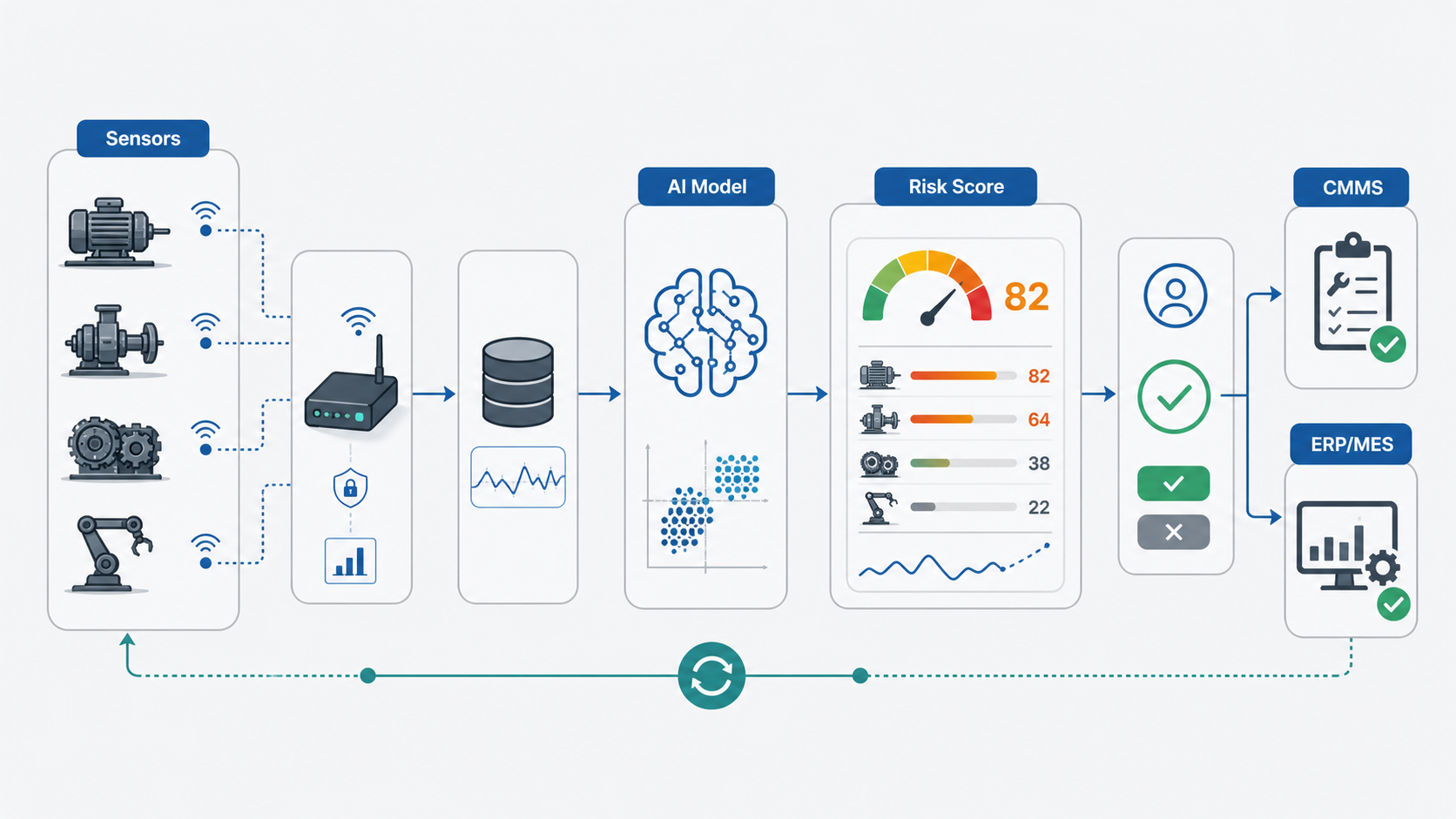

Quick Answer: Predictive Maintenance Software With IoT and AI
Predictive maintenance software uses machine, sensor, operating, quality, and maintenance data to warn teams when an asset is drifting toward failure. The goal is not a prettier dashboard. The goal is to help maintenance teams decide which asset to inspect, which work order to create, which spare part to stage, and which production window to protect.
A practical manufacturing roadmap starts with a narrow asset class, reliable telemetry, clear failure modes, and integration with the systems where maintenance work already happens. AI becomes valuable after the plant has enough trusted data and enough workflow discipline to turn predictions into action. For most teams, that means pairing AI development services, machine learning development, IoT data pipelines, and CMMS or ERP integration instead of treating predictive maintenance as a standalone analytics project.
If the business case is still unclear, run the candidate workflow through an AI automation ROI calculator before funding a broad rollout. The first pilot should prove that earlier warnings reduce avoidable downtime, emergency maintenance, spare-part delays, and planner workload without flooding technicians with false alarms.
Where Predictive Maintenance Fits in a Manufacturing Roadmap
Predictive maintenance sits between basic preventive maintenance and autonomous maintenance orchestration. Preventive maintenance follows fixed schedules. Condition monitoring shows what is happening now. Predictive maintenance looks at patterns over time and estimates which equipment needs attention before failure becomes visible on the line.
It works best when the plant already knows which failures are expensive, repeated, and detectable. A compressor with vibration data, temperature readings, runtime hours, maintenance history, and a clear failure pattern is a better first target than a broad plant-wide promise to predict every issue. The broader AI in manufacturing roadmap matters, but predictive maintenance should start with one decision workflow and one measurable operating outcome.
| Maturity Stage | What the Plant Has | What Software Should Do | Typical Next Step |
|---|---|---|---|
| Reactive maintenance | Breakdown logs, technician notes, scattered spreadsheets | Centralize failures and repair actions | Clean asset hierarchy and maintenance history |
| Preventive maintenance | Calendar or runtime schedules | Digitize schedules and track compliance | Add sensor context and failure codes |
| Condition monitoring | Live vibration, current, temperature, pressure, or PLC signals | Show thresholds, trends, and exceptions | Build event history and alert triage |
| Predictive maintenance | Sensor history, failure labels, work orders, operating context | Score risk and recommend inspection or repair | Integrate alerts with CMMS and planner review |
| Prescriptive maintenance | Trusted models, parts data, schedules, production constraints | Suggest timing, parts, and resource plans | Add governed automation and approval workflows |
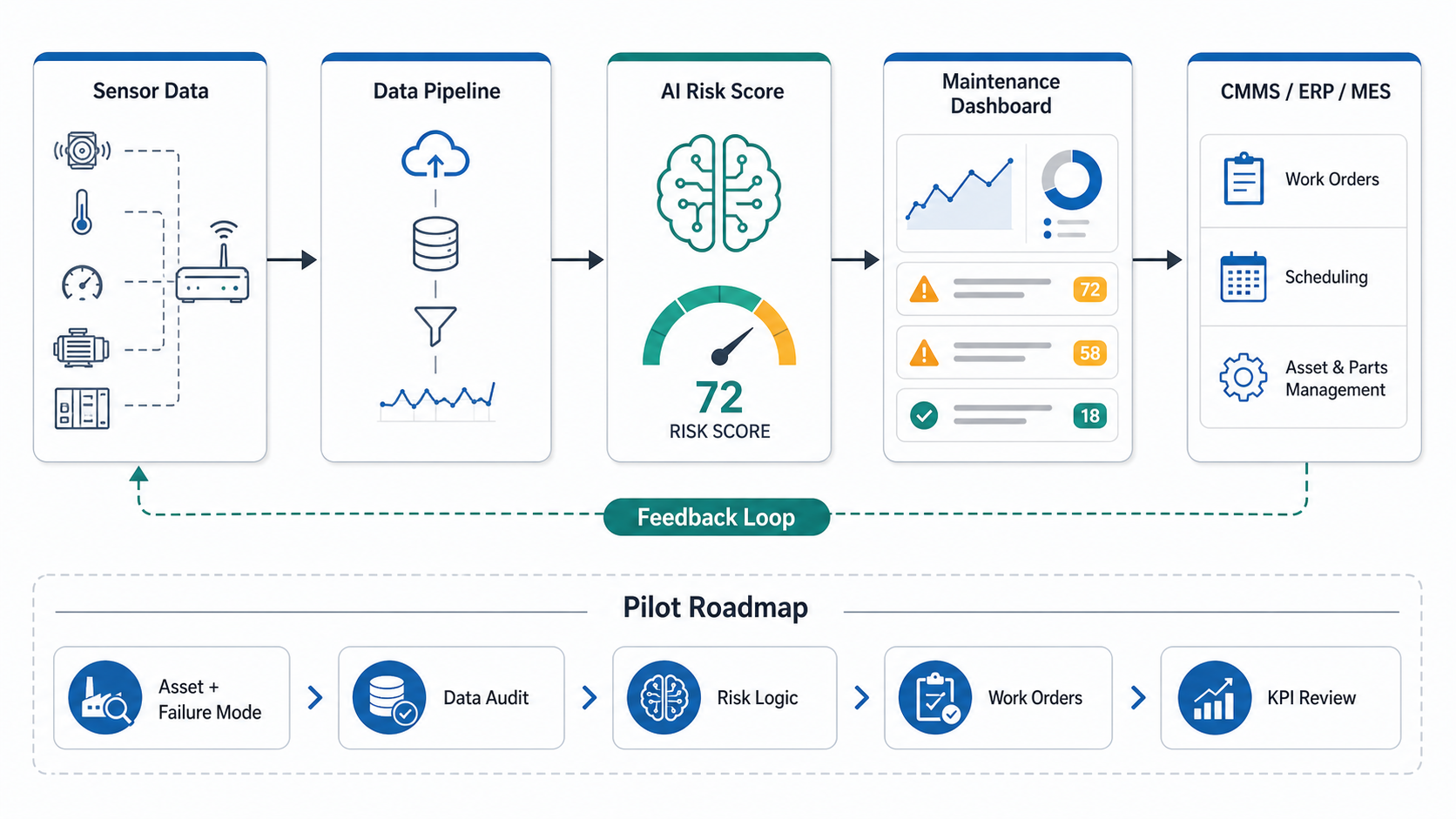
Predictive Maintenance Software Architecture
A production-ready architecture has five layers. Each layer should be designed for reliability and auditability, because maintenance decisions affect production uptime and safety.
- Data capture: Sensors, PLCs, SCADA, edge gateways, inspection systems, operator inputs, and CMMS records provide raw signals.
- Data pipeline: Streaming and batch pipelines normalize time-series data, asset IDs, failure codes, work-order events, and production context.
- Feature and model layer: Rules, anomaly detection, forecasting, and supervised models generate health indicators and risk scores.
- Application layer: Dashboards, alert queues, asset views, and reliability reports help engineers and planners decide what to do.
- Workflow layer: CMMS, ERP, MES, inventory, and approval systems turn warnings into inspections, work orders, part reservations, and schedule changes.
The most common failure is stopping at layer four. A dashboard may show a bearing temperature trend, but if nobody creates a work order, reserves parts, or coordinates downtime, the model has not changed the maintenance outcome. That is why predictive maintenance should be treated as custom workflow software, not only as a data science exercise.
Data Requirements Before You Train a Model
Predictive maintenance quality depends on data quality more than algorithm choice. Before training models, map the asset hierarchy, sensor availability, history length, failure labels, operating modes, maintenance actions, and production constraints.
| Data Area | Examples | Why It Matters |
|---|---|---|
| Asset master data | Equipment ID, line, component, criticality, OEM, age, location | Prevents mismatched signals and work orders |
| Sensor and PLC data | Vibration, temperature, current, pressure, speed, load, runtime | Shows operating behavior before failure |
| Maintenance history | Failure codes, repair notes, replaced parts, technician comments | Connects signals to real outcomes |
| Operating context | Shift, product type, recipe, throughput, ambient conditions | Reduces false alerts caused by normal operating changes |
| Quality and inspection data | Scrap, rework, defect type, inspection results | Links asset health to production quality |
| Planning and inventory data | Spare parts, lead times, maintenance windows, production schedule | Turns prediction into an executable plan |
Teams that are unsure whether their data is ready should assess workflow clarity, data access, integration depth, and human-review controls before building. The AI Agent Readiness Assessment is useful even for non-agent predictive maintenance work because it scores the same readiness factors: workflow, data, integrations, and governance.
Implementation Roadmap for a First Pilot
A predictive maintenance pilot should be narrow enough to validate but real enough to matter. Do not begin with every machine in the plant. Begin with a high-value asset group where failures are expensive, detection is plausible, and the maintenance team can act on warnings.
Step 1: Select the Asset and Failure Mode
Choose assets with repeated downtime, measurable symptoms, and clear maintenance actions. Define the specific failure modes you want to detect, such as bearing wear, overheating, abnormal current draw, lubrication issues, pressure instability, or recurring quality drift.
Step 2: Audit Data and Instrumentation
Confirm which signals already exist, which sensors need to be added, and how often data should be sampled. High-frequency vibration may be necessary for rotating equipment, while lower-frequency temperature or current readings may be enough for other use cases.
Step 3: Build the Reliability Dataset
Normalize timestamps, asset IDs, sensor units, operating modes, maintenance actions, and failure labels. Include negative examples, not only failures, so the system learns normal operating patterns. Use the Enterprise AI Readiness Checklist as a governance reference for data ownership, access, quality, and security decisions.
Step 4: Create the First Risk Logic
Start with rules, thresholds, trend detection, and anomaly scoring if failure labels are limited. Move to supervised models when the dataset includes enough verified failure events and maintenance outcomes.
Step 5: Connect Alerts to Maintenance Workflows
Define who reviews alerts, what information they see, when a work order is created, which spare parts are checked, and how the action is closed. This is where AI workflow automation patterns help: keep human approval where risk is high, log every decision, and monitor outcomes after action.
Step 6: Measure and Expand
Run the pilot long enough to compare baseline maintenance patterns with model-assisted decisions. Expand only after technicians trust the alerts and planners can show fewer urgent repairs, better scheduling, or faster root-cause investigation.
AI Model Strategy: Start Simple, Then Improve
Manufacturing teams often jump straight to deep learning when simpler methods would produce a usable pilot faster. The right model depends on signal quality, history length, failure labels, and interpretability needs.
| Approach | Best When | Limitations |
|---|---|---|
| Rules and thresholds | Known safe ranges and clear engineering limits exist | Can miss slow drift and context-specific changes |
| Trend and anomaly detection | Failures are rare but normal behavior can be modeled | Needs careful triage to avoid alert fatigue |
| Remaining useful life models | Historical degradation curves are available | Requires enough comparable asset histories |
| Supervised failure prediction | Failure events are labeled and linked to sensor history | Can overfit when labels are sparse or inconsistent |
| Hybrid reliability scoring | Engineering rules and ML signals both matter | Needs governance so teams know which signal drove an alert |
A strong machine learning development plan should include feature monitoring, model versioning, false-positive review, retraining triggers, and rollback options. Maintenance teams need explanations they can trust, not only a probability score.
CMMS, ERP, and MES Integration Plan
Predictive maintenance only creates value when warnings reach the systems used to plan work. At minimum, define how the software reads asset data, creates or recommends work orders, checks spare-part availability, respects production schedules, and writes outcomes back for learning.
- CMMS: Create inspection tasks, preventive maintenance adjustments, repair work orders, closure codes, technician notes, and maintenance history.
- ERP: Check spare-part inventory, purchase lead times, maintenance cost centers, vendor data, and asset master records.
- MES: Understand line status, production schedule, batch or recipe changes, downtime windows, and quality events.
- SCADA or historian: Pull validated time-series data and equipment states without disrupting control systems.
- Notification tools: Route alerts to planners, reliability engineers, supervisors, and technicians with escalation rules.
If ERP and MES architecture is still being modernized, align the pilot with the manufacturing systems roadmap. The manufacturing ERP implementation guide covers integration architecture and rollout planning that often determines whether predictive maintenance can scale beyond one line.
Dashboards, Alerts, and Human Review
The application experience should help people make decisions quickly. A maintenance dashboard should not show every raw signal by default. It should show asset risk, confidence, contributing signals, recent operating context, recommended action, related work orders, spare-part status, and the cost of waiting.
Design alerts around action thresholds, not curiosity. For example, a vibration anomaly may trigger observation, a repeated anomaly during high-load operation may trigger inspection, and a confirmed pattern with rising temperature may create a recommended work order. Each alert should have an owner, severity, expiration rule, and closure reason.
For higher-risk assets, keep a reliability engineer or planner in the loop before work orders are automatically created. Human review also improves the dataset because accepted, rejected, and deferred recommendations become training evidence.
KPIs That Prove the Pilot Is Working
The pilot scorecard should combine production outcomes, maintenance outcomes, and model behavior. Do not rely only on model accuracy because a technically accurate alert may still be operationally useless if it arrives too late or creates too much noise.
| KPI | What It Shows | How to Use It |
|---|---|---|
| Unplanned downtime hours | Whether failures are being prevented or shortened | Compare against a baseline for the same asset group |
| Mean time between failures | Whether reliability is improving | Track by asset class and failure mode |
| False alert rate | Whether technicians will trust the system | Review rejected alerts and tune thresholds |
| Lead time before failure | Whether alerts arrive early enough to act | Set minimum useful warning windows by asset type |
| Work-order conversion rate | Whether alerts turn into maintenance action | Separate observation, inspection, and repair actions |
| Emergency maintenance ratio | Whether reactive work is declining | Monitor urgent repairs against planned maintenance |
| Planner and technician workload | Whether the system reduces or adds coordination work | Include alert review time in ROI calculations |
Use the AI Automation ROI Calculator to translate repeated inspection, review, reporting, and emergency coordination work into a first-pass business case. Then validate the estimate with pilot evidence before committing to a plant-wide rollout.
Common Risks and How to Reduce Them
Predictive maintenance projects usually fail for operational reasons, not because AI is impossible. The most common risks are manageable if they are addressed in the roadmap.
- Thin failure history: Start with anomaly detection, rules, and inspection recommendations while building labeled history.
- Bad asset IDs: Clean the asset hierarchy before connecting sensors, work orders, and ERP records.
- Alert fatigue: Use severity tiers, suppression windows, confidence scores, and owner-based queues.
- No action path: Connect every high-value alert to CMMS, part checks, planner review, and closure feedback.
- Model drift: Monitor model behavior when equipment, recipes, sensors, or operating conditions change.
- Security and access gaps: Separate control networks from analytics infrastructure and govern write-back permissions carefully.
- Unclear ownership: Assign owners across reliability, maintenance, IT, operations, and data teams before the pilot begins.
Next Steps for Manufacturing Teams
Start by selecting one asset group, one failure mode, and one maintenance decision that is worth improving. Then map the available data, the missing instrumentation, the systems involved, and the human approval path. A good pilot should be narrow, measurable, and integrated enough to prove whether predictive maintenance can change real maintenance behavior.
NextPage helps manufacturing teams turn predictive maintenance ideas into buildable software plans: data pipeline design, AI model strategy, dashboard development, CMMS/ERP/MES integration, and rollout governance. If you are planning a pilot, the useful first step is an AI predictive maintenance readiness checklist followed by a scoped implementation plan.