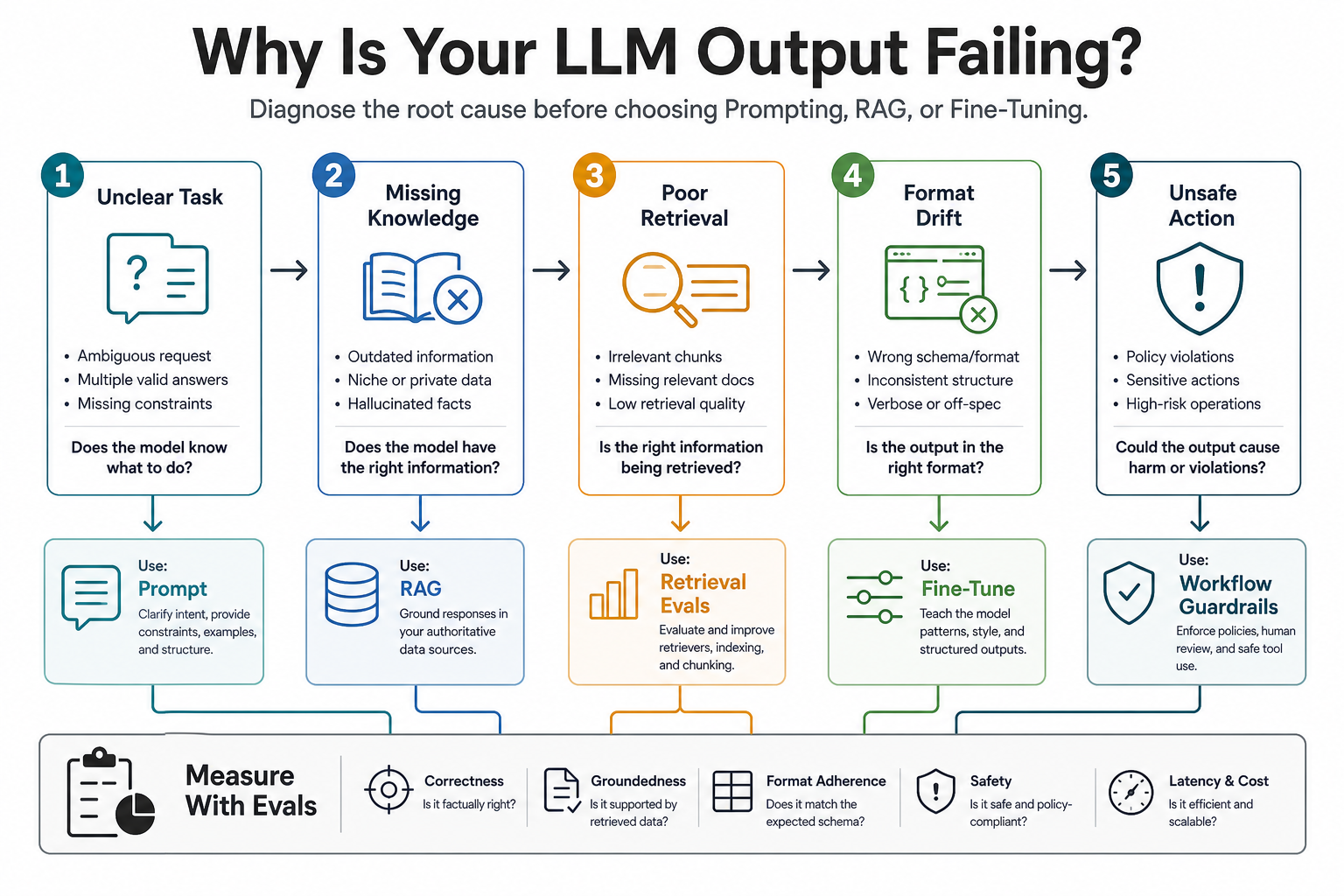
Why LLM Output Fails In The First Place
A weak LLM answer is a symptom, not a diagnosis. The model may misunderstand the task, lack the right business context, retrieve the wrong source, ignore the required format, use stale knowledge, or be asked to make a decision that should be handled by deterministic software. Each failure points to a different fix.
Prompt engineering changes instructions and examples. RAG changes what knowledge enters the prompt at runtime. Fine-tuning changes model behavior through training examples. Evals tell you whether any of those changes helped. Workflow redesign changes whether the model should be responsible for the step at all.
The first question should be: what kind of failure are users seeing? If support answers are stale, RAG is usually more useful than another prompt rewrite. If summaries ignore a required template, prompting or fine-tuning may help. If retrieved passages are wrong, retrieval evaluation matters more than response generation. If the model makes unsupported business decisions, guardrails, permissions, and human review matter more than model customization.
What Prompt Engineering Actually Solves
Prompt engineering is the fastest and cheapest lever because it changes the request, not the model or the knowledge system. It works when the model has enough general capability but needs clearer goals, few-shot examples, role boundaries, output schemas, refusal rules, or task decomposition.
In production, prompt engineering is instruction design. A strong prompt defines what the system should do, what it should not do, what inputs matter, how output should be structured, how uncertainty should be handled, and when to escalate. It also needs versioning and regression tests because model behavior changes as prompts, tools, documents, and model snapshots evolve.
Prompt engineering fits when the model gives roughly correct information in the wrong format, the task can be solved from the user request and stable context, the team needs fast iteration, or the workflow is still discovering what "good" means. The related article on hiring AI prompt engineers is useful when the bottleneck is instruction design, eval examples, and prompt operations rather than full product delivery.
Prompting is a poor standalone fix when the answer depends on large changing document sets, private policies, product catalogs, customer records, support history, or regulated source material. Long prompts can hide the problem for a demo, but they become brittle when the source corpus grows or when users need citations.
What RAG Solves Better Than Prompting
Retrieval-augmented generation gives the model relevant information at answer time. A typical RAG system chunks approved content, embeds it, stores it in a searchable index, retrieves the most relevant passages for a query, and asks the model to answer using that context. The goal is not only a smarter answer. The goal is a more grounded, inspectable, and updateable answer.
RAG is usually the right next step when the failure is missing knowledge. Examples include customer support bots, internal copilots, policy assistants, proposal assistants, onboarding assistants, product documentation search, sales enablement, legal knowledge workflows, and compliance support. For commercial delivery, enterprise RAG implementation services should include content hygiene, metadata, access control, retrieval evaluation, source display, monitoring, and content operations.
RAG is not magic. Retrieval quality depends on chunking, metadata, permissions, ranking, freshness, query rewriting, reranking, and evaluation. A bad RAG system can confidently cite the wrong passage. A good one makes the knowledge boundary visible and testable, then improves both retrieval and response quality over time.
When Fine-Tuning Is Worth Considering
Fine-tuning teaches a model to behave differently through examples. It can improve format adherence, specialized rewriting, classification, extraction, tone, routing, and narrow domain behavior when the team has reliable input-output pairs and a way to measure improvement.
Fine-tuning is worth considering when you can say: we have many examples of the inputs we expect, the outputs we want, and the mistakes we need to avoid. Without that dataset, fine-tuning can turn vague product taste into expensive noise. It also does not solve freshness, citations, document permissions, or private knowledge access by itself.
Good fine-tuning candidates include support triage, structured extraction, domain labeling, compliance-aware wording patterns, repeated style transformations, translation style, and strict response formats that still drift after prompt and schema improvements. For broader domain-specific systems, compare fine-tuning with RAG and agent patterns using the domain-specific LLM development guide before committing to a training path.
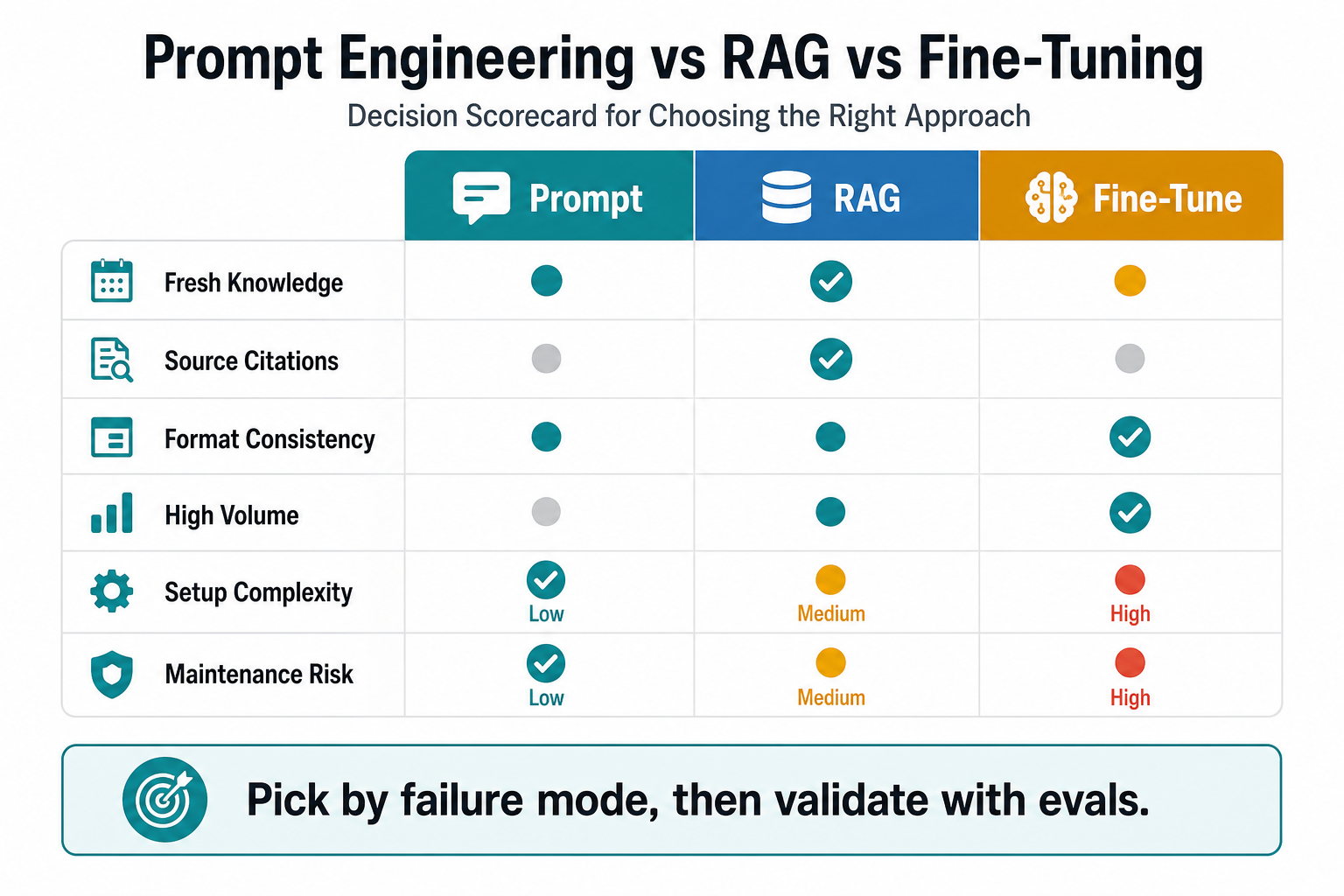
Decision Matrix: Prompt Engineering, RAG, Or Fine-Tuning
| Failure Signal | Best First Lever | Why | Escalate When |
|---|---|---|---|
| Answers are verbose, vague, or poorly formatted | Prompt engineering | The model likely needs clearer instructions, examples, and output rules. | Format failures persist across strong examples, structured outputs, and validation. |
| Answers are stale or missing company facts | RAG | The model needs approved knowledge at runtime. | Retrieval is accurate but response behavior remains unreliable. |
| Answers need source references | RAG | Retrieved passages can be shown, filtered, and audited. | Citations are correct but the final answer misses the required structure. |
| The model ignores a specialized response pattern | Prompting, then fine-tuning | Few-shot examples may be enough; training helps only after repeated failure is measured. | You have enough high-quality examples to train and evaluate. |
| The task is narrow, high-volume, and repetitive | Fine-tuning or smaller-model optimization | Training can reduce prompt length, latency, and per-request cost at scale. | The answer depends on documents, policies, or product data that change often. |
| The AI takes actions in business systems | Workflow redesign plus evals | Permissions, rollback, audit logs, and human review matter as much as language quality. | The action policy is stable and output consistency still limits automation. |
Start With Evals Before Changing The Architecture
Evals turn subjective AI quality complaints into an engineering loop. Start with common requests, edge cases, adversarial inputs, outdated-document traps, formatting requirements, escalation scenarios, and cases where the right answer is "I do not know." Score factuality, groundedness, completeness, format, tone, latency, cost, and handoff behavior.
Keep the first eval set small enough to run often, then expand it as real usage shows where failures cluster. Baseline the current prompt and retrieval setup before changing anything. Otherwise, teams can spend weeks improving one demo while making real customer paths worse.
The AI Agent Readiness Assessment is useful before teams add tool use or agent behavior. It separates workflow readiness, data readiness, integration risk, and governance gaps before the model starts taking actions.
A Practical Implementation Order
Most teams should improve LLM output in this sequence:
- Define the job: identify the workflow, user, acceptable risk, expected output, escalation path, and business metric.
- Create evals: build a representative test set with realistic inputs, edge cases, and scoring rules.
- Fix prompts: add clearer instructions, examples, schemas, uncertainty handling, and refusal boundaries.
- Add retrieval: ingest approved content, add metadata filters, test retrieval quality, and expose source evidence when useful.
- Add guardrails and tools: validate structured outputs, constrain actions, log decisions, and keep humans in sensitive loops.
- Consider fine-tuning: train only when the gap is behavior or format consistency and you have enough examples.
- Operate the system: monitor drift, update content, review failures, and rerun evals before each model, prompt, retrieval, or policy change.
This sequence is the foundation of production generative AI development. The goal is not to pick the most advanced technique. The goal is to spend engineering effort where it reduces the most user, cost, and governance risk.
When Hybrid Patterns Make Sense
The strongest systems often combine methods. A support copilot may use prompt engineering for tone and escalation rules, RAG for policy and product knowledge, tool calls for account-specific status, and evals for regression testing. A document automation system may use retrieval for reference material and fine-tuning for a strict output format. An internal knowledge assistant may use RAG first and later fine-tune a smaller model for classification or routing.
Hybrid does not mean stacking every AI technique into the first release. It means using each layer for the problem it actually solves. Keep retrieval responsible for knowledge. Keep prompts responsible for instructions and boundaries. Keep fine-tuning responsible for repeated learned behavior. Keep deterministic software responsible for calculations, permissions, and irreversible actions.
Cost, Latency, And Maintenance Tradeoffs
Prompt engineering is cheap to change but can become expensive at runtime if every request carries long examples and context. RAG adds ingestion, vector storage, ranking, document permissions, evaluation, and content operations. Fine-tuning adds data preparation, training, model lifecycle, regression testing, and deployment risk.
Cost should be measured per successful workflow, not only per token. A cheap prompt that produces support escalations is not cheap. A RAG pipeline that answers accurately but takes too long may fail the user experience. A fine-tuned model that saves tokens but cannot cite sources may fail compliance review. The right architecture balances output quality, latency, operating cost, auditability, and maintainability.
Teams that are early in AI planning should read the Enterprise AI Readiness Checklist and use the Workflow Automation Opportunity Finder before funding a complex system. Data quality, access control, review workflows, and ownership often decide success before model selection does.
Common Mistakes To Avoid
- Fine-tuning for knowledge: training on documents that change weekly usually creates stale behavior instead of a reliable knowledge system.
- RAG without retrieval evals: if the wrong passages are retrieved, the final answer may look grounded while being wrong.
- Prompts without failure boundaries: a polished prompt still needs uncertainty handling, escalation, and validation rules.
- Ignoring product workflow: some "LLM quality" problems are actually UX, permissions, data model, or integration problems.
- Choosing architecture before ROI: use an AI Automation ROI Calculator or a simple operational model to prove the workflow is worth automating.
- Skipping monitoring: model snapshots, content updates, and user behavior change over time. Quality must be measured continuously.
How NextPage Helps Improve LLM Output
NextPage helps teams turn vague AI quality complaints into an implementation plan. We audit the workflow, build evals, inspect prompt and retrieval design, map data sources, define guardrails, and decide whether fine-tuning is justified. The output is a practical roadmap: what to fix now, what to test next, and what to avoid until the system has enough evidence.
If you are building an internal copilot, customer-support chatbot, RAG assistant, workflow agent, or LLM-powered SaaS feature, start with a quality assessment. Our AI development services combine product engineering, retrieval, prompt design, evaluation, integrations, QA, and rollout support so the system improves in production instead of only in demos. The vendor scorecard in How To Choose An AI Development Company can also help evaluate whether a partner understands the tradeoffs.
The best LLM architecture is not the one with the most AI terminology. It is the one that gives users accurate, useful, auditable answers at the cost and risk level your business can operate.