
Quick Answer: Machine Learning For Fintech Fraud Detection And Credit Risk
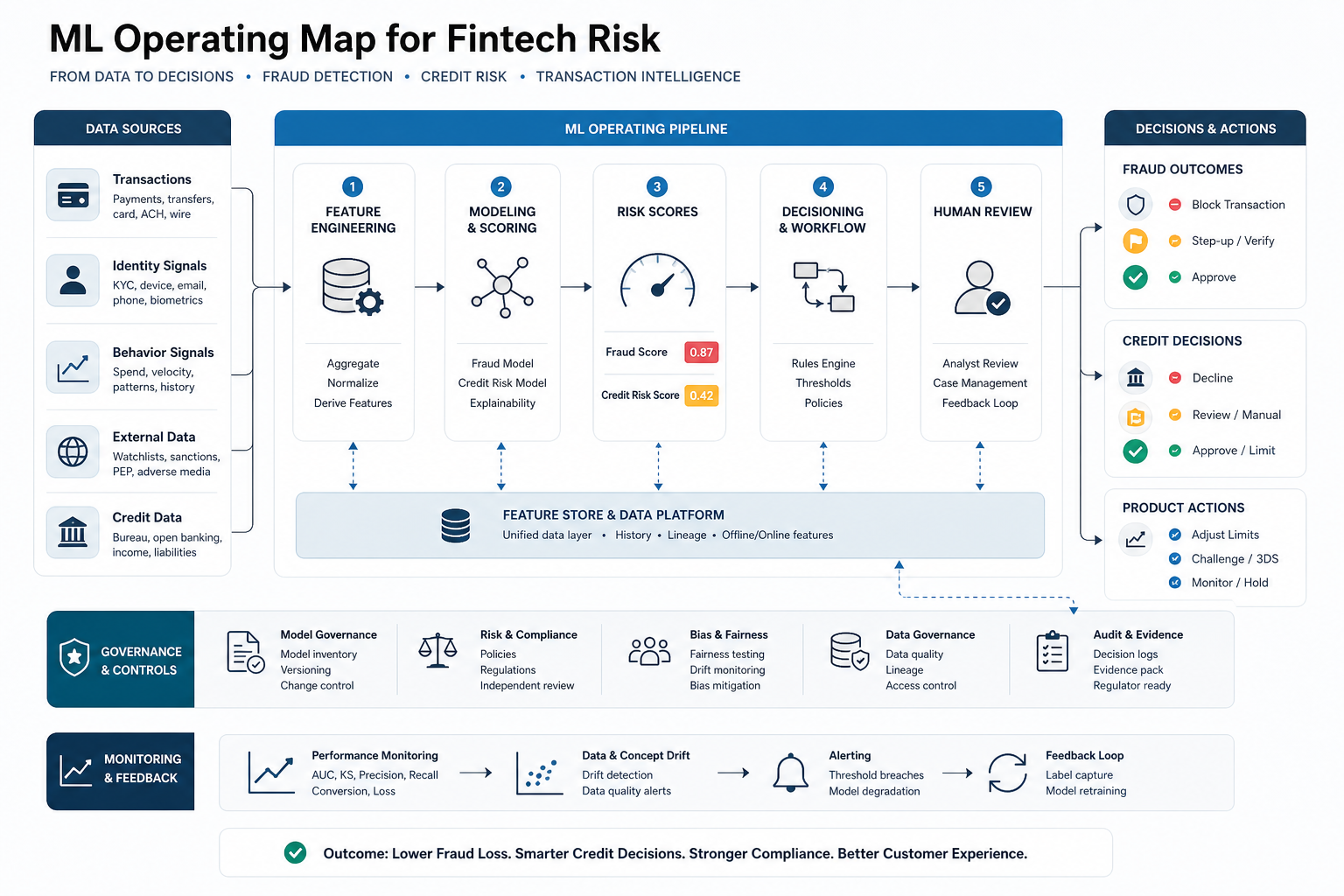
Machine learning for fintech fraud detection and credit risk works best when it is treated as a decision system, not just a prediction model. The useful product is a full operating loop: trusted data, features, model scoring, rules or policy overlays, human review, adverse-action or case evidence, monitoring, retraining, and a clear owner for every decision the system influences.
For fraud detection, ML can help spot transaction anomalies, synthetic identity patterns, account takeover behavior, mule activity, chargeback risk, and suspicious usage sequences faster than static rules alone. For credit risk, ML can support application scoring, affordability signals, early-warning indicators, portfolio monitoring, collections prioritization, and underwriting workflow triage. In both cases, the model should help risk teams make better decisions while preserving auditability and customer fairness. Teams in banking, lending, payments, or wealth workflows should connect the model roadmap to AI development services for banking and financial services so product, data, compliance, and operating controls are designed together.
The build-vs-buy decision depends on data maturity, regulatory exposure, product differentiation, and integration depth. Buy or use vendor APIs when the workflow is standard and speed matters. Build when proprietary transaction, identity, or repayment data creates a durable advantage. Use a hybrid approach when a vendor baseline handles common patterns but custom models, dashboards, and review workflows provide the risk edge. For adjacent product budgeting, the FinTech app development cost guide helps teams separate regulated product scope from the ML decision layer.
If you are still proving whether ML is justified, start with a narrow decision-support pilot and compare expected operational savings with the AI Automation ROI Calculator. If the product needs secure integration with your core systems, also model the broader platform budget with the Custom Software Cost Estimator.
Where ML Creates Value in Fintech Risk
The strongest fintech ML use cases share one trait: the team already has repeated decisions, measurable outcomes, and enough historical context to learn from. Fraud and credit risk fit that pattern because every transaction, onboarding event, repayment, dispute, manual review, and customer action can become signal when the data is reliable and legally usable.
The reference ML service page that inspired this queue item highlights fintech use cases including fraud detection, credit risk assessment, and transaction pattern analysis. That is a good starting point, but a fintech team needs to translate those broad use cases into operating decisions. A fraud model may score a card transaction, flag an account for stepped-up authentication, prioritize a review queue, or recommend a temporary limit. A credit model may recommend manual review, price a risk band, trigger document verification, or surface early delinquency risk.
Machine learning is especially useful when rules are either too broad or too brittle. Rules are still valuable for policy, compliance, hard blocks, thresholds, and known abuse patterns. ML adds value when behavior is high-dimensional, changes quickly, or depends on combinations of signals that are hard to maintain manually. NextPage usually frames this as narrow AI for a measurable business workflow, not as a generic AI transformation project.
Build vs Buy vs Hybrid Decision
Most fintech teams should not start by asking whether custom ML is more impressive. The better question is which option creates the most reliable risk decision with the least unmanaged exposure.

| Option | Best Fit | Main Advantage | Main Risk |
|---|---|---|---|
| Rules Engine | Known policies, hard thresholds, early MVP controls | Transparent and fast to launch | High false positives and manual maintenance as patterns evolve |
| Vendor API | Commodity identity, device, fraud, KYC, or bureau signals | Speed, benchmarks, and packaged operations | Limited customization, dependency, and unclear fit for proprietary workflows |
| Custom Model | Unique data, differentiated risk strategy, deep product integration | Control, proprietary learning, and workflow fit | Requires strong data, governance, monitoring, and ownership |
| Hybrid Model | Most growth-stage fintech risk stacks | Combines vendor signals, policy rules, and custom scoring | Needs careful orchestration and evidence across the whole decision chain |
A hybrid pattern is often the pragmatic middle ground. Vendor tools can provide identity checks, device fingerprinting, sanctions screening, document verification, or bureau attributes. Custom ML can then score the risk pattern that is specific to your product, customer segment, geography, transaction flow, or repayment behavior. This is where AI development services, machine learning development services, and product engineering need to work together rather than handing off a model as an isolated artifact. When the model must connect to customer portals, reviewer workbenches, dashboards, and core systems, treat it as secure custom software development, not a detached data-science experiment.
Data Readiness for Fraud and Credit Models
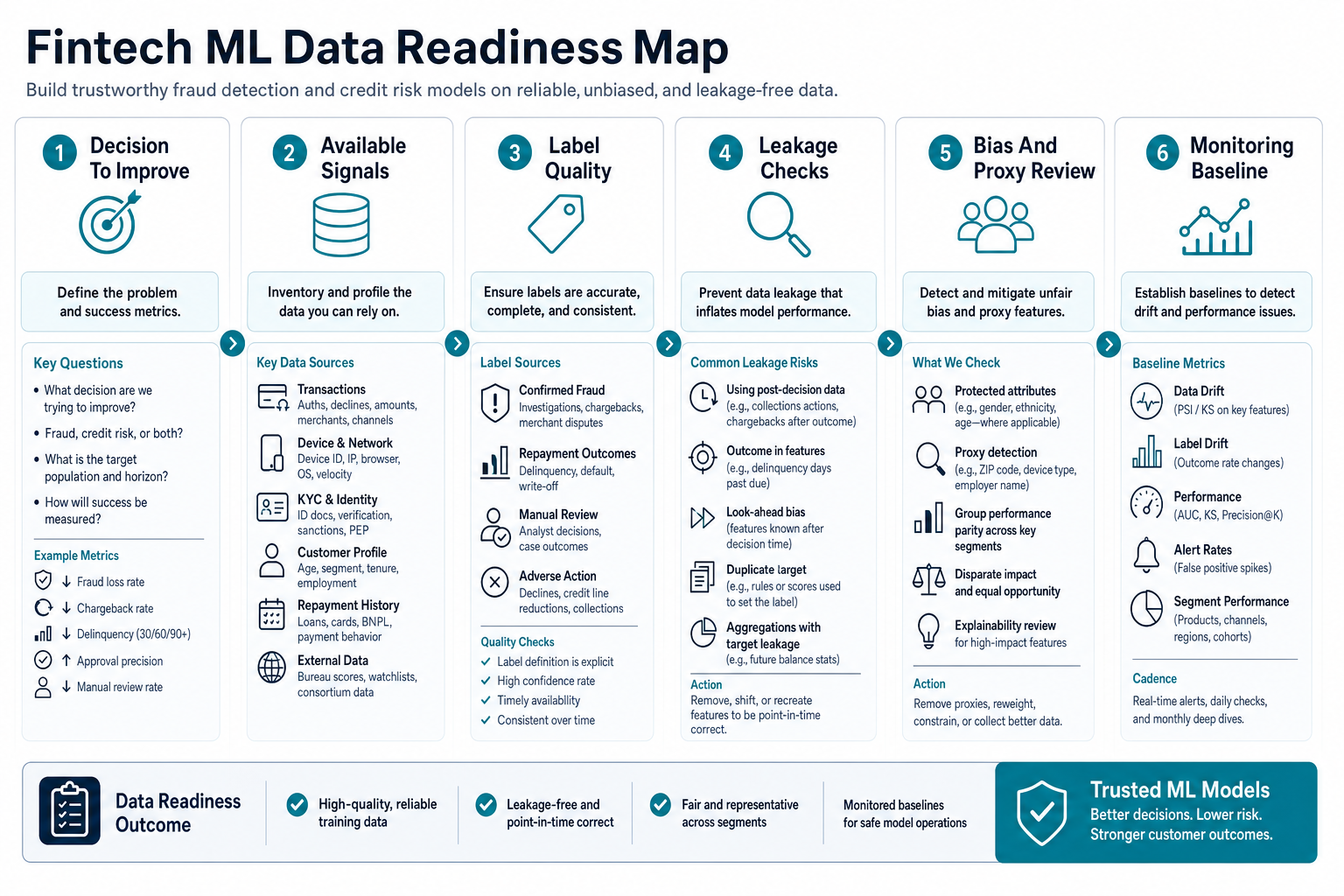
Data readiness is the real constraint in fintech ML. A useful fraud model may need transaction amount, merchant category, device, IP, geolocation, account age, velocity, payment instrument, chargeback history, login behavior, support history, and manual review outcomes. A credit risk model may need application data, bank-statement patterns, income evidence, repayment history, delinquency outcomes, bureau attributes, affordability signals, employment context, and policy decisions.
The data must also be usable. Teams need consent records, retention rules, lineage, stable identifiers, timestamp quality, missing-value handling, label definitions, leakage checks, and bias review. For example, a model trained on past manual decisions may learn old reviewer behavior rather than true risk. A model trained with post-decision data may look accurate in testing but fail in production because those signals are unavailable at decision time.
Before building a model, create a data-readiness checklist: decision to improve, outcome label, available signals at decision time, exclusions, protected-class and proxy-risk review, sample size, event delay, false-positive cost, false-negative cost, manual-review capacity, and rollback plan. The Machine Learning Consulting Company Checklist is useful here because the right partner should ask for baseline models, data quality evidence, and MLOps planning before promising advanced accuracy. The same data discipline appears in the AI visual inspection data labeling guide: weak labels and missing review loops break production AI even when the model demo looks strong.
Reference Architecture for a Fintech ML System
A fintech ML system usually has six layers. The first is source integration: core banking, payment processors, KYC tools, mobile apps, web apps, support systems, CRM, accounting, data warehouse, and event streams. The second is data preparation: cleaning, deduplication, entity resolution, feature computation, and label creation. The third is scoring: rules, vendor signals, model APIs, batch scoring, and real-time decision services.
The fourth layer is workflow: alerts, manual review queues, case management, customer messaging, limit changes, document requests, or adverse-action processes. The fifth is governance: approval records, version history, policy overlays, validation reports, audit logs, access control, and incident response. The sixth is monitoring: drift, false positives, false negatives, reviewer overrides, latency, data freshness, approval rates, loss rates, customer impact, and model decay.
Teams often underestimate the workflow and monitoring layers. The model can be technically strong and still fail if reviewers cannot understand why a case was flagged, if product teams cannot tune thresholds, or if operations cannot measure queue pressure. The Machine Learning Integration Roadmap is a useful companion because fintech ML must be embedded into product and operations, not left in a notebook. For operating workflows with queue pressure, SLA tracking, and reviewer decisions, the operational dashboard requirements checklist gives a practical way to define evidence, metrics, and escalation views.
Model Governance, Compliance, and Explainability
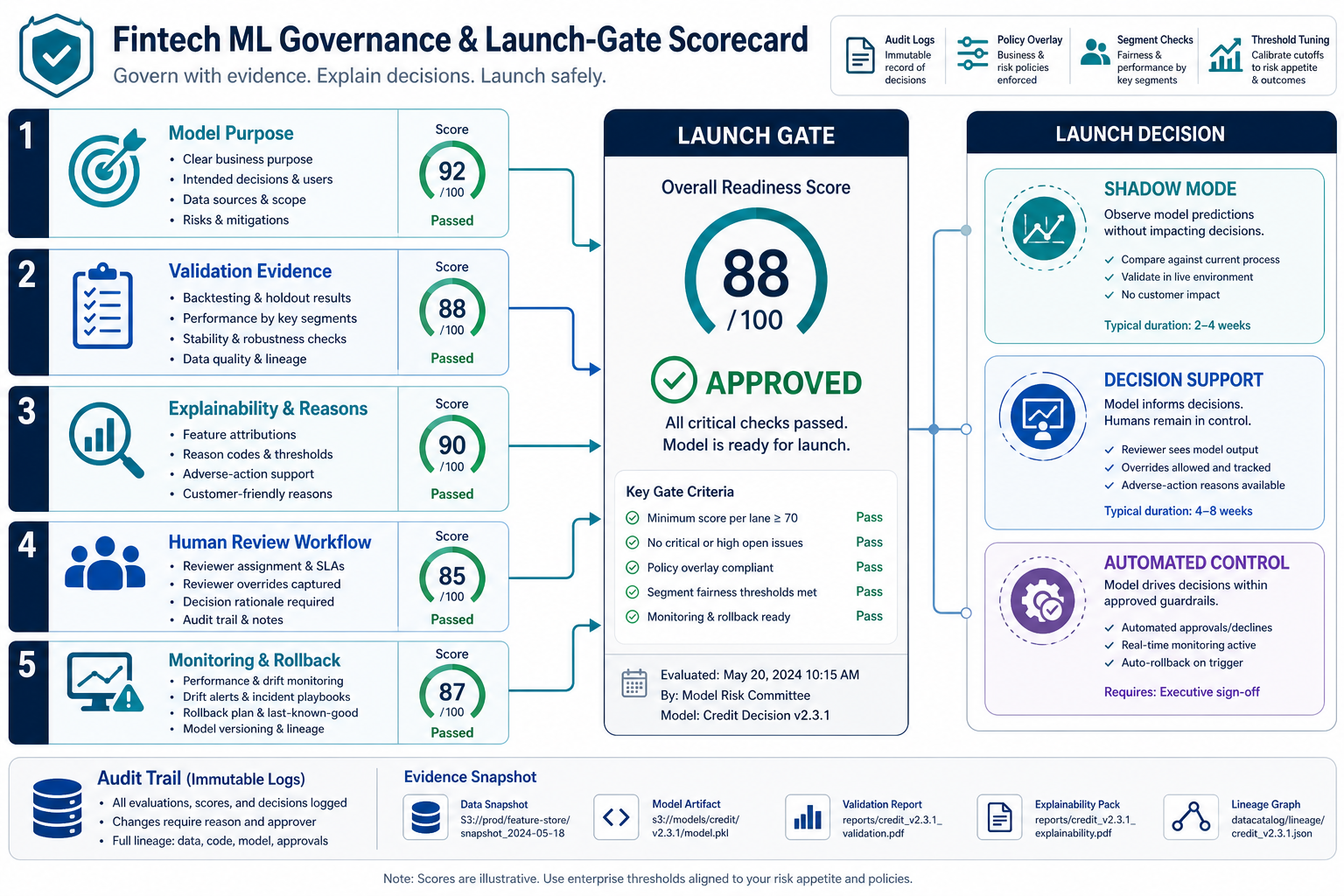
Fraud and credit models can affect customers directly, so governance is not optional. The CFPB has made clear that creditors using complex algorithms, including AI or ML, still need to provide specific and accurate adverse-action reasons when credit decisions trigger those obligations. That means a credit-risk model that cannot support reason codes, explainability, policy review, or appeal handling may be unsuitable no matter how accurate it looks in a sandbox.
Model risk management also matters. In April 2026, Federal Reserve SR 26-2 and OCC Bulletin 2026-13 replaced older SR 11-7 language with principles that still emphasize robust model development, implementation, validation, and governance while adding clearer treatment of AI and modern model inventories. For fintech teams, that translates into documented model purpose, assumptions, data sources, limitations, validation results, change approvals, monitoring thresholds, owner responsibilities, and independent review proportionate to the model risk. NIST AI RMF 1.0 adds a broader risk-management vocabulary around governing, mapping, measuring, and managing AI risks across the lifecycle.
Practical governance does not mean slowing every release to a crawl. It means making the risk explicit. For a fraud model used only to prioritize a review queue, governance may be lighter than for a model that blocks transactions automatically. For a credit model influencing approval, limit, or pricing decisions, explainability, fairness testing, adverse-action support, and compliance sign-off should be part of the launch gate.
For production ML operations, use an MLOps implementation checklist that covers model registry, deployment gates, reproducible training, monitoring, drift alerts, rollback, access control, and retraining cadence. Teams planning a broader regulated AI program can also use the EU AI Act readiness checklist as a governance prompt for data sources, documentation, evaluations, and lifecycle controls.
Fraud Detection Rollout Plan
A fraud rollout should begin in shadow mode. Score events without changing customer outcomes, compare predictions with rules and reviewer outcomes, then measure lift, latency, alert volume, and false positives. This gives the team a baseline before the model affects real users.
The next stage is decision support. Use the model to prioritize review queues, recommend step-up verification, or surface risk reasons for operations teams. Keep hard blocks under rules and policy until the team has enough evidence that automated action is justified. Track reviewer agreement, override reasons, customer complaints, and loss outcomes. If the pilot involves repeated review or triage labor, calculate reviewer time, escalation volume, and expected automation lift before funding production automation.
Only mature models should move into automated controls such as instant decline, account limitation, or transaction blocking. Even then, teams need customer support paths, rollback controls, incident response, threshold tuning, and weekly monitoring. Fraud patterns change quickly, so model performance must be reviewed against recent cohorts, not only historical backtests.
Credit Risk Rollout Plan
Credit-risk ML requires a stricter rollout because decisions may affect access to credit, price, limits, or account terms. Start with a clear decision boundary: application triage, manual review recommendation, affordability support, credit-line adjustment, early-warning monitoring, or collections prioritization. Do not let the model's scope expand informally.
Build a challenger model first. Compare it against existing policy rules, vendor scores, or underwriting outcomes without changing decisions. Measure approval impact, loss prediction, population stability, adverse-action reason support, protected-class proxy risk, and performance by segment. If the model is used in decisioning, align legal, compliance, risk, and product teams before launch.
Credit-risk teams should also decide how customers and internal users will understand the result. Explainability does not need to expose proprietary formulas, but the business must know the principal factors behind decisions, the operational meaning of a score, and what evidence is retained. This is one reason many teams choose hybrid models: policy rules preserve explicit controls while ML improves prioritization or risk ranking.
Team, Cost, and Timeline
A narrow fraud or credit-risk ML pilot often takes 8-12 weeks when data is accessible and the decision workflow is clear. A production decision-support system commonly takes 12-20 weeks because it adds integrations, review queues, dashboards, MLOps, security, and monitoring. A regulated credit-decision deployment may take 20-36 weeks or more because validation, compliance review, explainability, customer communications, and governance evidence must be built into the release.
| Phase | Typical Work | Output |
|---|---|---|
| Discovery | Use-case selection, decision mapping, data inventory, policy constraints, vendor review | ML opportunity brief, risk map, and build-vs-buy recommendation |
| Data And Baseline | Data extraction, feature design, label review, leakage checks, baseline model | Data-readiness report and measurable baseline |
| Pilot | Model training, evaluation, shadow scoring, dashboard, reviewer feedback | Evidence for lift, risk, false positives, and operating impact |
| Production | APIs, workflow integration, monitoring, model registry, security, rollback | Decision-support or automated-control release |
| Governance | Validation, documentation, explainability, approval workflow, audit evidence | Launch pack and ongoing model-risk process |
Cost depends less on the algorithm and more on integration depth, data cleanup, governance, and operational workflow. A lightweight decision-support pilot may be scoped like an analytics and ML sprint. A production fintech risk system behaves more like custom software development because it needs secure APIs, admin workflows, audit trails, and support processes. Estimate the surrounding product work separately when the ML model also requires new admin panels, case workflows, integrations, reporting, or customer-facing product changes.
How NextPage Plans Fintech ML Projects
NextPage plans fintech ML projects by mapping the decision first. We define the business decision, customer impact, regulatory exposure, data sources, existing rules, reviewer workflow, model owner, monitoring needs, and launch gate before choosing the model architecture. That keeps the project focused on risk reduction and operating value instead of model novelty. As an IT company in Mohali building software, AI, and digital products, NextPage can connect the model plan with the secure product, data, dashboard, and support surfaces around it.
For fraud detection, we usually start with transaction and account behavior, then design a safe pilot that reduces reviewer load or improves detection without surprising customers. For credit risk, we start with explainability, governance, and adverse-action implications before treating model accuracy as the only success metric. In both cases, the project needs data engineering, secure product integration, MLOps, dashboards, and operating playbooks.
If you are evaluating machine learning for fintech fraud detection, credit risk, or transaction monitoring, use a discovery sprint to compare rules, vendor APIs, custom ML, and hybrid options. The output should be a decision architecture, data-readiness assessment, pilot plan, governance checklist, and production roadmap tied to measurable risk outcomes. For a public example of field data capture, workflow evidence, and operations software around an AI-assisted process, review the ClearRoute portfolio case study.